технических средств, служащих для автоматизированной обработки дискретных данных по заданному алгоритму.
Алгоритм – одно из фундаментальных понятий математики и вычислительной техники. Международная организация стандартов (ISO) формулирует понятие алгоритм как «конечный набор предписаний, определяющий решение задачи посредством конечного количества операций»
- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Концепция машины с хранимой в памяти программой. (Тема 2) презентация
Содержание
- 1. Концепция машины с хранимой в памяти программой. (Тема 2)
- 2. Основными свойствами алгоритма являются: дискретность, определенность, массовость
- 3. Массовость алгоритма подразумевает его применимость к множеству
- 4. В основе архитектуры современных ВМ лежит представление
- 5. Сущность фон-неймановской концепции вычислительной машины можно свести
- 6. Согласно принципу двоичного кодирования, вся информация, как
- 7. Код операции представляет собой указание, какая операция
- 8. Принцип программного управления Все вычисления, предусмотренные
- 9. Принцип однородности памяти Команды и данные хранятся
- 10. Концепция вычислительной машины, изложенная в статье фон
- 11. Принцип адресности Структурно основная память состоит из
- 12. Фон-неймановская архитектура
- 13. Фон Неймана определил основные устройства ВМ, с
- 14. Введенная информация сначала запоминается в основной памяти,
- 15. Для таких ЗУ характерна энергозависимость – хранимая
- 16. Для долговременного хранения больших программ и массивов
- 17. Устройство управления (УУ) – важнейшая часть ВМ,
- 18. Пересылка информации между любыми элементами ВМ инициируется
- 19. Еще одной неотъемлемой частью ВМ является арифметико-логическое
- 20. Флаги могут анализироваться в УУ с целью
- 21. Классификация архитектур По структуре вычислительных машин
- 22. В настоящее время примерно одинаковое распространение получили
- 23. Структура фон-неймановской вычислительной машины
- 24. У фон-неймановских ВМ таким «узким местом» является
- 25. Структура вычислительной машины на базе общей шины
- 26. Благодаря этим свойствам шинная архитектура получила широкое
- 27. В целом, при сохранении фон-неймановской концепции последовательного
- 28. Структура с одной шиной
- 29. Структура с двумя видами шин
- 30. Структура с многими видами шин
- 31. Классификация архитектур По системам команд
- 32. Системой команд вычислительной машины называют полный перечень
- 34. Стековая архитектура Стеком называется память, по
- 35. Принцип действия стековой памяти
- 36. Верхнюю ячейку называют вершиной стека. Для работы
- 37. Архитектура вычислительной машины на базе стека
- 38. Для выполнения арифметической или логической операции на
- 39. К достоинствам АСК на базе стека следует
- 40. Аккумуляторная архитектура Архитектура на базе аккумулятора исторически
- 41. Архитектура ВМ на базе аккумулятора.
- 42. Для выполнения операции в АЛУ производится считывание
- 43. Регистровая архитектура В машинах данного типа процессор
- 44. RISC-архитектура предполагает использование существенно большего числа РОН
- 45. В варианте «регистр-регистр» операнды могут находиться только
- 46. К достоинствам регистровых АСК следует отнести: компактность
- 47. Архитектура с выделенным доступом к памяти В
- 48. В архитектуре отсутствуют команды обработки, допускающие прямое
- 49. Классификация по составу и сложности команд
- 50. Пытаясь преодолеть семантический разрыв, разработчики вычислительных машин
- 51. В вычислительных машинах типа CISC проблема семантического
- 52. К типу CISC можно отнести практически все
- 53. Термин RISC впервые был использован Д. Паттерсоном
- 54. Элементы RISC-архитектуры впервые появились в вычислительных машинах
- 55. Помимо CISC- и RISC-архитектур в общей классификации
- 56. Основные направления в развитии архитектур процессоров
- 57. Конвейер команд Идея конвейера команд была
- 58. 3. Вычисление адресов операндов (ВА). Вычисление исполнительных
- 59. Логика работы конвейера команд
- 60. На рисунке показан конвейер с шестью ступенями,
- 61. Суперконвейер Разбиение каждой ступени конвейера на n
- 63. Каждая из шести ступеней стандартного конвейера разбита
- 64. Структурный риск - попытка нескольких команд одновременно
- 65. Структурный риск имеет место, когда несколько команд,
- 66. «Чтение после записи» (ЧПЗ): команда j читает
- 67. Для решения этих проблем применяют предвыборку команд
- 68. Влияние условного перехода на работу конвейера команд
- 69. Пусть команда 3 – это условный переход
- 70. Статическое предсказание переходов. Динамическое предсказание переходов. Классификации схем предсказания переходов
- 71. Переход происходит всегда. Переход не происходит никогда.
- 72. Предполагается, что каждая команда условного перехода в
- 73. Предполагается, что ни одна из команд условного
- 74. По результатам профилирования, тем командам, которые чаще
- 75. Для одних команд предполагается, что переход произойдет,
- 76. Одноуровневые или бимодальные. Двухуровневые или коррелированные. Гибридные.
- 77. Одноуровневые схемы предсказания переходов Идея
- 78. Предсказание осуществляется на основе предыдущих исходов как
- 79. Гибридные схемы объединяют в себе несколько различных
- 80. Асимметричная схема сочетает в себе черты
- 81. Суперскалярность Суперскалярным (этот термин впервые был
- 82. Архитектура суперскалярного процессора
- 83. Блок выборки команд извлекает команды из основной
- 84. Каждый накопитель команд связан со своим функциональным
- 85. Эта операция называется выдачей команд. Блок распределения
- 89. БФА - блок формирования адреса БРЗ -
- 90. Hyper-threading ( Hyper-threading — Гиперпоточность) В процессорах
- 91. Потоки С точки зрения процессора, поток –
- 92. Развитие микропроцессоров CMP (Chip Multi Processing -многоядерность
- 93. Направление CMP Создание на одном кристалле нескольких
- 94. Направление SMT На одном процессоре осуществляется
- 95. Архитектура EPIC На входе процессора последовательность больших
- 96. Недостатки Значительно усложняются компиляторы Производительность микропроцессора во многом определяется качеством компилятора Увеличивается сложность отладки
- 97. Развитие микропроцессоров на примере линейки микропроцессоров X86 фирмы Intel
- 99. Архитектура Pentium M Мобильная версия RISC
- 100. Архитектура Intel Core Conroe - настольные ПК
- 103. Основные особенности архитектуры Intel Core Технология
- 104. Технология широкого динамического выполнения Призвана обеспечить выполнение
- 109. Интеллектуальная система управления энергопотреблением Технологии стробирования тактовых
- 111. Улучшенный "умный" кэш Два ядра совместно используют
- 113. "Умный" доступ к памяти Улучшенная предварительная выборка
- 114. "Умный" доступ к памяти Улучшенная предварительная выборка
- 115. "Умный" доступ к памяти Устранение неоднозначностей памяти
- 118. Улучшенная работа с цифровым медиа-содержанием АЛУ обычно
- 121. Архитектура Core i3 - i7 Основной
- 122. Прочие блоки могут быть следующими: разделяемый кэш
- 123. Core i3 Компания Intel разработала в 2006
- 125. Core i3 Самое основное отличие новых процессоров
- 127. ТЕХНОЛОГИИ CORE i3 Новая улучшенная версия Hyper-threading
- 129. ТЕХНОЛОГИИ CORE i3 Для слежения за состоянием
- 130. ТЕХНОЛОГИИ CORE i3 Линейка процессоров Core i3,
- 131. ТЕХНОЛОГИИ CORE i3 Virtualization Technology (VT)
- 132. ТЕХНОЛОГИИ CORE i3 Execute Disable Bit обеспечивает
- 133. ТЕХНОЛОГИИ CORE i3 Enhanced Intel SpeedStep -
- 134. ТЕХНОЛОГИИ CORE i3 Trusted Execution состоит из
- 135. ТЕХНОЛОГИИ CORE i3 Intel 64 Architecture поддерживает
- 136. ГРАФИЧЕСКОЕ ЯДРО Графический чип Intel HD
- 137. ГРАФИЧЕСКОЕ ЯДРО Графический чип находится на общем
- 139. Core i7 920
- 140. Core i7 920 Трёхканальный контроллер памяти DDR3
- 141. Core i7 920 Управление энергопотреблением
- 142. Core i7 920 Управление энергопотреблением Технология
- 143. Подсистема кэширования L2 является «персональной собственностью»
- 144. Ядро 0 запрашивает данные из L3-кэша, и они там не обнаруживаются слева не инклюзивный кэш
- 145. Ядро 0 запрашивает данные из L3-кэша, и они там обнаруживаются слева не инклюзивный кэш
Слайд 1Концепция машины с хранимой в памяти программой
Определения:
Вычислительная машина – совокупность

Слайд 2Основными свойствами алгоритма являются: дискретность, определенность, массовость и результативность.
Дискретность выражается в
том, что алгоритм описывает действия над дискретной информацией (например, числовой или символьной), причем сами эти действия также дискретны.
Свойство определенности означает, что в алгоритме указано все, что должно быть сделано, причем ни одно из действий не должно трактоваться двояко.
Свойство определенности означает, что в алгоритме указано все, что должно быть сделано, причем ни одно из действий не должно трактоваться двояко.

Слайд 3Массовость алгоритма подразумевает его применимость к множеству значений исходных данных, а
не только к каким-то уникальным значениям.
Наконец, результативность алгоритма состоит в возможности получения результата за конечное число шагов.
Рассмотренные свойства алгоритмов предопределяют возможность их реализации на ВМ, при этом процесс, порождаемый алгоритмом, называют вычислительным процессом.
Наконец, результативность алгоритма состоит в возможности получения результата за конечное число шагов.
Рассмотренные свойства алгоритмов предопределяют возможность их реализации на ВМ, при этом процесс, порождаемый алгоритмом, называют вычислительным процессом.

