вычислительных систем
Методы повышения быстродействия компьютеров
Формы параллелизма
Классификация вычислительных систем
Флинна
Хокни
Фенга
Дункана
Шнайдера
Примеры реализации принципов параллелизма и конвейеризации
Организация мультипроцессорных и мультикомпьютерных систем
Основные классы современных параллельных компьютеров
Языки параллельного программирования
- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Оценка современных компьютеров презентация
Содержание
- 1. Оценка современных компьютеров
- 2. Основные причины возникновения узких мест в компьютере
- 3. Производительность как вид эффективности вычислительных систем Под
- 4. Производительность как вид эффективности вычислительных систем Производительность
- 5. Виды производительности Техническая производительность устройства – это
- 6. Виды производительности Комплексная производительность показывает, какая часть
- 7. Цели и основные этапы анализа производительности Методология
- 8. CRT PMS, ISP, SVC PS, JOB TASK
- 9. Основные задачи оценки производительности Сравнительная оценка существующих систем. Оптимизация. Прогнозирование производительности.
- 10. Описание рабочей нагрузки Без хорошего знания рабочей
- 11. Виды моделей рабочей нагрузки Смеси команд: Заключается
- 12. Виды моделей рабочей нагрузки Стохастические модели рабочей
- 13. Виды моделей рабочей нагрузки Трассы: Рабочую нагрузку
- 14. Модели системы Структурные модели характеризуют составные части
- 15. Функциональные модели вычислительных систем Делятся на четыре
- 16. Функциональные модели вычислительных систем Делятся на четыре
- 17. Функциональные модели вычислительных систем Делятся на четыре
- 18. Модели производительности Аналитические модели Аналитическая модель производительности
- 19. Способы получения данных Делятся на четыре группы:
- 20. Измерение параметров функционирование систем Концепция наблюдателя Наблюдатель
- 21. Измерение параметров функционирование систем Описание поведения программ.
- 22. Трассы Исследуемое действие Ak описывается тройкой: (Ak
- 23. Относительная активность Относительная активность – показывает какую
- 24. Частотные характеристики действия Основной характеристикой является частота
- 25. Статистические характеристики действия Действие характеризуется функцией распределения
- 26. Измерение параметров функционирование систем Виды наблюдателей.
- 27. Основные виды производительности Производительность (быстродействие) ЭВМ –
- 28. Методы определения быстродействия расчетные, основанные на
- 29. Оценка производительности вычислительных систем Если несколько процессоров
- 30. Оценка производительности вычислительных систем Если P0 –
- 31. Подходы к формированию тестов определения производительности Смеси
- 32. Основные проблемы, связанные с анализом результатов контрольного
- 33. Группы тестов для измерения реальной производительности Тесты
- 34. Стандартные тесты LinPack - совокупность программ для
- 35. Пакет SPEC 89 Включает два тестовых набора
- 36. Оценка надежности вычислительных систем Под надежностью ВС
- 37. Дерево логических возможностей Дерево логических возможностей
- 38. Коэффициент готовности КГ T0 – суммарное время
- 39. Расчет модели надежности. Пусть λ1 – частота
- 40. Защита от сбоев. Двойной просчет характерен для
- 41. Резервирование Резервирование не отдельной ЭВМ, а всего
- 42. Реакция системы автоматического регулирования на аварии Аппаратно
- 43. Методы повышения быстродействия компьютеров Существуют три способа
- 44. Конвейеризация Этапы конвейера: IF (Instruction Fetch) -
- 45. Пусть для выполнения отдельных стадий обработки требуются
- 46. Эффективность конвейерной обработки Под эффективностью обработки понимается
