- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Закон больших чисел. Предельные теоремы презентация
Содержание
- 1. Закон больших чисел. Предельные теоремы
- 2. Повторение пройденного
- 3. Часть 1 - ГЛАВА 9. ЗАКОН БОЛЬШИХ ЧИСЕЛ. ПРЕДЕЛЬНЫЕ ТЕОРЕМЫ
- 4. При статистическом определении вероятности она трактуется как
- 5. При увеличении числа испытаний биномиальный закон стремится
- 6. 9.1. Неравенство Чебышева Пусть случайная величина ξ
- 8. 9.2. Закон больших чисел в форме
- 9. 9.2. Закон больших чисел в форме
- 10. 9.3. Теорема Бернулли Теорема: Рассмотрим схему Бернулли.
- 11. Доказательство: Случайная величина μn распределена по биномиальному закону, поэтому имеем
- 12. 9.4. Характеристические функции Характеристической функцией случайной величины
- 13. Для непрерывной случайной величины с плотностью распределения вероятности
- 15. 9.5. Центральная предельная теорема (теорема Ляпунова)
- 16. Повторили пройденное
- 17. ОСНОВЫ ТЕОРИИ ВЕРОЯТНОСТЕЙ И МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ ЧАСТЬ II. МАТЕМАТИЧЕСКАЯ СТАТИСТИКА
- 18. Эпиграф «Существует три вида лжи: ложь, наглая ложь и статистика» Бенджамин Дизраэли
- 19. Введение Две основные задачи математической статистики:
- 20. Методы статистического анализа данных: оценка неизвестной
- 21. ГЛАВА 1. ОСНОВНЫЕ ПОНЯТИЯ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
- 22. 1.1. Генеральная совокупность и выборка Генеральная совокупность
- 23. Выборка бывает повторной, когда каждый отобранный объект
- 24. Репрезентативная выборка: правильно представляет особенности генеральной совокупности,
- 25. Генеральная совокупность и выборка могут быть одномерными (однофакторными) и многомерными (многофакторными)
- 26. 1.2. Выборочный закон распределения (статистический ряд) Пусть
- 27. Разность xmax – xmin есть размах выборки,
- 28. Если мы запишем варианты в возраста-ющем порядке,
- 29. Если вариационный ряд состоит из очень большого
- 31. 1.3. Полигон частот, выборочная функция распределения Отложим
- 32. По аналогии с функцией распределения дискретной случайной
- 33. В отличие от функции
- 34. Заметим, что:
- 35. 1.4. Свойства эмпирической функции распределения Ступенчатый вид
- 36. Еще одним графическим представлением интересующей нас выборки
- 37. Пример
- 38. ГЛАВА 2. ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ ВЫБОРКИ
- 39. Задача математической статистики – по имеющейся
- 40. 2.1. Выборочное среднее и выборочная дисперсия, эмпирические
- 41. Выборочной дисперсией называется величина, равная Выборочным средним квадратическим отклонением –
- 42. Легко показать, что выполняется следующее соотношение, удобное для вычисления дисперсии:
- 43. Другими характеристиками вариационного ряда являются:
- 44. По аналогии с соответствующими теоретическими выражениями можно
- 45. По аналогии с моментами
- 46. 2.2. Свойства статистических оценок параметров распределения: несмещен-ность,
- 48. Статистическая оценка A* называется несмещенной, если ее
- 49. Разброс отдельных значений относительно среднего значения M[A*]
- 50. К статистическим оценкам предъявляется еще требование состоятельности.
- 51. 2.3. Свойства выборочного среднего Будем полагать, что
- 52. Несмещенность. Из свойств математического ожидания следует, что
- 53. Состоятельность. Пусть a – оцениваемый параметр, а
- 54. Таким образом, можно сделать вывод, что выборочное
- 56. ЛЕКЦИЯ 6
- 57. 2.4. Свойства выборочной дисперсии Исследуем несмещенность выборочной
- 60. Пример
- 62. ГЛАВА 3. ТОЧЕЧНОЕ ОЦЕНИВАНИЕ ПАРАМЕТРОВ ИЗВЕСТНОГО РАСПРЕДЕЛЕНИЯ
- 63. Будем считать, что общий вид закона распределения
- 64. 3.1. Метод моментов
- 65. Метод моментов, развитый Карлом Пирсоном в 1894
- 66. Можно показать, что оценки параметров θ,
- 67. Пример Известно, что характеристика
- 68. Напоминание α1 – мат.ожидание β2 - дисперсия
- 69. (*)