Слайд 4В основе архитектуры современных ВМ лежит представление алгоритма решения задачи в
виде программы последовательных вычислений. Согласно стандарту ISO 2382/1-84, программа для ВМ — это «упорядоченная последовательность команд, подлежащая обработке».
ВМ, где определенным образом закодированные команды программы хранятся в памяти, известна под названием вычислительной машины с хранимой в памяти программой. Идея принадлежит создателям вычислителя ENIАС Эккерту, Мочли и фон Нейману.
ВМ, где определенным образом закодированные команды программы хранятся в памяти, известна под названием вычислительной машины с хранимой в памяти программой. Идея принадлежит создателям вычислителя ENIАС Эккерту, Мочли и фон Нейману.

Слайд 5Сущность фон-неймановской концепции вычислительной машины можно свести к четырем принципам:
двоичного кодирования;
программного управления;
однородности памяти;
адресности

Слайд 6Согласно принципу двоичного кодирования, вся информация, как данные, так и команды,
кодируются двоичными цифрами 0 и 1. Каждый тип информации представляется двоичной последовательностью и имеет свой формат. Последовательность битов в формате, имеющая определенный смысл, называется полем. В числовой информации обычно выделяют поле знака и поле значащих разрядов. В формате команды можно выделить два поля: поле кода операции (КОп) и поле адресов ( АЧ).

Слайд 7Код операции представляет собой указание, какая операция должна быть выполнена, и
задается с помощью n-разрядной двоичной комбинации.
Вид адресной части и число составляющих ее адресов зависят от типа команды: в командах преобразования данных АЧ содержит адреса объектов обработки (операндов) и результата; в командах изменения порядка вычислений – адрес следующей команды программы; в командах ввода/вывода – номер устройства ввода/вывода. Адресная часть также задается с помощью m-разрядной двоичной комбинации. Таким образом, команда в вычислительной машине имеет вид (r+m)-разрядной двоичной комбинации.
Вид адресной части и число составляющих ее адресов зависят от типа команды: в командах преобразования данных АЧ содержит адреса объектов обработки (операндов) и результата; в командах изменения порядка вычислений – адрес следующей команды программы; в командах ввода/вывода – номер устройства ввода/вывода. Адресная часть также задается с помощью m-разрядной двоичной комбинации. Таким образом, команда в вычислительной машине имеет вид (r+m)-разрядной двоичной комбинации.

Слайд 8Принцип программного управления
Все вычисления, предусмотренные алгоритмом решения задачи, должны быть
представлены в виде программы, состоящей из последовательности управляющих слов — команд. Каждая команда предписывает некоторую операцию из набора операций, реализуемых вычислительной машиной. Команды программы хранятся в последовательных ячейках памяти вычислительной машины и выполняются в естественной последовательности, то есть в порядке их положения в программе. При необходимости, с помощью специальных команд, эта последовательность может быть изменена. Решение об изменении порядка выполнения команд программы принимается либо на основании анализа результатов предшествующих вычислений, либо безусловно.

Слайд 9Принцип однородности памяти
Команды и данные хранятся в одной и той же
памяти и внешне в памяти неразличимы. Распознать их можно только по способу использования. Это позволяет производить над командами те же операции, что и над числами. Так, циклически изменяя адресную часть команды, можно обеспечить обращение к последовательным элементам массива данных. Такой прием носит название модификации команд и с позиций современного программирования не приветствуется. Более полезным является другое следствие принципа однородности, когда команды одной программы могут быть получены как результат исполнения другой программы. Эта возможность лежит в основе трансляции — перевода текста программы с языка высокого уровня на язык конкретной ВМ.

Слайд 10Концепция вычислительной машины, изложенная в статье фон Неймана, предполагает единую память
для хранения команд и данных. Такой подход был принят в вычислительных машинах, создававшихся в Принстонском университете, из-за чего и получил название принстонской архитектуры. Практически одновременно в Гарвардском университете предложили иную модель, в которой ВМ имела отдельную память команд и отдельную память данных. Этот вид архитектуры называют гарвардской архитектурой. Долгие годы преобладающей была и остается принстонская архитектура, хотя она порождает проблемы пропускной способности тракта «процессор-память». В последнее время в связи с широким использованием кэш-памяти разработчики ВМ все чаще обращаются к гарвардской архитектуре.

Слайд 11Принцип адресности
Структурно основная память состоит из пронумерованных ячеек, причем процессору в
произвольный момент доступна любая ячейка. Двоичные коды команд и данных разделяются на единицы информации, называемые словами, и хранятся в ячейках памяти, а для доступа к ним используются номера соответствующих ячеек — адреса. Как правило, минимально адресуемая ячейка является байт (8 бит). Ячейки могут объединяться в слова по 2, 4, 8 байт.


Слайд 13Фон Неймана определил основные устройства ВМ, с помощью которых должны быть
реализованы вышеперечисленные принципы. Большинство современных ВМ по своей структуре отвечают принципу программного управления. Типичная фон-неймановская ВМ содержит: память, устройство управления, арифметико-логическое устройство и устройство ввода/вывода.
В любой ВМ имеются средства для ввода программ и данных к ним. Информация поступает из подсоединенных к ЭВМ периферийных устройств (ПУ) ввода. Результаты вычислений выводятся на периферийные устройства вывода. Связь и взаимодействие ВМ и ПУ обеспечивают порты ввода и порты вывода. Термином порт обозначают аппаратуру сопряжения периферийного устройства с ВМ и управления им. Совокупность портов ввода и вывода называют устройством ввода/вывода (УВВ) или модулем ввода/вывода ВМ (МВВ).
В любой ВМ имеются средства для ввода программ и данных к ним. Информация поступает из подсоединенных к ЭВМ периферийных устройств (ПУ) ввода. Результаты вычислений выводятся на периферийные устройства вывода. Связь и взаимодействие ВМ и ПУ обеспечивают порты ввода и порты вывода. Термином порт обозначают аппаратуру сопряжения периферийного устройства с ВМ и управления им. Совокупность портов ввода и вывода называют устройством ввода/вывода (УВВ) или модулем ввода/вывода ВМ (МВВ).

Слайд 14Введенная информация сначала запоминается в основной памяти, а затем переносится во
вторичную память, для длительного хранения. Чтобы программа могла выполняться, команды и данные должны располагаться в основной памяти (ОП), организованной таким образом, что каждое двоичное слово хранится в отдельной ячейке, идентифицируемой адресом, причем соседние ячейки памяти имеют следующие по порядку адреса. Доступ к любым ячейкам запоминающего устройства (ЗУ) основной памяти может производиться в произвольной последовательности. Такой вид памяти известен как память с произвольным доступом (RAM). ОП современных ВМ в основном состоит из полупроводниковых оперативных запоминающих устройств (ОЗУ), обеспечивающих как считывание, так и запись информации.

Слайд 15Для таких ЗУ характерна энергозависимость – хранимая информация теряется при отключении
электропитания. Если необходимо, чтобы часть основной памяти была энергонезависимой, в состав ОП включают постоянные запоминающие устройства (ПЗУ), также обеспечивающие произвольный доступ.
Размер ячейки основной памяти обычно принимается равным 8 двоичным разрядам – байту. Для хранения больших чисел используются 2,4 или 8 байтов, размещаемых в ячейках с последовательными адресами. В этом случае за адрес числа часто принимается адрес его младшего байта.
Размер ячейки основной памяти обычно принимается равным 8 двоичным разрядам – байту. Для хранения больших чисел используются 2,4 или 8 байтов, размещаемых в ячейках с последовательными адресами. В этом случае за адрес числа часто принимается адрес его младшего байта.

Слайд 16Для долговременного хранения больших программ и массивов данных в ВМ обычно
имеется дополнительная память, известная как вторичная. Вторичная память энергонезависима и чаще всего реализуется на базе магнитных дисков. Информация в ней хранится в виде специальных программно поддерживаемых объектов – файлов (согласно стандарту ISO, файл – это «идентифицированная совокупность экземпляров полностью описанного в конкретной программе типа данных, находящихся вне программы во внешней памяти и доступных программе посредством специальных операций»).

Слайд 17Устройство управления (УУ) – важнейшая часть ВМ, организующая автоматическое выполнение программ
(путем реализации функций управления) и обеспечивающая функционирование ВМ как единой системы. Для пояснения функций УУ ВМ следует рассматривать как совокупность элементов, между которыми происходит пересылка информации, в ходе которой эта информация может подвергаться определенным видам обработки.
 – важнейшая часть ВМ, организующая автоматическое выполнение программ (путем реализации функций управления)")
Слайд 18Пересылка информации между любыми элементами ВМ инициируется своим сигналом управления (СУ),
то есть управление вычислительным процессом сводится к выдаче нужного набора СУ в нужной временной последовательности. Основной функцией УУ является формирование управляющих сигналов, отвечающих за извлечение команд из памяти в порядке, определяемом программой, и последующее исполнение этих команд. Кроме того, УУ формирует СУ для синхронизации и координации внутренних и внешних устройств ВМ.
, то есть управление вычислительным")
Слайд 19Еще одной неотъемлемой частью ВМ является арифметико-логическое устройство (АЛУ). АЛУ обеспечивает
арифметическую и логическую обработку двух входных переменных, в результате которой формируется выходная переменная. Функции АЛУ обычно сводятся к простым арифметическим и логическим операциям, а также операциям сдвига. Помимо результата операции АЛУ формирует ряд признаков результата (флагов), характеризующих полученный результат и события, произошедшие в процессе его получения (равенство нулю, знак, четность, перенос, переполнение и т. д.).
. АЛУ обеспечивает арифметическую и логическую обработку")
Слайд 20Флаги могут анализироваться в УУ с целью принятия решения о дальнейшей
последовательности выполнения команд программы.
УУ и АЛУ тесно взаимосвязаны и их обычно рассматривают как единое устройство, известное как центральный процессор (ЦП) или просто процессор. Помимо УУ и АЛУ в процессор входит также набор регистров общего назначения (РОН), служащих для промежуточного хранения информации в процессе ее обработки.
УУ и АЛУ тесно взаимосвязаны и их обычно рассматривают как единое устройство, известное как центральный процессор (ЦП) или просто процессор. Помимо УУ и АЛУ в процессор входит также набор регистров общего назначения (РОН), служащих для промежуточного хранения информации в процессе ее обработки.


