- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Презентации по Математике

Вспомним: пересекающиеся и непересекающиеся прямые, перпендикулярные прямые Узнаем: какие прямые называются параллельными Будем учиться: распознавать параллельные прямые на чертежах Назовите линии. Выделите прямые

Повторение Назовите свойства площадей многоугольников 1. Равные многоугольники имеют равные площади 2. Если многоугольник составлен из нескольких многоугольников, то его площадь равна сумме площадей этих многоугольников 3. Площадь квадрата равна квадрату его стороны Повторение

Логическое следствие и проблема дедукции в логике высказываний А В означает, что из А лог. следует В. Т. 3.1. Если А В и В С , то А
Определение Тангенс определён для всех углов α, кроме тех, для которых косинус равен нулю Тангенсом угла α называют число, равное отношению sin α к cos α, обозначают tg α, т. е. Для любого угла α ≠ π/2 + πk, kЄZ существует,

Что такое data mining? Это процесс нетривиального извлечения новой, полезной и экстраполируемой информации из большого массива многомерных данных. Другими словами, это поиск структуры в данных. Исходные данные – совокупность численных векторов (измерений) Пример. Набор данных iris – 150 наблюдений,


МУНИЦИПАЛЬНОЕ БЮДЖЕТНОЕ ДОШКОЛЬНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ДЕТСКИЙ САД № 9 "СИНЯЯ ПТИЦА" КОМБИНИРОВАННОГО ВИДА г.о. ЖЕДЕЗНОДОРОЖНЫЙ Визитная карточка Теницкая Марина Степановна Воспитатель высшей категории Стаж работы17 лет
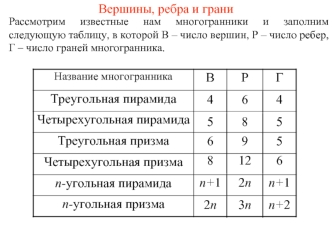
ТЕОРЕМА ЭЙЛЕРА Из приведенной таблицы непосредственно видно, что для всех выбранных многогранников имеет место равенство В - Р + Г = 2. Оказывается, что это равенство справедливо не только для рассмотренных многогранников, но и для произвольного выпуклого многогранника. Впервые это

Финансовый университет при Правительстве Российской Федерации Тема №1. Понятие множества Множеством можно назвать совокупность объектов, связанных между собой общими признаками. Обозначаются множества большими латинскими буквами: А, В, С и т.д.

Формула интегрирования по частям имеет вид Проблема состоит в том, что изначально все интегралы задаются в виде Методическое указание 1. Методическое указание 2.

Дифференциальные уравнения Колмогорова. Схема случайного процесса представляет собой ступенчатую кривую, на рис. изображен один из возможных вариантов реализаций процесса Для любого момента времени t вероятность состояний есть P1(t), P2(t), … Pi(t),… Pn(t) , при этом соблюдается условие нормировки

Для продолжения работы выбери необходимый раздел. Свойства прямоугольных треугольников Признаки равенства прямоугольных треугольников Проверь себя Прямоугольные треугольники Определение: Треугольник, в котором один угол

Классификация дифференциальных уравнений обыкновенные дифференциальные уравнения, содержащие одну независимую переменную и производные по ней; дифференциальные уравнения в частных производных, содержащие несколько независимых переменных и производные по ним. В зависимости от числа независимых переменных и, следовательно, типа входящих в них производных:


Необходимость систем уравнений 1 вопрос Составляющие систем уравнений

ПОВТОРЕНИЕ Что называют корнем степени n из числа b? Сколько существует корней нечетной степени из любого действительного числа? Каким будет являться корень нечетной степени из положительного числа? Из отрицательного числа? Из нуля? Сколько существует корней четной степени

Теория игр - Это математический метод оптимальных стратегий в играх. Пример 1: Пример 2: У игрока А бубновый и трефовый тузы и бубновая двойка. У игрока В бубновый и трефовый тузы и трефовая двойка, если выложены карты

Базовые процедуры Операции для векторов Сумма: q = v + w qx = vx + wx, qy = vy + wy Обозначим координаты вектора v=(vx,vy), w=(wx,wy), q=(qx,qy). Каждую точку плоскости можно считать вектором, начало которого находится

Доказательство. Рассмотрим криволинейную трапецию, ограниченную линией с основанием от 1 до

Отличительным свойством диссипативных ДС, описываемых системой обыкновенных дифференциальных уравнений является сжатие во времени элемента объема фазового пространства: В силу сжатия фазового объема предельное множество фазовых траекторий всегда

Кез келген үлгінің негізгі ерекшелігі - оның мүшелерінің арасында ауытқу болуы, осы өзгермелілік деңгейін өлшеу қажет болады. Көбінесе, осы мақсат үшін бірқатар бөліністердің амплитудасын көрсетіңіз - сериялардың шекаралары деп аталатын ең кіші және ең үлкен мәндер арасындағы айырмашылық. Серия шектерін салыстыру

Обработка многократно измеренных величин Исследование на нормальность: 1. Предварительные исследования (грубость, систематика – условия Ляпунова – основн. мат. условия) 2. Графические исследования – гистограмма, вероятностная бумага 3. Приближенные исследования (форма –ассиметрия, эксцесс – важно для тестирования) 4. Основные критерии

Теорема(о площади трапеции): П Площадь трапеции равна произведению полусуммы длин её оснований на высоту. \ Дано: ABCD – трапеция, BF⊥??, ?∈??,
Здесь, Вы можете изучить и скачать презентации из раздела Математика.