- 71. 3.2. Метод наибольшего правдоподобия В основе метода
- 72. Идея метода наибольшего правдоподобия состоит в том,
- 73. Оценки по методу максимального правдоподобия получаются из необходимого условия экстремума функции L(x1,x2,..., xn,θ) в точке
- 74. Примечания: 1. При поиске максимума функции правдоподобия
- 75. Пример Решение.
- 76. Отбросив в этой формуле слагаемое, которое не
- 77. ГЛАВА 4. ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ ПАРАМЕТРОВ ИЗВЕСТНОГО РАСПРЕДЕЛЕНИЯ
- 78. Задачу оценивания параметра известного распределения можно решать
- 79. (*)
- 80. 4.1. Оценивание математического ожидания нормально распределенной величины
- 81. Имеем: (1) (2)
- 82. (*) (*) (2) (1)
- 83. 4.2. Оценивание математического ожидания нормально распределенной величины при неизвестной дисперсии
- 84. Известно, что случайная величина tn, заданная таким
- 86. Плотность распределения Стьюдента c n – 1 степенями свободы
- 89. Примечание. При большом числе степеней свободы k
- 90. 4.3. Оценивание среднего квадратического отклонения
- 91. 4.3.1. Частный случай известного математического ожидания Пусть
- 92. Рассмотрим случайную величину Стоящие
- 93. Определим доверительный интервал из условия
- 97. 4.3.2. Частный случай неизвестного математического ожидания На
- 99. 4.4. Оценивание математического ожидания случайной величины для
- 100. Как и выше, будем рассматривать варианты x1,
- 101. Поэтому, если известно значение дисперсии случайной величины
- 103. Лекция 7
- 104. Повторение пройденного
- 105. ГЛАВА 4. ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ ПАРАМЕТРОВ ИЗВЕСТНОГО РАСПРЕДЕЛЕНИЯ
- 106. Задачу оценивания параметра известного распределения можно решать
- 107. (*)
- 108. 4.1. Оценивание математического ожидания нормально распределенной величины
- 109. Имеем: (1) (2)
- 110. (*) (*) (2) (1)
- 111. 4.2. Оценивание математического ожидания нормально распределенной величины при неизвестной дисперсии
- 112. Известно, что случайная величина tn, заданная таким
- 114. Плотность распределения Стьюдента c n – 1 степенями свободы
- 117. Примечание. При большом числе степеней свободы k
- 118. 4.3. Оценивание среднего квадратического отклонения
- 119. 4.3.1. Частный случай известного математического ожидания Пусть
- 120. Рассмотрим случайную величину Стоящие
- 121. Определим доверительный интервал из условия
- 125. 4.3.2. Частный случай неизвестного математического ожидания На
- 127. 4.4. Оценивание математического ожидания случайной величины для
- 128. Как и выше, будем рассматривать варианты x1,
- 129. Поэтому, если известно значение дисперсии случайной величины
- 130. Повторили пройденное
- 131. ГЛАВА 5. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
- 132. Статистической гипотезой называют гипотезу о виде неизвестного
- 133. Вероятность ошибки первого рода будем называть уровнем
- 135. 5.1. Проверка гипотез о параметрах известного распределения
- 136. В случае известной дисперсии D[ξ] = σ2,
- 143. 5.1.2. Сравнение дисперсий нормально распределенных случайных величин
- 144. Учитывая несмещенность исправленных выборочных дисперсий, нулевую гипотезу
- 145. Случайная величина F имеет распределение Фишера –
- 148. 5.1.3. Сравнение математических ожиданий независимых случайных величин
- 149. Введем случайные величины
- 153. 5.2. Проверка гипотез о виде закона распределения
- 154. Известно несколько критериев согласия. Достоинством критерия Пирсона
- 155. 5.2.1. Проверка гипотезы о нормальном распределении Пусть
- 159. ГЛАВА 6. ВАЖНЕЙШИЕ РАСПРЕДЕЛЕНИЯ И ИХ КВАНТИЛИ
- 160. 6.1. Нормальное распределение По определению нормально распределенная
- 161. Квантилью порядка α (0 < α <
- 162. 6.2. Распределение Стьюдента Если
- 167. 6.3. Распределение χ2 Если ξ1, ξ2, …,
- 172. ГЛАВА 7. ПРИМЕР СТАТИСТИЧЕСКОЙ ОБРАБОТКИ ВЫБОРКИ
- 173. Будем считать максимальную дневную температуру в Санкт-Петербурге
- 179. Конец