Слайд 22В настоящее время примерно одинаковое распространение получили два способа построения вычислительных
машин: с непосредственными связями и на основе шины.
Типичным представителем первого способа может служить классическая фон-неймановская ВМ. В ней между взаимодействующими устройствами (процессор, память, устройство ввода/вывода) имеются непосредственные связи. Особенности связей (число линий в шинах, пропускная способность и т. п.) определяются видом информации, характером и интенсивностью обмена. Достоинством архитектуры с непосредственными связями можно считать возможность развязки «узких мест» путем улучшения структуры и характеристик только определенных связей, что экономически может быть наиболее выгодным решением.
Типичным представителем первого способа может служить классическая фон-неймановская ВМ. В ней между взаимодействующими устройствами (процессор, память, устройство ввода/вывода) имеются непосредственные связи. Особенности связей (число линий в шинах, пропускная способность и т. п.) определяются видом информации, характером и интенсивностью обмена. Достоинством архитектуры с непосредственными связями можно считать возможность развязки «узких мест» путем улучшения структуры и характеристик только определенных связей, что экономически может быть наиболее выгодным решением.


Слайд 24У фон-неймановских ВМ таким «узким местом» является канал пересылки данных между
ЦП и памятью, и «развязать» его достаточно непросто. Кроме того, ВМ с непосредственными связями плохо поддаются реконфигурации.
В варианте с общей шиной все устройства вычислительной машины подключены к магистральной шине, служащей единственным трактом для потоков команд, данных и управления. Наличие общей шины существенно упрощает реализацию ВМ, позволяет легко менять состав и конфигурацию машины.
В варианте с общей шиной все устройства вычислительной машины подключены к магистральной шине, служащей единственным трактом для потоков команд, данных и управления. Наличие общей шины существенно упрощает реализацию ВМ, позволяет легко менять состав и конфигурацию машины.


Слайд 26Благодаря этим свойствам шинная архитектура получила широкое распространение в мини и
микроЭВМ. Вместе с тем, именно с шиной связан и основной недостаток архитектуры: в каждый момент передавать информацию по шине может только одно устройство. Основную нагрузку на шину создают обмены между процессором и памятью, связанные с извлечением из памяти команд и данных и записью в память результатов вычислений. На операции ввода/вывода остается лишь часть пропускной способности шины. Практика показывает, что даже при достаточно быстрой шине для 90% приложений этих остаточных ресурсов обычно не хватает, особенно в случае ввода или вывода больших массивов данных.

Слайд 27В целом, при сохранении фон-неймановской концепции последовательного выполнения команд программы шинная
архитектура в чистом ее виде оказывается недостаточно эффективной. Более распространена архитектура с иерархией шин, где помимо магистральной шины имеется еще несколько дополнительных шин. Они могут обеспечивать непосредственную связь между устройствами с наиболее интенсивным обменом, например процессором и кэш памятью. Другой вариант использования дополнительных шин — объединение однотипных устройств ввода/вывода с последующим выходом с дополнительной шины на магистральную. Все эти меры позволяют снизить нагрузку на общую шину и более эффективно расходовать ее пропускную способность.





Слайд 32Системой команд вычислительной машины называют полный перечень команд, которые способна выполнять
данная ВМ. В свою очередь, под архитектурой системы команд (АСК) принято определять те средства вычислительной машины, которые видны и доступны программисту. АСК можно рассматривать как линию согласования нужд разработчиков программного обеспечения с возможностями создателей аппаратуры вычислительной машины.
Хронология развития архитектур системы команд
Хронология развития архитектур системы команд

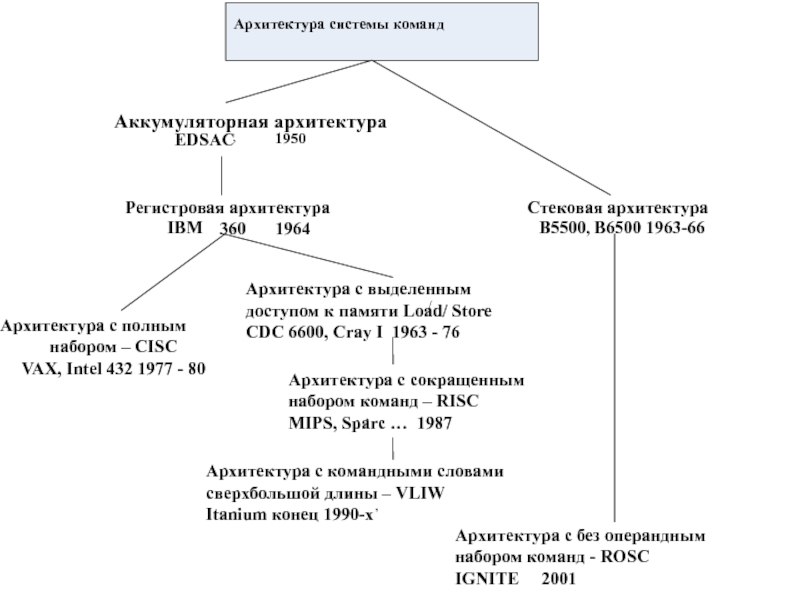
Слайд 34Стековая архитектура
Стеком называется память, по своей структурной организации отличная от основной
памяти ВМ. Принципы построения стековой памяти детально рассматриваются позже, здесь же выделим только те аспекты, которые требуются для пояснения особенностей АСК на базе стека.
Стек образует множество логически взаимосвязанных ячеек ,взаимодействующих по принципу «последним вошел, первым вышел» (LIFO, Last In First Out).
Стек образует множество логически взаимосвязанных ячеек ,взаимодействующих по принципу «последним вошел, первым вышел» (LIFO, Last In First Out).


Слайд 36Верхнюю ячейку называют вершиной стека. Для работы со стеком предусмотрены две
операции: push (проталкивание данных в стек) и рор (выталкивание данных из стека). Запись возможна только в верхнюю ячейку стека, при этом вся хранящаяся в стеке информация предварительно проталкивается на одну позицию вниз. Чтение допустимо также только из вершины стека. Извлеченная информация удаляется из стека, а оставшееся его содержимое продвигается вверх. В вычислительных машинах, где реализована АСК на базе стека, операнды перед обработкой помещаются в две верхних ячейки стековой памяти. Результат операции заносится в стек.


Слайд 38Для выполнения арифметической или логической операции на вход АЛУ подается информация,
считанная из двух верхних ячеек стека (при этом содержимое стека продвигается на две позиции вверх, то есть операнды из стека удаляются). Результат операции заталкивается в вершину стека. Верхние ячейки стековой памяти, где хранятся операнды и куда заносится результат операции, как правило, делаются более быстродействующими и размещаются в процессоре, в то время как остальная часть стека может располагаться в основной памяти и частично даже на магнитном диске.

Слайд 39К достоинствам АСК на базе стека следует отнести возможность сокращения адресной
части команд, поскольку все операции производятся через вершину стека, то есть адреса операндов и результата в командах арифметической и логической обработки информации указывать не нужно. Код программы получается компактным. Достаточно просто реализуется декодирование команд.
С другой стороны, стековая АСК по определению не предполагает произвольного доступа к памяти, из-за чего компилятору трудно создать эффективный программный код, хотя создание самих компиляторов упрощается. Кроме того, стек становится «узким местом» ВМ в плане повышения производительности.
С другой стороны, стековая АСК по определению не предполагает произвольного доступа к памяти, из-за чего компилятору трудно создать эффективный программный код, хотя создание самих компиляторов упрощается. Кроме того, стек становится «узким местом» ВМ в плане повышения производительности.

Слайд 40Аккумуляторная архитектура
Архитектура на базе аккумулятора исторически возникла одной из первых. В
ней для хранения одного из операндов арифметической или логической операции в процессоре имеется выделенный регистр — аккумулятор. В этот же регистр заносится и результат операции. Поскольку адрес одного из операндов предопределен, в командах обработки достаточно явно указать местоположение только второго операнда. Изначально оба операнда хранятся в основной памяти, и до выполнения операции один из них нужно загрузить в аккумулятор. После выполнения команды обработки результат находится в аккумуляторе и, если он не является операндом для последующей команды, его требуется сохранить в ячейке памяти.


Слайд 42Для выполнения операции в АЛУ производится считывание одного из операндов из
памяти в регистр данных. Второй операнд находится в аккумуляторе. Выходы регистра данных и аккумулятора подключаются к соответствующим входам АЛУ. По окончании предписанной операции результат с выхода АЛУ заносится в аккумулятор.
Достоинствами аккумуляторной АСК можно считать короткие команды и простоту декодирования команд. Однако наличие всего одного регистра порождает многократные обращения к основной памяти.
Достоинствами аккумуляторной АСК можно считать короткие команды и простоту декодирования команд. Однако наличие всего одного регистра порождает многократные обращения к основной памяти.

Слайд 43Регистровая архитектура
В машинах данного типа процессор включает в себя массив регистров
(регистровый файл), известных как регистры общего назначения (РОН). Эти регистры, в каком-то смысле, можно рассматривать как явно управляемый кэш для хранения недавно использовавшихся данных.
Размер регистров обычно фиксирован и совпадает с размером машинного слова. К любому регистру можно обратиться, указав его номер. Количество РОН в архитектурах типа CISC обычно невелико (от 8 до 32), и для представления номера конкретного регистра необходимо не более пяти разрядов, благодаря чему в адресной части команд обработки допустимо одновременно указать номера двух, а зачастую и трех регистров (двух регистров операндов и регистра результата).
Размер регистров обычно фиксирован и совпадает с размером машинного слова. К любому регистру можно обратиться, указав его номер. Количество РОН в архитектурах типа CISC обычно невелико (от 8 до 32), и для представления номера конкретного регистра необходимо не более пяти разрядов, благодаря чему в адресной части команд обработки допустимо одновременно указать номера двух, а зачастую и трех регистров (двух регистров операндов и регистра результата).
, известных как")
Слайд 44RISC-архитектура предполагает использование существенно большего числа РОН (до нескольких сотен), однако
типичная для таких ВМ длина команды (обычно 32 разряда) позволяет определить в команде до трех регистров.
Регистровая архитектура допускает расположение операндов в одной из двух запоминающих сред: основной памяти или регистрах. С учетом возможного размещения операндов в рамках регистровых АСК выделяют три подвида команд обработки:
регистр-регистр;
регистр-память;
память-память.
Регистровая архитектура допускает расположение операндов в одной из двух запоминающих сред: основной памяти или регистрах. С учетом возможного размещения операндов в рамках регистровых АСК выделяют три подвида команд обработки:
регистр-регистр;
регистр-память;
память-память.
, однако типичная для таких ВМ")
Слайд 45В варианте «регистр-регистр» операнды могут находиться только в регистрах. В них
же засылается и результат. Подтип «регистр-память» предполагает, что один из операндов размещается в регистре, а второй в основной памяти. Результат обычно замещает один из операндов. В командах типа «память-память» оба операнда хранятся в основной памяти. Результат заносится в память. Вариант «регистр-регистр» является основным в вычислительных машинах типа RISC. Команды типа «регистр-память» характерны для CISC-машин. Наконец, вариант «память-память» считается неэффективным, хотя и остается в наиболее сложных моделях машин класса CISC.