- 47. Повышение быстродействия элементной базы 1. Уменьшение (укорачивание)
- 48. 2. Снижение площади транзистора, что должно
- 50. 4. Уменьшение площади занимаемой транзистором. Размещение
- 51. 5. Увеличение числа ядер процессоров и объема
- 52. Формы параллелизма Распараллеливание операций – перспективный путь
- 53. Закон Мура Зако́н Му́ра — эмпирическое — эмпирическое наблюдение,
- 54. Уровни параллелизма
- 55. Зависимость по данным Параллелизм – это возможность
- 56. Зависимость по данным Нарушение условия в первом
- 57. Информационный граф задачи Наиболее общей формой
- 58. Ярусно-параллельная форма Более определенной формой представления параллелизма
- 59. Мелкозернистый (скалярный) параллелизм При исполнении программы регулярно
- 60. Пример мелкозернистого параллелизма Пусть имеется программа для
- 61. Крупнозернистый параллелизм Векторный параллелизм. Наиболее распространенной в
- 62. Параллелизм независимых ветвей Суть параллелизма независимых ветвей
- 63. Параллелизм вариантов Это широко распространенный в практике
- 64. Закон Амдала Одной из главных характеристик параллельных
- 65. Следствия закона Амдала Закон Амдала определяет принципиально
- 66. Сетевой закон Амдала Основной вариант закона Амдала
- 67. Особенности многопроцессорных вычислений на основе закона Амдала
- 68. Вычислительные системы Компьютерные с общей памятью (мультипроцессорные
- 69. Мультипроцессорные системы Первый класс – это компьютеры
- 70. Параллельные компьютеры с общей памятью
- 71. Мультикомпьютерные системы Второй класс — это компьютеры
- 72. Параллельные компьютеры с распределенной памятью
- 73. Blue Gene/L Расположение: Ливерморская национальная лаборатория имени
- 74. Задачи параллельных вычислений Построении вычислительных систем с
- 75. Организация мультипроцессорных систем (общая шина) Мультипроцессорная система
- 76. Организация мультипроцессорных систем (матричный коммутатор)
- 77. Организация мультипроцессорных систем Мультипроцессорная система с омега-сетью
- 78. Топологические связи модулей ВС Выбор той
- 79. Варианты топологий связи процессоров и ВМ NUMA Non Uniform Memory Access
- 80. Топология двоичного гиперкубы В n-мерном пространстве в
- 81. Достоинства и недостатки компьютеров с общей и
- 82. Классификация вычислительных систем Классификация Флинна Классификация
- 83. Классификация Флина Базируется на понятии потока, под
- 84. Архитектуры ЭВМ MIMD-архитектура MISD-архитектура SIMD- архитектура SISD- архитектура
- 85. Недостатки классификации Флина Некоторые архитектуры четко не вписываются в данную классификацию Чрезмерная заполненность класса MIMD
- 86. Классификация Хокни Основная идея классификации состоит в
- 87. Классификация Хокни
- 88. Примеры классификации Флина SISD – PDP-11, VAX
- 89. Классификация Фенга Идея классификации вычислительных систем на
- 90. Классификация Фенга Любую вычислительную систему C можно
- 91. Примеры классификации Фенга Разрядно-последовательные пословно-последовательные (n=m=1): MINIMA
- 92. Недостаток не делает никакого различия между процессорными
- 93. Классификация Дункана Дункан определил набор требований для
- 94. Классификация Дункана
- 95. Основные архитектуры, представленные на рисунке рисунка Систолические
- 96. Классификация Хендлера Предложенная классификация базируется на различии
- 97. Классификация Хендлера t(C) = (k, d, w)
- 98. Дополнения к классификации Хендлера Хендлер предлагает использовать
- 99. Примеры классификации Хендлера t( MINIMA ) =
Слайд 1Оценка современных компьютеров
«Узкие места» современных ЭВМ
Оценка производительности
Оценка эффективности
Методы повышения производительности