Слайд 4При статистическом определении вероятности она трактуется как некоторое число, к которому

Слайд 5При увеличении числа испытаний биномиальный закон стремится к нормальному распределению. Это
Закон больших чисел и центральная предельная теорема лежат в основании математической статистики.

Слайд 69.1. Неравенство Чебышева
Пусть случайная величина ξ имеет конечные математическое ожидание M[ξ]

Слайд 7
Для противоположного события:
Неравенство Чебышева справедливо для любого закона распределения.
Положив , получаем нетривиальный факт:

Слайд 89.2. Закон больших чисел
в форме Чебышева
Теорема Пусть случайные величины
Таким образом, закон больших чисел говорит о сходимости по вероятности среднего арифметиче-ского случайных величин (т. е. случайной величины) к среднему арифметическому их мат. ожиданий (т. е. к не случайной величине).

Слайд 99.2. Закон больших чисел
в форме Чебышева: дополнение
Теорема (Маркова): закон больших
: закон больших чисел выполняется, если дисперсия")
Слайд 109.3. Теорема Бернулли
Теорема: Рассмотрим схему Бернулли. Пусть μn – число наступлений
Т.е. вероятность того, что отклонение относительной частоты случайного события от его вероятности р будет по модулю сколь угодно мало, оно стремится к единице с ростом числа испытаний n.


Слайд 129.4. Характеристические функции
Характеристической функцией случайной величины называется функция
где exp(x)
Таким образом, представляет собой математическое ожидание некоторой комплексной случайной величины связанной с величиной . В частности, если – дискретная случайная величина, заданная рядом распределения {xi, pi}, где i = 1, 2,..., n, то
 = ex.Таким образом,")


")



Слайд 19 Введение
Две основные задачи математической статистики:
сбор и группировка статистических данных;
разработка методов анализа полученных данных в зависимости от целей исследования.

Слайд 20Методы статистического анализа данных:
оценка неизвестной вероятности события;
оценка неизвестной функции распределения;
оценка
проверка статистических гипотез о виде неизвестного распределения или о значениях параметров известного распределения.


Слайд 221.1. Генеральная совокупность и выборка
Генеральная совокупность - все множество исследуемых объектов,
Объем генеральной совокупности и объем выборки - число объектов в гене-ральной совокупности и выборке - будем обозначать соответственно как N и n.

Слайд 23Выборка бывает повторной, когда каждый отобранный объект перед выбором следующего возвращается

Слайд 24Репрезентативная выборка:
правильно представляет особенности генеральной совокупности, т.е. является репрезентативной (представительной).
По
1) объем выборки n достаточно большой;
2) каждый объект выборки выбран случайно;
3) для каждого объекта вероятность попасть в выборку одинакова.
. По закону больших чисел, можно")
Слайд 25Генеральная совокупность и выборка могут быть одномерными (однофакторными)
и многомерными (многофакторными)
 и многомерными (многофакторными)")
Слайд 261.2. Выборочный закон распределения
(статистический ряд)
Пусть в выборке объемом n интересующая нас
Пусть в выборке объемом n интересующая нас случайная величина ξ")
Слайд 27Разность xmax – xmin есть размах выборки, отношение ωi = ni
Очевидно, что