Слайд 46К достоинствам регистровых АСК следует отнести: компактность получаемого кода, высокую скорость
вычислений за счет замены обращений к основной памяти на обращения к быстрым регистрам. С другой стороны, данная архитектура требует более длинных инструкций по сравнению с аккумуляторной архитектурой.
Примерами машин на базе РОН могут служить CDC 6600, IBM 360/3/0, PDP-11, все современные персональные компьютеры. Правомочно утверждать, что в наши дни этот вид архитектуры системы команд является преобладающим.
Примерами машин на базе РОН могут служить CDC 6600, IBM 360/3/0, PDP-11, все современные персональные компьютеры. Правомочно утверждать, что в наши дни этот вид архитектуры системы команд является преобладающим.

Слайд 47Архитектура с выделенным доступом к памяти
В архитектуре с выделенным доступом к
памяти обращение к основной памяти возможно только с помощью двух специальных команд: load и store. В английской транскрипции данную архитектуру называют Load/Store architecture. Команда load (загрузка) обеспечивает считывание значения из основной памяти и занесение его в регистр процессора (в команде обычно указывается адрес ячейки памяти и номер регистра). Пересылка информации в противоположном направлении производится командой store (сохранение). Операнды во всех командах обработки информации могут находиться только в регистрах процессора (чаще всего в регистрах общего назначения). Результат операции также заносится в регистр.

Слайд 48В архитектуре отсутствуют команды обработки, допускающие прямое обращение к основной памяти.
Допускается наличие в АСК ограниченного числа команд, где операнд является частью кода команды. АСК с выделенным доступом к памяти характерна для всех вычислительных машин с RISC-архитектурой. Команды в таких ВМ, как правило, имеют длину 32 бита и трехадресный формат. В качестве примеров вычислительных машин с выделенным доступом к памяти можно отметить HP PA-RISC, IBM RS/6000, Sun SPARC, MIPS R4000, DEC Alpha и т. д. К достоинствам АСК следует отнести простоту декодирования и исполнения команды.

Слайд 49Классификация по составу и сложности команд
Современная технология программирования ориентирована на
языки высокого уровня (ЯВУ), главная цель которых — облегчить процесс программирования. Переход к ЯВУ, однако, породил серьезную проблему: сложные операторы, характерные для ЯВУ, существенно отличаются от простых машинных операций, реализуемых в большинстве вычислительных машин. Проблема получила название семантического разрыва, а ее следствием становится недостаточно эффективное выполнение программ на ВМ.
,")
Слайд 50Пытаясь преодолеть семантический разрыв, разработчики вычислительных машин в настоящее время выбирают
один из трех подходов и, соответственно, один из трех типов АСК:
архитектуру с полным набором команд: CISC (Complex Instruction Set Computer);
архитектуру с сокращенным набором команд: RISC (Reduced Instruction Set Computer);
архитектуру с командными словами сверхбольшой длины: VLIW (Very Long Instruction Word).
архитектуру с полным набором команд: CISC (Complex Instruction Set Computer);
архитектуру с сокращенным набором команд: RISC (Reduced Instruction Set Computer);
архитектуру с командными словами сверхбольшой длины: VLIW (Very Long Instruction Word).

Слайд 51В вычислительных машинах типа CISC проблема семантического разрыва решается за счет
расширения системы команд, дополнения ее сложными командами, семантически аналогичными операторам ЯВУ.
Для CISC-архитектуры типичны:
наличие в процессоре сравнительно небольшого числа регистров общего назначения;
большое количество машинных команд, некоторые из них аппаратно реализуют сложные операторы ЯВУ;
разнообразие способов адресации операндов; множество форматов команд различной разрядности;
наличие команд, где обработка совмещается с обращением к памяти.
Для CISC-архитектуры типичны:
наличие в процессоре сравнительно небольшого числа регистров общего назначения;
большое количество машинных команд, некоторые из них аппаратно реализуют сложные операторы ЯВУ;
разнообразие способов адресации операндов; множество форматов команд различной разрядности;
наличие команд, где обработка совмещается с обращением к памяти.

Слайд 52К типу CISC можно отнести практически все ВМ, выпускавшиеся до середины
1980-х годов, и значительную часть производящихся в настоящее время.
Рассмотренный способ решения проблемы семантического разрыва вместе с тем ведет к усложнению аппаратуры ВМ, главным образом устройства управления, что, в свою очередь, негативно сказывается на производительности ВМ в целом.
Указанные недостатки привели к созданию RISC архитектуре команд.
Рассмотренный способ решения проблемы семантического разрыва вместе с тем ведет к усложнению аппаратуры ВМ, главным образом устройства управления, что, в свою очередь, негативно сказывается на производительности ВМ в целом.
Указанные недостатки привели к созданию RISC архитектуре команд.

Слайд 53Термин RISC впервые был использован Д. Паттерсоном и Д. Дитцелем в
1980 году. Идея заключается в ограничении списка команд ВМ наиболее часто используемыми простейшими командами, размещенными только в регистрах процессора. Обращение к памяти допускается лишь с помощью специальных команд чтения и записи. Резко уменьшено количество форматов команд и способов указания адресов операндов. Сокращение числа форматов команд и их простота, использование ограниченного количества способов адресации, отделение операций обработки данных от операций обращения к памяти позволяет существенно упростить аппаратные средства ВМ и повысить их быстродействие.

Слайд 54Элементы RISC-архитектуры впервые появились в вычислительных машинах CDC 6600 и суперЭВМ
компании Cray Research. Достаточно успешно реализуется RISC-архитектура и в современных ВМ, например в процессорах Alpha фирмы DEC, серии РА фирмы Hewlett-Packard, семействе PowerPC и т. п.
Отметим, что в последних микропроцессорах фирмы Intel и AMD широко используются идеи, свойственные RISC-архитектуре, так что многие различия между CISC и RISC постепенно стираются.
Отметим, что в последних микропроцессорах фирмы Intel и AMD широко используются идеи, свойственные RISC-архитектуре, так что многие различия между CISC и RISC постепенно стираются.

Слайд 55Помимо CISC- и RISC-архитектур в общей классификации был упомянут еще один
тип АСК — архитектура с командными словами сверхбольшой длины (VLIW). Концепция VLIW базируется на RISC-архитектуре, где несколько простых RISC-команд объединяются в одну сверхдлинную команду и выполняются параллельно. В плане АСК архитектура VLIW сравнительно мало отличается от RISC. Появился лишь дополнительный уровень параллелизма вычислений, в силу чего архитектуру VLIW логичнее адресовать не к вычислительным машинам, а к вычислительным системам.

Слайд 56Основные направления в развитии архитектур процессоров
Конвейеризация вычислений
Суперконвейерные процессоры
Суперскалярные
процессоры

Слайд 57Конвейер команд
Идея конвейера команд была предложена в 1956 году академиком
С. А. Лебедевым. Как известно, цикл команды представляет собой последовательность этапов. Возложив реализацию каждого из них на самостоятельное устройство и последовательно соединив такие устройства, мы получим классическую схему конвейера команд. Выделим в цикле команды шесть этапов:
Выборка команды (ВК). Чтение очередной команды из памяти и занесение ее в регистр команды.
Декодирование команды (ДК). Определение кода операции и способов адресации операндов.
Выборка команды (ВК). Чтение очередной команды из памяти и занесение ее в регистр команды.
Декодирование команды (ДК). Определение кода операции и способов адресации операндов.

Слайд 583. Вычисление адресов операндов (ВА). Вычисление исполнительных адресов каждого из операндов
в соответствии с указанным в команде способом их адресации.
4. Выборка операндов (ВО). Извлечение операндов из памяти. Эта операция не нужна для операндов, находящихся в регистрах.
5. Исполнение команды (ИК). Исполнение указанной операции.
6. Запись результата (ЗР). Занесение результата в память.
4. Выборка операндов (ВО). Извлечение операндов из памяти. Эта операция не нужна для операндов, находящихся в регистрах.
5. Исполнение команды (ИК). Исполнение указанной операции.
6. Запись результата (ЗР). Занесение результата в память.
. Вычисление исполнительных адресов каждого из операндов в соответствии с указанным")

Слайд 60На рисунке показан конвейер с шестью ступенями, соответствующими шести этапам цикла
команды. В диаграмме предполагается, что каждая команда обязательно проходит все шесть ступеней, хотя этот случай не совсем типичен. Так, команда загрузки регистра не требует этапа ЗР. Кроме того, здесь принято, что все этапы могут выполняться одновременно. Без конвейеризации выполнение девяти команд заняло бы 9 х 6 = 54 единицы времени. Использование конвейера позволяет сократить время обработки до 14 единиц.

Слайд 61Суперконвейер
Разбиение каждой ступени конвейера на n «подступеней» при одновременном повышении тактовой
частоты внутри конвейера также в n раз;
Включение в состав процессора n конвейеров, работающих с перекрытием.
Включение в состав процессора n конвейеров, работающих с перекрытием.