Слайд 2Основные причины возникновения узких мест в компьютере
состав, принцип работы и
временные характеристики арифметико-логического устройства;
состав, размер и временные характеристики устройств памяти;
структура и пропускная способность коммуникационной среды;
компилятор, создающий неэффективные коды;
операционная система, организующая неэффективную работу с памятью, особенно медленной.
состав, размер и временные характеристики устройств памяти;
структура и пропускная способность коммуникационной среды;
компилятор, создающий неэффективные коды;
операционная система, организующая неэффективную работу с памятью, особенно медленной.

Слайд 3Производительность как вид эффективности вычислительных систем
Под эффективностью системы понимается соответствие системы
своему назначению или соответствие поведения (функционирования) системы, обеспечивающее достижение цели, для которой она применяется.
виды эффективности
производительность
надежность
отказоустойчивость

Слайд 4Производительность как вид эффективности вычислительных систем
Производительность – вид эффективности вычислительной системы,
определяющий ее вычислительную мощность через количество вычислительных услуг, обеспечиваемых системой в единицу времени.
Производительность
эффективность системы для конкретного применения
внутренняя эффективность системы

Слайд 5Виды производительности
Техническая производительность устройства – это количество операций, которое это устройство
способно выполнить в единицу времени.
Совокупность технических производительностей устройств, входящих в состав системы, называют технической производительностью вычислительной системы.
Техническая производительность характеризует лишь потенциальные возможности устройства, которые на самом деле не могут быть использованы полностью.
Совокупность технических производительностей устройств, входящих в состав системы, называют технической производительностью вычислительной системы.
Техническая производительность характеризует лишь потенциальные возможности устройства, которые на самом деле не могут быть использованы полностью.

Слайд 6Виды производительности
Комплексная производительность показывает, какая часть от технической производительности каждого устройства
может быть использована при их совместной работе, при условии максимальной загрузки, т.е. сбалансированность технических производительностей устройств.
Производительность, проявляемую вычислительной системой при совместной работе прикладной программы, программного обеспечения данной вычислительной системы и ее аппаратуры называется системной производительностью. Системная производительность зависит от каждого из трех основных компонентов вычислительной системы: рабочей нагрузки, а также физической и логической сред.
Системная производительность дает полную характеристику вычислительной системе как комплекса программных и аппаратных средств.

Слайд 7Цели и основные этапы анализа производительности
Методология оценки производительности состоит из последовательности
этапов.
Сначала производиться выбор меры производительности, то есть тех параметров, по которым будет вычисляться оценка.
Сначала производиться выбор меры производительности, то есть тех параметров, по которым будет вычисляться оценка.
После этого определяется зависимость производительности от структуры анализируемой системы и ее рабочей нагрузки.
Строится модель рабочей нагрузки и модель вычислительной системы.
С помощью моделей рабочей нагрузки и вычислительной системы строится модель производительности с выбранными параметрами рабочей нагрузки и вычислительной системы.


Слайд 9Основные задачи оценки производительности
Сравнительная оценка существующих систем.
Оптимизация.
Прогнозирование производительности.

Слайд 10Описание рабочей нагрузки
Без хорошего знания рабочей нагрузки, анализ и прогноз производительности
в лучшем случае будут неточны.
предоставить корректную, адекватную и представительную характеристику прикладного процесса для прогнозирования его поведения на классе систем настолько широком, насколько это возможно;
обеспечить управляемые и воспроизводимые эксперименты при оценке производительности;
сократить настолько, насколько это возможно количество анализируемых данных без ущерба точности анализа;
предоставить данные в форме, пригодной для их использования моделью системы.
Основные функции модели рабочей нагрузки:

Слайд 11Виды моделей рабочей нагрузки
Смеси команд:
Заключается в выборе последовательности команд машины, "типичной"
с точки зрения некоторого приложения. "Типичность" определяется через функцию распределения встречаемости команд в программе для определенного приложения. Эту функцию строят методами математической статистики, например, с помощью кластерного или регрессионного анализов.
смеси команд; эталоны; стохастические модели; трассы.
Эталоны:
Эталоны – это образцы использования ресурсов системы прикладным процессом, т.е. эталоны рабочей нагрузки для определенной вычислительной системы или ее прототипа. В качестве эталонов обычно выступают отдельные программы или наборы программ. Эталоны могут быть построены из уже существующих программ. Способы построения эталонов могут быть самыми разными: от случайного выбора программ на входе системы до тщательного подбора каждого оператора в эталоне.