Слайд 28Если мы запишем варианты в возраста-ющем порядке, то получим вариацион-ный ряд.
-- Аналог закона распределения дискретной случайной величины в теории вероятности

Слайд 29Если вариационный ряд состоит из очень большого количества чисел или исследуется

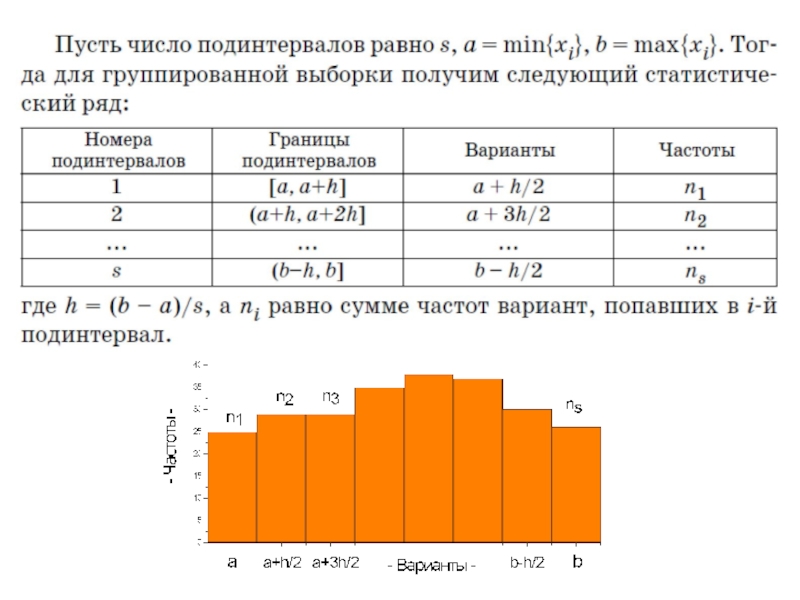
Слайд 311.3. Полигон частот,
выборочная функция распределения
Отложим значения случайной величины xi по оси

Слайд 32По аналогии с функцией распределения дискретной случайной величины по выборочному закону
где суммирование выполняется по всем частотам, которым соответствуют значения вариант, меньшие x. Заметим, что эмпирическая функция распределения зависит от объема выборки n.

Слайд 33В отличие от функции ,найденной для



Слайд 36Еще одним графическим представлением интересующей нас выборки является гистограмма – ступенчатая
В первом случае площадь гистограм- мы равна объему выборки n, во втором – единице



Слайд 39Задача математической статистики – по имеющейся выборке получить информацию о

Слайд 402.1. Выборочное среднее и выборочная дисперсия, эмпирические моменты
Выборочным средним называется среднее
Выборочное среднее используется для статистической оценки математического ожидания исследуемой случайной величины.

Слайд 41Выборочной дисперсией называется величина, равная
Выборочным средним квадратическим отклонением –


Слайд 43Другими характеристиками вариационного ряда являются: мода M0
2, 5, 2, 11, 5, 6, 3, 13, 5 (мода = 5)
2, 2, 3, 5, 5, 5, 6, 11,13 (медиана = 5)

Слайд 44По аналогии с соответствующими теоретическими выражениями можно построить эмпирические моменты, применяемые

Слайд 45По аналогии с моментами
центральным эмпирическим моментом порядка m -

Слайд 462.2. Свойства статистических оценок параметров распределения: несмещен-ность, эффективность, состоятельность
После получения статистических
Найдем условия, которые должны для этого выполняться.


Слайд 48Статистическая оценка A* называется несмещенной, если ее математическое ожидание равно оцениваемому
Если это условие не выполняется, оценка называется смещенной.
Несмещенность оценки не является достаточным условием хорошего приближения статистической оценки A* к истинному (теоретическому) значению оцениваемого параметра A.