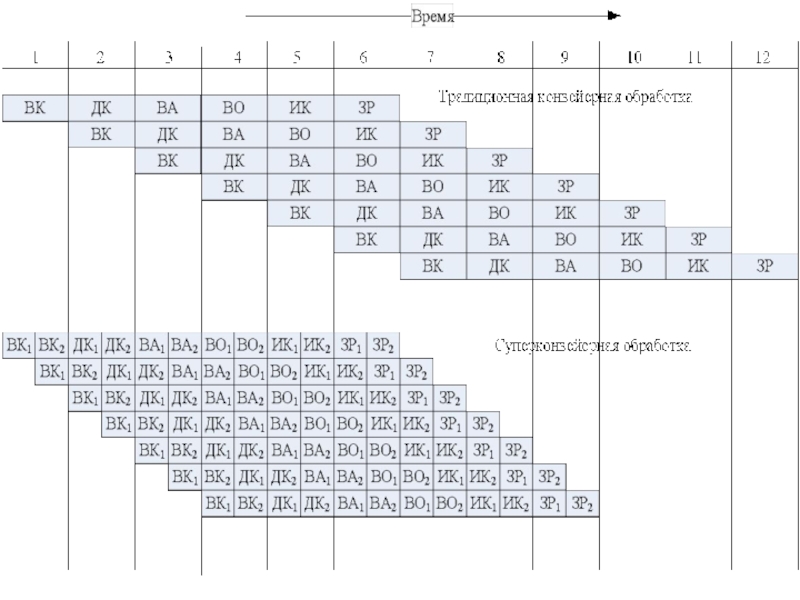
Слайд 63Каждая из шести ступеней стандартного конвейера разбита на две более простые
подступени, обозначенные индексами 1 и 2. Выполнение операции в подступенях занимает половину тактового периода. Тактирование операций внутри конвейера производится с частотой, вдвое превышающей частоту «внешнего» тактирования конвейера, благодаря чему на каждой ступени конвейера можно в пределах одного «внешнего» тактового периода выполнить две команды.
В сущности, суперконвейеризация сводится к увеличению количества ступеней конвейера как за счет добавления новых ступеней, так и путем дробления имеющихся ступеней на несколько простых подступеней. Главное требование — возможность реализации операции в каждой подступени наиболее простыми техническими средствами, а значит, с минимальными затратами времени.
В сущности, суперконвейеризация сводится к увеличению количества ступеней конвейера как за счет добавления новых ступеней, так и путем дробления имеющихся ступеней на несколько простых подступеней. Главное требование — возможность реализации операции в каждой подступени наиболее простыми техническими средствами, а значит, с минимальными затратами времени.

Слайд 64Структурный риск - попытка нескольких команд одновременно обратиться к одному и
тому же ресурсу ВМ.
Риск по данным - взаимосвязь команд по данным.
Риск по управлению - неоднозначность при выборке следующей команды в случае команд перехода.
Риск по данным - взаимосвязь команд по данным.
Риск по управлению - неоднозначность при выборке следующей команды в случае команд перехода.
Классификация рисков конвейеров

Слайд 65Структурный риск имеет место, когда несколько команд, находящихся на разных ступенях
конвейера, пытаются одновременно пользовать один и тот же ресурс, чаще всего - память. Так, в типовом цикле команды сразу три этапа (ВК, ВО и ЗР) связаны с обращением к памяти. Подобных конфликтов частично удается избежать за счет модульного построения памяти и использования кэшпамяти - имеется вероятность того, что команды будут обращаться либо к разные модулям ОП, либо одна из них станет обращаться к основной памяти, а другая — к кэш-памяти.

Слайд 66«Чтение после записи» (ЧПЗ): команда j читает X до того, как
команда i успеет записать новое значение X, то есть j ошибочно получит старое значение X вместо нового.
«Запись после чтения» (ЗПЧ): команда j запи -сывает новое значение X до того как команда i успела прочитать X, то есть команда i ошибочно получит новое значение X вместо старого.
«Запись после записи» (ЗПЗ): команда j записывает новое значение X прежде, чем команда i успела записать в качестве X свое значение, то есть X ошибочно содержит i-е значение X вместо j-го
«Запись после чтения» (ЗПЧ): команда j запи -сывает новое значение X до того как команда i успела прочитать X, то есть команда i ошибочно получит новое значение X вместо старого.
«Запись после записи» (ЗПЗ): команда j записывает новое значение X прежде, чем команда i успела записать в качестве X свое значение, то есть X ошибочно содержит i-е значение X вместо j-го
Три типа конфликтов по данным
: команда j читает X до того, как команда i успеет записать")
Слайд 67Для решения этих проблем применяют предвыборку команд и их спекулятивное выполнение.
Команды выполняются не в естественном порядке, а в порядке обеспечивающим не зависимость по данным. Если это не возможно в команды вставляются холостые такты. Для обеспечения не зависимости по регистрам каждое исполняющее устройство имеет свой набор регистров общего назначения.


Слайд 69Пусть команда 3 – это условный переход к команде 15. До
завершения команды 3 невозможно определить, какая из команд (4-я или 15-я) должна выполняться следующей, поэтому конвейер просто загружает следующую команду в последовательности (команду 4) и продолжает свою работу. На рисунке переход имеет место, о чем неизвестно до 7-го шага. В этой точке конвейер должен быть очищен от ненужных команд, выполнявшихся до данного момента. Лишь на шаге 8 на конвейер поступает нужная команда 15, из-за чего в течение тактов от 9 до 12 не будет завершена ни одна другая команда. Это и есть издержки из-за невозможности предвидения исхода команды условного перехода.

Слайд 70 Статическое предсказание переходов.
Динамическое предсказание переходов.
Классификации схем предсказания переходов

Слайд 71Переход происходит всегда.
Переход не происходит никогда.
Предсказание определяется по результатам профилирования.
Предсказание определяется
кодом операции команды перехода.
Предсказание зависит от направления перехода.
Предсказание зависит от направления перехода.
Стратегии статического предсказания для команд УП

Слайд 72 Предполагается, что каждая команда условного перехода в программе обязательно завершится переходом,
и, с учетом такого предсказания, дальнейшая выборка команд производится, начиная с адреса перехода.
Переход происходит всегда

Слайд 73 Предполагается, что ни одна из команд условного перехода в программе никогда
не завершается переходом, поэтому выборка команд продолжается в естественной последовательности.
Переход не происходит никогда

Слайд 74 По результатам профилирования, тем командам, которые чаще завершались переходом, назначается стратегия
ПВ, а всем остальным — ПН.
Предсказание определяется по результатам профилирования

Слайд 75 Для одних команд предполагается, что переход произойдет, для других — его
не случится.
Предсказание определяется кодом операции команды перехода

Слайд 76Одноуровневые или бимодальные.
Двухуровневые или коррелированные.
Гибридные.
Асимметричные.
Стратегии динамического предсказания для команд УП

Слайд 77
Одноуровневые схемы предсказания переходов
Идея одноуровневых схем предсказания, сводится к отделению
команд, имеющих склонность завершаться переходом, от команд, при выполнении которых переход обычно не происходит. Такая дифференциация позволяет для каждой команды выбрать наиболее подходящее предсказание. Для реализации идеи в составе схемы предсказания достаточно иметь лишь одну таблицу, каждый элемент которой отображает историю исходов одной команды УП.

Слайд 78 Предсказание осуществляется на основе предыдущих исходов как команды УП, для которой
производится предсказание, так и от результатов выполнения других предшествующих им команд УП.
Двухуровневые схемы предсказания переходов

Слайд 79 Гибридные схемы объединяют в себе несколько различных механизмов предсказания — элементарных
предикторов (средств прогнозирования ). Идея состоит в том, чтобы в каждой конкретной ситуации задействовать тот элементарный предиктор, от которого в данном случае можно ожидать наибольшей точности предсказания.
Гибридные схемы предсказания переходов
.")
Слайд 80 Асимметричная схема сочетает в себе черты гибридных и коррелированных схем
предсказания. От гибридных схем она переняла одновременное срабатывание нескольких различных элементарных предикторов. А для доступа к таблицам, аналогично коррелированным схемам, используется как адрес команды условного перехода, так и содержимое регистра глобальной истории.
Асимметричные схемы предсказания переходов

Слайд 81Суперскалярность
Суперскалярным (этот термин впервые был использован в 1987 году) называется
центральный процессор (ЦП), который одновременно выполняет более чем одну скалярную команду. Это достигается за счет включения в состав ЦП нескольких самостоятельных функциональных (исполнительных) блоков, каждый из которых отвечает за свой класс операций и может присутствовать в процессоре в нескольких экземплярах. Так, в микропроцессоре Pentium III блоки целочисленной арифметики и операций с плавающей точкой дублированы, а в микропроцессорах Pentium 4 и Athlon – троированы.
 называется центральный процессор (ЦП), который")

Слайд 83Блок выборки команд извлекает команды из основной памяти через кэш-память команд.
Этот блок хранит несколько значений счетчика команд и обрабатывает команды условного перехода.
Блок декодирования расшифровывает код операции, содержащийся в извлеченных из кэш-памяти командах. Блоки диспетчеризации и распределения взаимодействуют между собой и в совокупности играют в суперскалярном процессоре роль контроллера трафика. Оба блока хранят очереди декодированных команд. Очередь блока распределения часто рассредоточивается по несколько самостоятельным буферам – накопителям команд или схемам резервирования,– предназначенным для хранения команд, которые уже декодированы, но еще не выполнены.
Блок декодирования расшифровывает код операции, содержащийся в извлеченных из кэш-памяти командах. Блоки диспетчеризации и распределения взаимодействуют между собой и в совокупности играют в суперскалярном процессоре роль контроллера трафика. Оба блока хранят очереди декодированных команд. Очередь блока распределения часто рассредоточивается по несколько самостоятельным буферам – накопителям команд или схемам резервирования,– предназначенным для хранения команд, которые уже декодированы, но еще не выполнены.