Слайд 49Разброс отдельных значений относительно среднего значения M[A*] зависит от величины дисперсии

Слайд 50К статистическим оценкам предъявляется еще требование состоятельности. Оценка называется состоятельной, если

Слайд 512.3. Свойства выборочного среднего
Будем полагать, что варианты x1, x2,..., xn являются

Слайд 52Несмещенность. Из свойств математического ожидания следует, что
т.е. выборочное среднее является несмещенной
Можно также показать эффективность оценки по выборочному среднему матема-тического ожидания (для нормального распределения)

Слайд 53Состоятельность. Пусть a – оцениваемый параметр, а именно математическое ожидание генеральной
У нас:
тогда . При n → правая часть неравенства стремится к нулю для лю-
бого ε > 0, т.е.
и, следовательно, величина X, представляющая выборочную оценку, стремится к оцениваемому параметру a по вероятности.

Слайд 54Таким образом, можно сделать вывод, что выборочное среднее является несмещенной, эффективной



Слайд 572.4. Свойства выборочной дисперсии
Исследуем несмещенность выборочной дисперсии D* как оценки дисперсии



Слайд 60 Пример
Найти выборочное среднее, выборочную дисперсию
Решение:



Слайд 63Будем считать, что общий вид закона распределения нам известен и остается


Слайд 65Метод моментов, развитый Карлом Пирсоном в 1894 г., основан на использовании

Слайд 66Можно показать, что оценки параметров θ, полученные методом моментов, состоятельны,

Слайд 67 Пример
Известно, что характеристика ξ объектов генеральной совокупности, являясь
Требуется определить методом моментов параметры a и b по известному выборочному среднему и выборочной дисперсии


")

Слайд 713.2. Метод наибольшего правдоподобия
В основе метода лежит функция правдоподобия L(x1, x2,...,
, являющаяся законом")
Слайд 72Идея метода наибольшего правдоподобия состоит в том, что мы ищем такие

Слайд 73Оценки по методу максимального правдоподобия получаются из необходимого условия экстремума функции
 в точке")
Слайд 74Примечания:
1. При поиске максимума функции правдоподобия для упрощения расчетов можно выполнить
2. Оценки параметров, рассмотренные нами, можно назвать точечными оценками, так как для неизвестного параметра θ определяется одна единственная точка , являющаяся его приближенным значением. Однако такой подход может приводить к грубым ошибкам, и точечная оценка может значительно отличаться от истинного значения оцениваемого параметра (особенно в случае выборки малого объема).

Слайд 75 Пример
Решение. В данной задаче следует оценить
Логарифмическая функция правдоподобия имеет вид

Слайд 76Отбросив в этой формуле слагаемое, которое не зависит от a и
Решая, получаем:


Слайд 78Задачу оценивания параметра известного распределения можно решать путем построения интервала, в
Обычно в математике для оценки параметра θ строится неравенство
где число δ характеризует точность оценки: чем меньше δ, тем лучше оценка.
(*)

")
Слайд 804.1. Оценивание математического ожидания нормально распределенной величины при известной дисперсии
Пусть исследуемая
Как и ранее, будем рассматривать получаемое выборочное среднее как значение случайной величины , а значения вариант выборки x1, x2, …, xn – соответственно как значения одинаково распределенных независимых случайных величин , каждая из которых имеет мат. ожи-дание a и среднее квадратическое отклонение σ.

(2)")
(*)(2)(1)")
Слайд 834.2. Оценивание математического ожидания нормально распределенной величины при неизвестной дисперсии

Слайд 84Известно, что случайная величина tn, заданная таким образом, имеет распределение Стьюдента





Слайд 89Примечание. При большом числе степеней свободы k распределение Стьюдента стремится к

Слайд 904.3. Оценивание среднего квадратического отклонения
нормально распределенной величины
Пусть исследуемая случайная
Рассмотрим два случая: с известным и неизвестным математическим ожиданием.

Слайд 914.3.1. Частный случай известного
математического ожидания
Пусть известно значение M[ξ] = a и
Используя величины , определенные выше, введем случайную величину Y, принимающую значения выборочной дисперсии D*:

Слайд 92Рассмотрим случайную величину
Стоящие под знаком суммы случайные величины

Слайд 93Определим доверительный интервал из условия
где




Слайд 974.3.2. Частный случай неизвестного
математического ожидания
На практике чаще всего встречается ситуация, когда
В этом случае построение доверительного интервала основывается на теореме Фишера, из
кот. следует, что случайная величина
(где случайная величина )
принимающая значения несмещенной выборочной дисперсии s2, имеет распределение χ2 с n–1 степенями свободы.


Слайд 994.4. Оценивание математического ожидания случайной
величины для произвольной выборки
Интервальные оценки математического ожидания

Слайд 100Как и выше, будем рассматривать варианты x1, x2,..., xn как значения
Согласно центральной предельной теореме величина имеет асимптотически нормальный закон распределения c математическим ожиданием mξ и дисперсией .

Слайд 101Поэтому, если известно значение дисперсии случайной величины ξ, то можно пользоваться
Если же значение дисперсии величины ξ неизвестно, то при больших n можно использовать формулу
где s – исправленное ср.-кв. отклонение





Слайд 106Задачу оценивания параметра известного распределения можно решать путем построения интервала, в
Обычно в математике для оценки параметра θ строится неравенство
где число δ характеризует точность оценки: чем меньше δ, тем лучше оценка.
(*)

")
Слайд 1084.1. Оценивание математического ожидания нормально распределенной величины при известной дисперсии
Пусть исследуемая
Как и ранее, будем рассматривать получаемое выборочное среднее как значение случайной величины , а значения вариант выборки x1, x2, …, xn – соответственно как значения одинаково распределенных независимых случайных величин , каждая из которых имеет мат. ожи-дание a и среднее квадратическое отклонение σ.

(2)")
(*)(2)(1)")
Слайд 1114.2. Оценивание математического ожидания нормально распределенной величины при неизвестной дисперсии

Слайд 112Известно, что случайная величина tn, заданная таким образом, имеет распределение Стьюдента





Слайд 117Примечание. При большом числе степеней свободы k распределение Стьюдента стремится к

Слайд 1184.3. Оценивание среднего квадратического отклонения
нормально распределенной величины
Пусть исследуемая случайная
Рассмотрим два случая: с известным и неизвестным математическим ожиданием.

Слайд 1194.3.1. Частный случай известного
математического ожидания
Пусть известно значение M[ξ] = a и
Используя величины , определенные выше, введем случайную величину Y, принимающую значения выборочной дисперсии D*:

Слайд 120Рассмотрим случайную величину
Стоящие под знаком суммы случайные величины

Слайд 121Определим доверительный интервал из условия
где




Слайд 1254.3.2. Частный случай неизвестного
математического ожидания
На практике чаще всего встречается ситуация, когда
В этом случае построение доверительного интервала основывается на теореме Фишера, из
кот. следует, что случайная величина
(где случайная величина )
принимающая значения несмещенной выборочной дисперсии s2, имеет распределение χ2 с n–1 степенями свободы.


Слайд 1274.4. Оценивание математического ожидания случайной
величины для произвольной выборки
Интервальные оценки математического ожидания

Слайд 128Как и выше, будем рассматривать варианты x1, x2,..., xn как значения
Согласно центральной предельной теореме величина имеет асимптотически нормальный закон распределения c математическим ожиданием mξ и дисперсией .

Слайд 129Поэтому, если известно значение дисперсии случайной величины ξ, то можно пользоваться
Если же значение дисперсии величины ξ неизвестно, то при больших n можно использовать формулу
где s – исправленное ср.-кв. отклонение



Слайд 132Статистической гипотезой называют гипотезу о виде неизвестного распределения или о параметрах
Проверяемая гипотеза, обозначаемая обычно как H0, называется нулевой или основной гипотезы. Дополнительно используемая гипотеза H1, противоречащая гипотезе H0, называется конкурирующей или альтернативной.
Статистическая проверка выдвинутой нулевой гипотезы H0 состоит в ее сопоставлении с выборочными данными. При такой проверке возможно появление ошибок двух видов:
а) ошибки первого рода – случаи, когда отвергается правильная гипотеза H0;
б) ошибки второго рода – случаи, когда принимается неверная гипотеза H0.