Слайд 84Каждый накопитель команд связан со своим функциональным блоком (ФБ), поэтому число
накопителей обычно равно числу ФБ, но если в процессоре используется несколько однотипных ФБ, то им придается общий накопитель. По отношению к блоку диспетчеризации накопители команд выступают в роли виртуальных функциональных устройств.
В дополнение к очереди, блок диспетчеризации хранит также список свободных функциональных блоков, называемый табло (scoreboard). Табло используется для отслеживания состояния очереди распределения. Один раз за цикл блок диспетчеризации извлекает команды из своей очереди, считывает из памяти или регистров операнды этих команд, после чего, в зависимости от состояния табло, помещает команды и значения операндов в очередь распределения.
В дополнение к очереди, блок диспетчеризации хранит также список свободных функциональных блоков, называемый табло (scoreboard). Табло используется для отслеживания состояния очереди распределения. Один раз за цикл блок диспетчеризации извлекает команды из своей очереди, считывает из памяти или регистров операнды этих команд, после чего, в зависимости от состояния табло, помещает команды и значения операндов в очередь распределения.
, поэтому число накопителей обычно равно числу")
Слайд 85Эта операция называется выдачей команд. Блок распределения в каждом цикле проверяет
каждую команду в своих очередях на наличие всех необходимых для ее выполнения операндов и при положительном ответе начинает выполнение таких команд в соответствующем функциональном блоке.
Блок исполнения состоит из набора функциональных блоков. Примерами ФБ могут служить целочисленные операционные блоки, блоки умножения и сложения с плавающей запятой, блок доступа к памяти. Когда исполнение команды завершается, ее результат записывается и анализируется блоком обновления состояния, который обеспечивает учет полученного результата теми командами в очередях распределения, где этот результат выступает в качестве одного из операндов.
Блок исполнения состоит из набора функциональных блоков. Примерами ФБ могут служить целочисленные операционные блоки, блоки умножения и сложения с плавающей запятой, блок доступа к памяти. Когда исполнение команды завершается, ее результат записывается и анализируется блоком обновления состояния, который обеспечивает учет полученного результата теми командами в очередях распределения, где этот результат выступает в качестве одного из операндов.



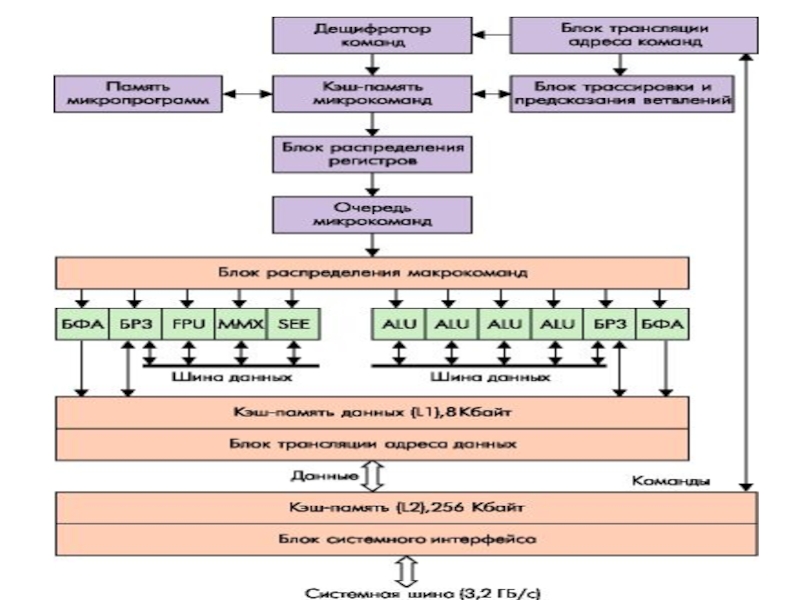
Слайд 89БФА - блок формирования адреса
БРЗ - блок регистров замещения
FPU - АЛУ
для выполнения инструкций с плавающей запятой
MMX - блок для выполнения мультимедийных инструкций
SEE - блок для выполнения потоковых (SIMD) инструкций
ALU - АЛУ для целых чисел
MMX - блок для выполнения мультимедийных инструкций
SEE - блок для выполнения потоковых (SIMD) инструкций
ALU - АЛУ для целых чисел

Слайд 90Hyper-threading ( Hyper-threading — Гиперпоточность)
В процессорах с использованием этой технологии каждый
физический процессор может хранить состояние сразу двух потоков, что для операционной системы выглядит как наличие двух логических процессоров
 В процессорах с использованием этой технологии каждый физический процессор может хранить")
Слайд 91Потоки
С точки зрения процессора, поток – это набор инструкций, которые необходимо
выполнить.
Когда поток отправляется на процессор, адрес памяти потока загружается в этот счетчик команд
После каждой инструкции значение этого регистра увеличивается. Процесс выполняется до завершения потока.
По окончании выполнения потока, в счетчик команд заносится адрес следующей инструкции, которую нужно выполнить.
Потоки могут прерывать друг друга, при этом процессор запоминает значение счетчика команд в стеке и загружает в счетчик новое значение.
Когда поток отправляется на процессор, адрес памяти потока загружается в этот счетчик команд
После каждой инструкции значение этого регистра увеличивается. Процесс выполняется до завершения потока.
По окончании выполнения потока, в счетчик команд заносится адрес следующей инструкции, которую нужно выполнить.
Потоки могут прерывать друг друга, при этом процессор запоминает значение счетчика команд в стеке и загружает в счетчик новое значение.

Слайд 92Развитие микропроцессоров
CMP (Chip Multi Processing -многоядерность )
SMT (Simultaneous MultiThreading -многонитевая
архитектура )
EPIC (Explicitly Parallel Instruction Computing - очень длинное командное слово )
EPIC (Explicitly Parallel Instruction Computing - очень длинное командное слово )
 SMT (Simultaneous MultiThreading -многонитевая архитектура )EPIC (Explicitly Parallel")
Слайд 93Направление CMP
Создание на одном кристалле нескольких микропроцессоров и организация их работы
по принципу мультипроцессорных систем (процессоры Core 2 Duo , Core i3 - Core i7 …)

Слайд 94Направление SMT
На одном процессоре осуществляется запуск нескольких задач одновременно, при
этом распараллеливание программ осуществляется аппаратными средствами МП ( Hyper-threading — Гиперпоточность)

Слайд 95Архитектура EPIC
На входе процессора последовательность больших команд, состоящих из нескольких простых
операций, которые могут исполняться параллельно.
Преимущества перед суперскалярами:
Меньше места на процессоре тратится на управление, больше остается на ресурсы: регистры, исполнительные устройства, кэш-память.
Более тщательное планирование дает лучшее заполнение исполнительных устройств (больше команд за такт).
Преимущества перед суперскалярами:
Меньше места на процессоре тратится на управление, больше остается на ресурсы: регистры, исполнительные устройства, кэш-память.
Более тщательное планирование дает лучшее заполнение исполнительных устройств (больше команд за такт).

Слайд 96Недостатки
Значительно усложняются компиляторы
Производительность микропроцессора во многом определяется качеством компилятора
Увеличивается сложность отладки


Слайд 99Архитектура Pentium M
Мобильная версия
RISC архитектура как в Pentium III, IV
Пять
исполнительных устройств в ядре
Улучшенный механизм предсказания ветвлений и аппаратная предвыборка данных
Технология micro-ops fusion
Выделенный менеджер стека
Энергосберегающий кеш второго уровня
Технология SpeedStep III
Улучшенный механизм предсказания ветвлений и аппаратная предвыборка данных
Технология micro-ops fusion
Выделенный менеджер стека
Энергосберегающий кеш второго уровня
Технология SpeedStep III



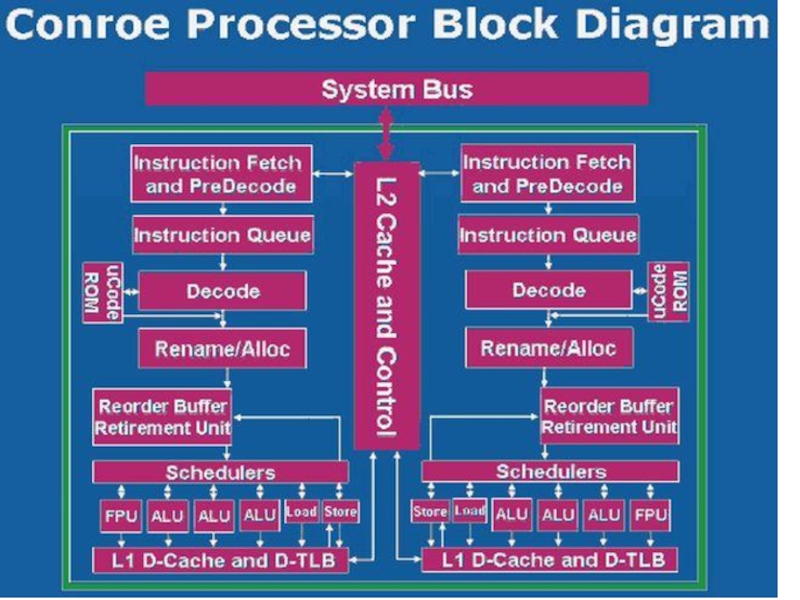
Слайд 103Основные особенности архитектуры Intel Core
Технология широкого динамического выполнения (Wide Dynamic Execution)
Интеллектуальная система управления энергопотреблением (Intelligent Power Capability)
Улучшенный "умный" кэш (Advanced Smart Cache)
"Умный" доступ к памяти (Smart Memory Access)
Улучшенная работа с цифровым медиа-содержанием (Advanced Digital Media Boost)
 Интеллектуальная система управления")
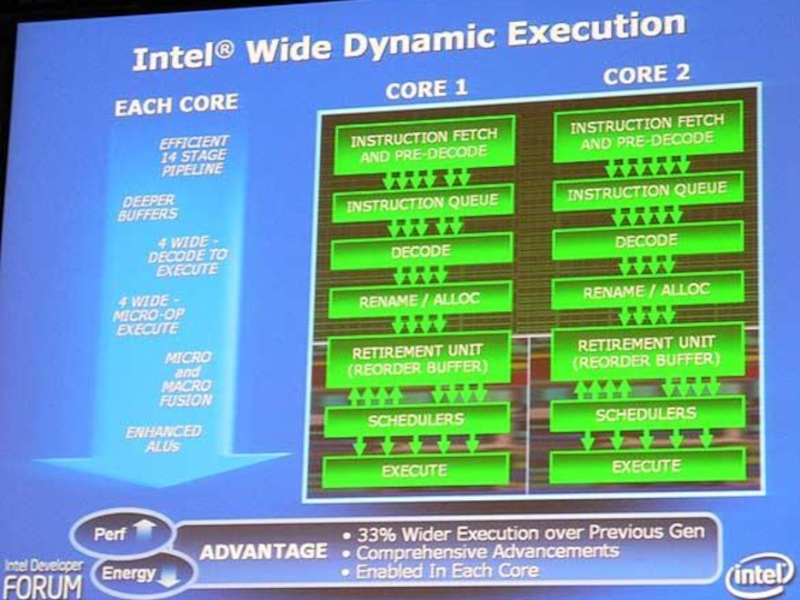
Слайд 104Технология широкого динамического выполнения
Призвана обеспечить выполнение большего количества команд за каждый
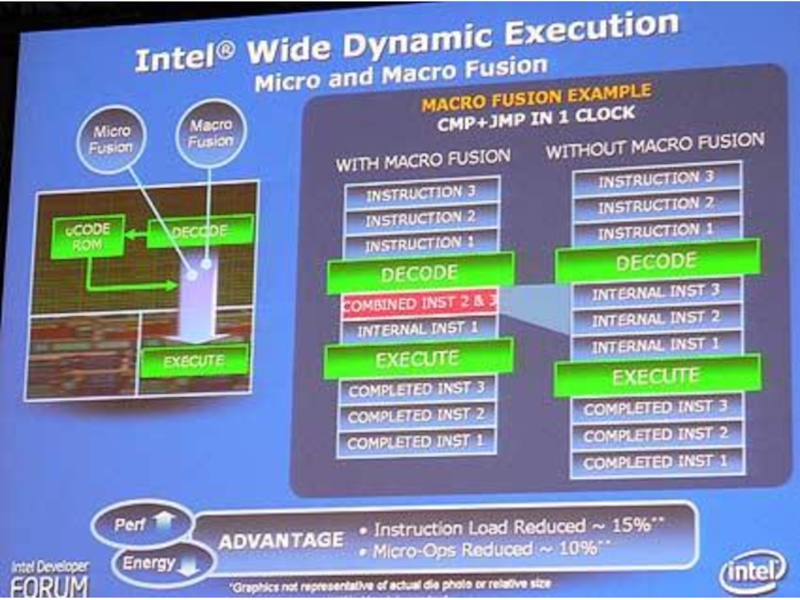
такт, повышая эффективность выполнения приложений и сокращая энергопотребление. Каждое ядро процессора, поддерживающего эту технологию, теперь может выполнять до четырех инструкций одновременно с помощью 14-стадийного конвейера.