Слайд 133Вероятность ошибки первого рода будем называть уровнем значимости и обозначать как
Основной прием проверки статистических гипотез заключается в том, что по имеющейся выборке вычисляется значение статистического критерия – некоторой случайной величины T, имеющей известный закон распределения. Область значений T, при которых основная гипотеза H0 должна быть отвергнута, называют критической, а область значений T, при которых эту гипотезу можно принять, – областью принятия гипотезы.


Слайд 1355.1. Проверка гипотез о параметрах известного распределения
5.1.1. Проверка гипотезы о математическом
Пусть случайная величина ξ имеет нормальное распределение.
Требуется проверить предположение о том, что ее математическое ожидание равно некоторому числу a0. Рассмотрим отдельно случаи, когда дисперсия ξ известна и когда она неизвестна.

Слайд 136В случае известной дисперсии D[ξ] = σ2, как и в п.







Слайд 1435.1.2. Сравнение дисперсий нормально
распределенных случайных величин
Пусть имеются две нормально распределенные случайные

Слайд 144Учитывая несмещенность исправленных выборочных дисперсий, нулевую гипотезу можно записать следующим образом:
где
принимает значения исправленной выборочной дисперсии величины ξ и аналогична случайной величине Z, рассмотренной в п. 4.2.
В качестве статистического критерия выберем случайную величину
принимающую значение отношения бóльшей выборочной дисперсии к меньшей.

Слайд 145Случайная величина F имеет распределение Фишера – Снедекора с числом степеней
Рассмотрим два вида конкурирующих гипотез



Слайд 1485.1.3. Сравнение математических ожиданий независимых случайных величин
Сначала рассмотрим случай нормального распределения
Пусть случайные величины ξ1 и ξ2 независимы и распределены нормально, и пусть их дисперсии D[ξ1] и D[ξ2] известны. (Например, они могут быть найдены из какого-то другого опыта или рассчитаны теоретически). Извлечены выборки объемом n1 и n2 соответственно. Пусть – выборочные средние для этих выборок. Требуется по выборочным средним при заданном уровне значимости α проверить гипотезу о равенстве математических ожиданий рассматриваемых случайных величин

Слайд 149Введем случайные величины ,
В качестве статистического критерия для проверки H0 возьмем случайную величину




Слайд 1535.2. Проверка гипотез о виде закона распределения случайной величины. Критерий Пирсона
Надежное
Статистические критерии, предназначенные для таких проверок, обычно называются критериями согласия.

Слайд 154Известно несколько критериев согласия. Достоинством критерия Пирсона является его универсальность. С
Критерий Пирсона основан на сравнении частот, найденных по выборке (эмпирических частот), с частотами, рассчитанными с помощью проверяемого закона распределения (теоретическими частотами).
Обычно эмпирические и теоретические частоты различаются. Следует выяснить, случайно ли расхождение частот или оно значимо и объясняется тем, что теоретические частоты вычислены исходя из неверной гипотезы о распределении генеральной совокупности.
Критерий Пирсона, как и любой другой, отвечает на вопрос, есть ли согласие выдвинутой гипотезы с эмпирическими данными при заданном уровне значимости.

Слайд 1555.2.1. Проверка гипотезы
о нормальном распределении
Пусть имеется случайная величина ξ и сделана
Для удобства обработки выборки возьмем два числа α и β: и разделим интервал [α, β] на s подинтервалов. Будем считать, что значения вариант, попавших в каждый подинтервал,приближенно равны числу, задающему середину подинтервала. Подсчитав число вариант, попавших в каждый интервал, составим группированную выборку с вариантами: x1, x2, …, xs и их частотами n1, n2, …, ns, где xj = (bj + aj)/2 – середина j-го подинтервала (aj, bj]; nj – количество вариант, попавших в этот подинтервал, т.е. эмпирическая частота.





Слайд 1606.1. Нормальное распределение
По определению нормально распределенная случайная величина ξ имеет плотность
где a и σ являются параметрами.

Слайд 161Квантилью порядка α (0 < α < 1) непрерывной случайной величины
Квантиль x½ называется медианой случайной величины ξ, квантили x¼ и x¾ – ее квартилями, a x0,1, x0,2,..., x0,9 – децилями.
Для стандартного нормального распределения (a = 0, σ = 1) и, следовательно,
где FN (x, a, σ) – функция распределения нормально распределенной случайной величины, а Φ(x) – функция Лапласа.
Квантиль стандартного нормального распределения xα для заданного α можно найти из соотношения
 непрерывной случайной величины ξ называется такое число")
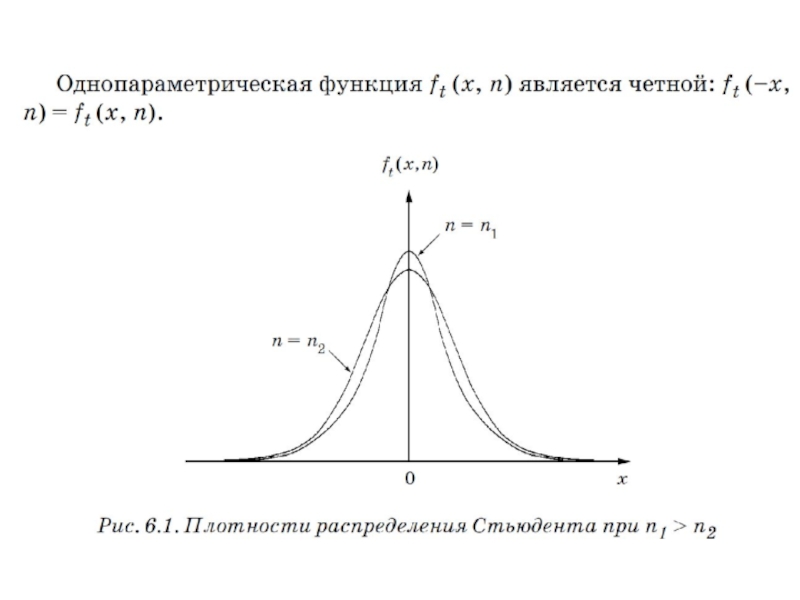
Слайд 1626.2. Распределение Стьюдента
Если
называют распределением Стьюдента с n степенями свободы (W.S. Gosset).




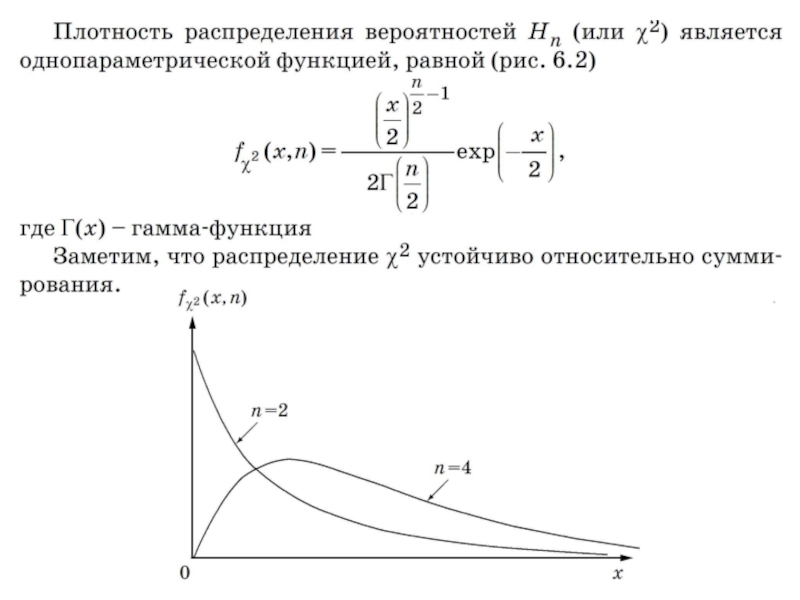
Слайд 1676.3. Распределение χ2
Если ξ1, ξ2, …, ξn – независимые случайные величины,
называют распределением χ2 с n степенями свободы. Обычно и для самой случайной величины Hn используется тот же символ, т.е. вместо Hn пишут χ2.





Слайд 173Будем считать максимальную дневную температуру в Санкт-Петербурге 1 сентября случайной величиной
Рассмотрим некоторые задачи, на которые разбивается статистическая обработка выборки, направленная на определение свойств данной случайной величины