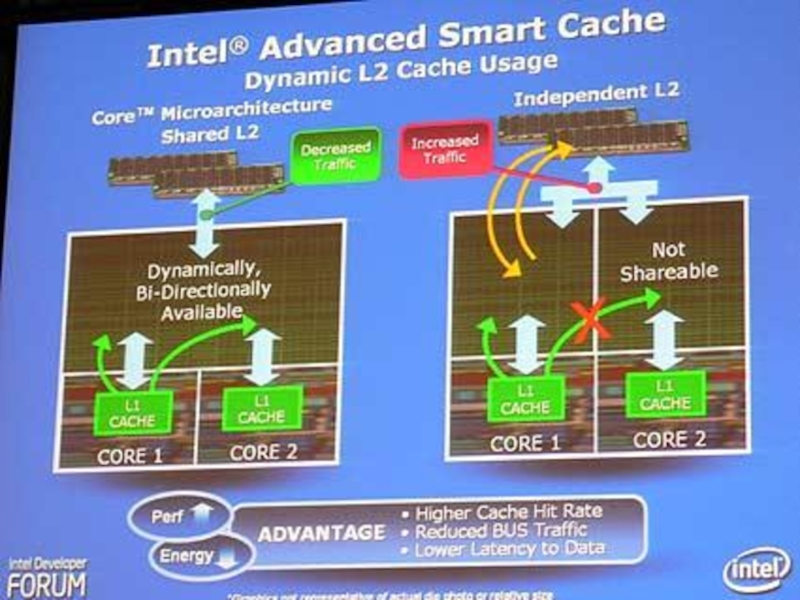
Слайд 109Интеллектуальная система управления энергопотреблением
Технологии стробирования тактовых импульсов (clock gating) и "спящих"
транзисторов (sleep transistors) гарантируют, что все неиспользуемые транзисторы будут выключены. Технология Enhanced SpeedStep по-прежнему снижает тактовую частоту, если нагрузка на систему невелика. Но сейчас технология может управлять каждым ядром по отдельности. Кроме того, разные блоки процессора могут получать разное напряжение
 и")

Слайд 111Улучшенный "умный" кэш
Два ядра совместно используют кэш объёмом 2 или 4
Мбайт. Кэширование производится более эффективно, ведь данные не нужно хранить по два раза в отдельных кэшах L2 (дублировать). Кэш L2 полностью динамический и способен адаптироваться под нагрузку каждого ядра. Например, одно ядро может динамически забрать 100% кэша L2, если это требуется

Слайд 113"Умный" доступ к памяти
Улучшенная предварительная выборка
Каждый двуядерный процессор Core оснащён восемью
блоками предварительной выборки (prefetch): два блока выборки данных и один блок выборки инструкций на ядро, а также два блока выборки в общем кэше L2. Блок предварительной выборки предоставляет данные вышестоящим блокам, используя сложные алгоритмы предсказания. Он должен запросить данные, которые вероятно будут использоваться в ближайшем времени, что снижает задержки и повышает эффективность.

Слайд 114"Умный" доступ к памяти
Улучшенная предварительная выборка
Блоки предварительной выборки памяти постоянно оценивают
картину использования памяти, пытаясь предсказать будущие запросы и закачать соответствующие данные в кэш L2. В то же время, блоки предварительной выборки должны следить за потоковым трафиком, кэшировать который смысла не имеет.

Слайд 115"Умный" доступ к памяти
Устранение неоднозначностей памяти
Блок устранения неоднозначностей памяти выбирает операции
чтения, которые не зависят от других операций записи (write), что позволяет выполнить их раньше. Опять же, этот шаг позволяет максимально эффективно нагрузить конвейер процессора, в то же время несколько компенсируя влияние больших задержек памяти.



Слайд 118Улучшенная работа с цифровым медиа-содержанием
АЛУ обычно разбивает инструкции на два блока,
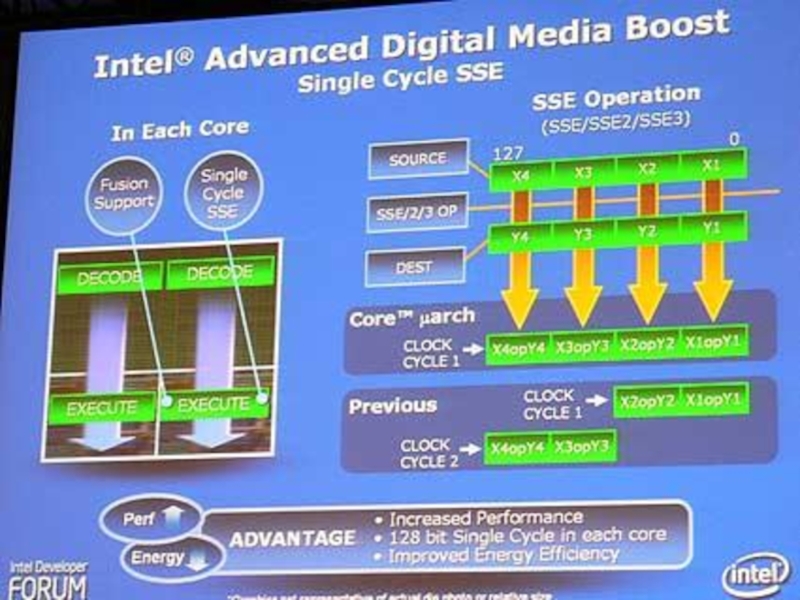
что приводит к двум микро-операциям и, соответственно, двум тактам выполнения. Intel решила расширить ширину выполнения трёх АЛУ до 128 бит, что позволяет обрабатывать за один такт восемь блоков с одинарной точностью или четыре блока с двойной точностью. Выполнение команд SSE за один такт (Single Cycle SSE). Например, можно объединить четыре 32-битных вектора в один 128-битный блок.

Слайд 121Архитектура Core i3 - i7
Основной чертой новой архитектуры стала модульность
Ядро это классический одноядерный x86-процессор: он состоит из исполнительного ядра, кэша 1-го уровня размером 64 КБ, поделенного на 2 равные части для данных и инструкций и кэша 2-го уровня размером 256 КБ.

Слайд 122Прочие блоки могут быть следующими:
разделяемый кэш 3-го уровня;
контроллер памяти;
контроллер шины QPI
(QuickPath Interconnect);
контроллер шины PCI Express;
контроллер энергопотребления (PCU) и генератор частот;
контроллер интегрированной графики
контроллер шины PCI Express;
контроллер энергопотребления (PCU) и генератор частот;
контроллер интегрированной графики
;контроллер шины PCI")
Слайд 123Core i3
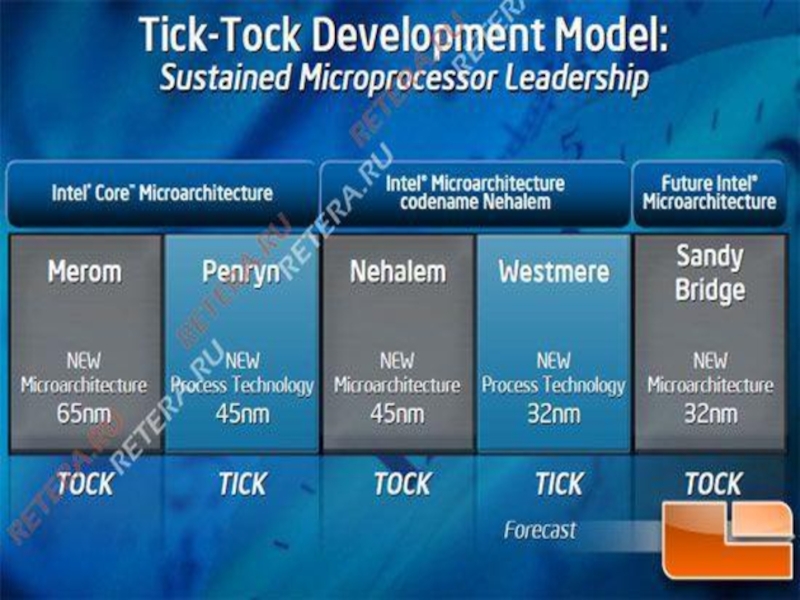
Компания Intel разработала в 2006 году концепцию Tick-Tock (тик-так). Суть
ее в том, что каждый год происходит обновление либо производственной технологии с усовершенствованием микроархитектуры, либо запуск совершенно новой микроархитектуры.
. Суть ее в том, что")
Слайд 125Core i3
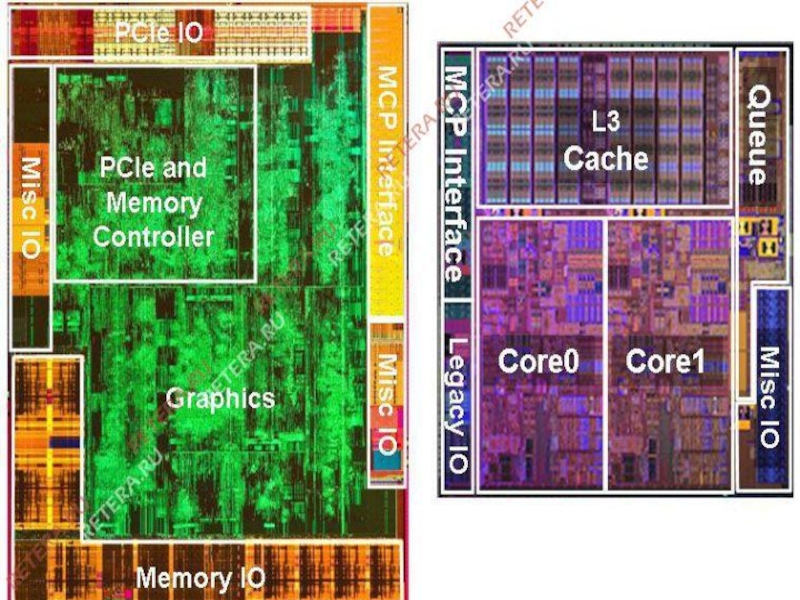
Самое основное отличие новых процессоров от предыдущих версий – это
двухкристальная структура. Суть данного решения в том, что в едином корпусе расположены сразу два кристалла. Первый – это выполненный по стандарту 32-нм непосредственно сам процессор. Второй кристалл выполнен уже по нормам 45-нм техпроцесса и содержит в себе встроенное графическое ядро, контроллер памяти и контроллер PCI Express. Вот так выглядит схематично процессор Westmere

Слайд 127ТЕХНОЛОГИИ CORE i3
Новая улучшенная версия Hyper-threading Simultaneous MultiThreading (SMT). Благодаря SMT
приложения с поддержкой многопоточности получают исчерпывающую базу для реализации заложенных в них возможностей, сокращая время обработки поставленных задач. Операционная система видит два ядра Core i3 как четыре, при этом, не разделяя их на физические и виртуальные.
. Благодаря SMT приложения с поддержкой многопоточности")
Слайд 129ТЕХНОЛОГИИ CORE i3
Для слежения за состоянием процессора, в нем был размещен
специальный микроконтроллер Power Control Unit (PCU), который отвечает за мониторинг и регулирование показателей напряжения, силы тока и температуры ядер, что позволяет значительно экономить энергию при неполной загрузке системы. Кроме того, PCU способен полностью отключать неактивные ядра.

Слайд 130ТЕХНОЛОГИИ CORE i3
Линейка процессоров Core i3, в отличии от более дорогих
Core i5/i7, не поддерживает технологию Turbo Boost, позволяющую увеличивать частоту рабочего ядра за счет полного или частичного отключения неактивных ядер. Номинальная частота процессора Core i3 является и его максимальной.

Слайд 131ТЕХНОЛОГИИ CORE i3
Virtualization Technology (VT) - Аппаратная виртуализация, позволяет запускать на
одном физическом компьютере несколько экземпляров операционных систем в целях обеспечения их независимости от аппаратной платформы и эмуляции нескольких (виртуальных) машин на одной физической.
 - Аппаратная виртуализация, позволяет запускать на одном физическом компьютере")
Слайд 132ТЕХНОЛОГИИ CORE i3
Execute Disable Bit обеспечивает защиту от вредоносных атак, направленных
на переполнение буфера. Эта технология позволяет процессору выделять области памяти, где допускается выполнение кода приложений. Когда вредоносная программа-червь пытается установить свой код в буфер памяти, процессор отключает выполнение кода, предотвращая ущерб и распространение инфицирующей программы.

Слайд 133ТЕХНОЛОГИИ CORE i3
Enhanced Intel SpeedStep - энергосберегающая технология Intel, вызывающая, в
зависимости от потребностей системы, динамическое (без перезагрузки системы) переключение напряжения, питания и частоты.

Слайд 134ТЕХНОЛОГИИ CORE i3
Trusted Execution состоит из последовательно защищённых этапов обработки. В
основе технологии лежит безопасное исполнение программного кода. Каждое приложение, работающее в защищённом режиме, имеет эксклюзивный доступ к ресурсам компьютера, и в его изолированную среду не сможет вмешаться никакое другое приложение. У вредоносной программы не будет возможности отследить поток данных на входе компьютера, а кейлоггер получит только бессмысленный набор символов, поскольку все процедуры ввода (включая передачу данных по USB и даже мышиные клики) будут зашифрованы.

Слайд 135ТЕХНОЛОГИИ CORE i3
Intel 64 Architecture поддерживает 64-битные вычисления, что позволяет устанавливать
и использовать 64-битные версии операционных систем.

Слайд 136ГРАФИЧЕСКОЕ ЯДРО
Графический чип Intel HD Graphics так же использует систему из
унифицированных конвейеров. Производительность новой интегрированной графики возросла за счет увеличения количества блоков скалярных вычислений с 10 до 12. Есть поддержка DirectX 10, OpenGL 2.1 и Shader Model 4.0.

Слайд 137ГРАФИЧЕСКОЕ ЯДРО
Графический чип находится на общем кристалле с контроллером памяти, что
позволит производить обмен данными на скорости 17.1 GB/s.
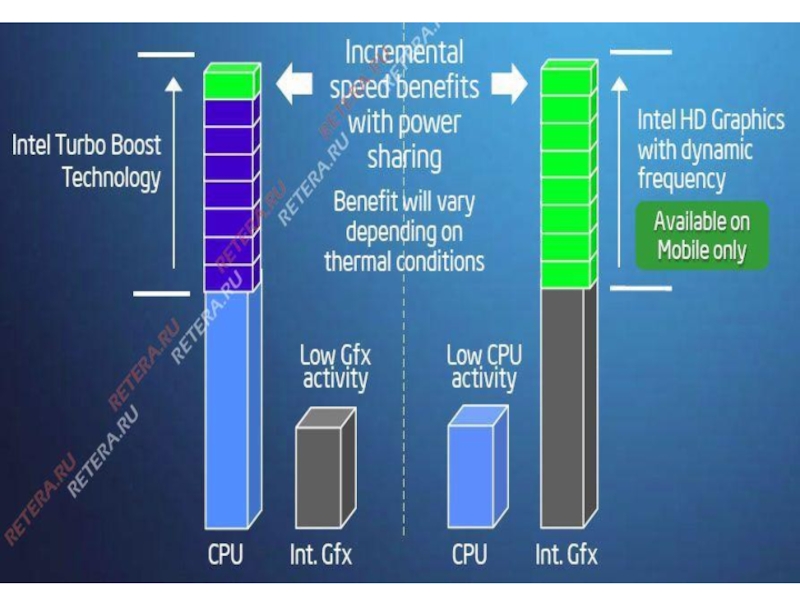
Использование технологии HD Graphics Turbo Boost. Данная разработка позволяет в зависимости от ситуации динамическим образом изменять частоту графического чипа с 133 до 667 МГц. Но при этом используется одно ограничение: суммарное тепловыделение процессора и графического чипа не должны превышать заявленных 35 Ватт. Таким образом, происходит распределение теплового пакета между CPU и GPU.
Использование технологии HD Graphics Turbo Boost. Данная разработка позволяет в зависимости от ситуации динамическим образом изменять частоту графического чипа с 133 до 667 МГц. Но при этом используется одно ограничение: суммарное тепловыделение процессора и графического чипа не должны превышать заявленных 35 Ватт. Таким образом, происходит распределение теплового пакета между CPU и GPU.


Слайд 140Core i7 920
Трёхканальный контроллер памяти DDR3 с максимальной скоростью 32 GBps
Процессорная шина Intel (QuickPath Interconnect) - 20-битная шина с топологией соединения «точка-точка», 16 бит в каждую сторону несут полезную информацию, и ещё 4 бита служат для коррекции ошибок и прочих служебных целей обеспечивает скорость передачи данных 12,8 ГБ/с в каждую сторону

Слайд 141Core i7 920
Управление энергопотреблением
частота и напряжение питания для каждого ядра
регулируются отдельно на основании данных о его температуре и силе потребляемого тока. Таким образом, каждое ядро может быть переведено в состояние пониженного энергопотребления отдельно от других, а контроллеры памяти и шины QPI переводятся в состояние пониженного энергопотребления в случае когда все ядра находятся в незагруженном работой состоянии

Слайд 142Core i7 920
Управление энергопотреблением
Технология Turbo Boost процессора может повышать частоту
работы одного или нескольких ядер в том случае, если остальные простаивают

Слайд 143Подсистема кэширования
L2 является «персональной собственностью» конкретного ядра, и оно ни с
кем его не делит — разделяемым и общим для всех является кэш следующего уровня — L3.
L3 является динамически разделяемым. Более того, он является инклюзивным: данные, находящиеся в L1/L2 — обязаны присутствовать в L3.
L3 является динамически разделяемым. Более того, он является инклюзивным: данные, находящиеся в L1/L2 — обязаны присутствовать в L3.