Слайд 12Виды моделей рабочей нагрузки
Стохастические модели рабочей нагрузки:
Рабочую нагрузку описывают с помощью
случайных величин, которые представляют запросы на ресурсы. Распределения этих случайных величин подбираются на основе статистического анализа результатов измерений потока запросов на соответствующие ресурсы реально действующей вычислительной установки.
смеси команд; эталоны; стохастические модели; трассы.
Недостатки:
данные, собираемые на действующей установке, могут нести на себе отпечаток той системы, на которой они собирались (системная зависимость);
измерительная система, используемая для сбора данных, может искажать собираемые данные настолько, насколько она сама использует ресурсы системы (оценить это влияние практически не возможно);
трудно охватить взаимосвязи между разными характеристиками потока запросов, представленных разными случайными величинами (используется гипотеза о статистической независимости случайных величин, что является не корректным).
Использование данного подхода очень ограничено.

Слайд 13Виды моделей рабочей нагрузки
Трассы:
Рабочую нагрузку представляют в виде множества упорядоченных записей,
содержащих данные о работе программ. Эти данные собирают с помощью специальных измерительных средств, а затем, после специальной обработки, используют как модель рабочей нагрузки. Главным достоинством этого подхода является то, что он сохраняет все взаимозависимости между действиями, как отдельной программы, так и комплекса программ.
смеси команд; эталоны; стохастические модели; трассы.
Недостатки:
при измерениях всегда существует вероятность искажения измеряемых данных;
измерения носят системно-зависимый характер;
создание программ предварительной обработки трассы и подготовки ее к использованию моделью системы очень трудоемко.
Применялся только к программам в нераспределенной вычислительной среде.

Слайд 14Модели системы
Структурные модели характеризуют составные части системы, взаимосвязи и интерфейсы между
ними. Функциональные модели описывают поведение системы в форме пригодной для их исследования математическими методами. Модели производительности определяют зависимость производительности от таких параметров системы как рабочая нагрузка, структура и т.п.
структурные модели; функциональные модели; модели производительности.
Структурные модели вычислительных систем:
Строятся с помощью различного рода структурных диаграмм, использующих теорию графов. Эти модели описывают топологию информационных и управляющих потоков в системе, но не определяют их взаимное влияние друг на друга.

Слайд 15Функциональные модели вычислительных систем
Делятся на четыре группы:
графовые модели;
конечные автоматы;
сети;
модели с очередями.
структурные
модели; функциональные модели; модели производительности.
Графовые модели:
Теория графов широко используется при моделировании как программных, так и аппаратных компонентов вычислительных систем. В этих моделях вершины представляют отдельные программы, модули, либо операторы, а дуги – передачу управления между ними. Иногда дуги соответствуют фрагментам программ, а вершины – это точки ветвления, либо передачи управления.
Даже для небольших программ в несколько десятков операторов пространство всевозможных состояний достигает таких размеров, что работа с ним требует значительных вычислительных затрат.

Слайд 16Функциональные модели вычислительных систем
Делятся на четыре группы:
графовые модели;
конечные автоматы;
модели с очередями;
сети.
структурные
модели; функциональные модели; модели производительности.
Конечные автоматы:
В моделях, построенных на основе теории автоматов, состояние системы строят из локальных состояний отдельных ее компонентов, что позволяет достаточно просто учитывать параллельное функционирование отдельных частей системы
Модели с очередями:
Модели с очередями основываются на теории массового обслуживания. В этих моделях вычислительная система представляет из себя множество ресурсов – обрабатывающих приборов и очередей к ним.

Слайд 17Функциональные модели вычислительных систем
Делятся на четыре группы:
графовые модели;
конечные автоматы;
модели с очередями;
сети.
структурные
модели; функциональные модели; модели производительности.
Сети:
Наиболее популярной моделью стали сети Петри и ее обобщения. В этой модели и ее обобщениях основные трудности преодолевались за счет трех основных характеристик:
один шаг в развитии системы определялся не на общем или глобальном состоянии системы, а только на состоянии тех ее компонентов, от которых он зависел и где происходили какие-то изменения;
моделировалось только управление;
модель графическая.

Слайд 18Модели производительности
Аналитические модели
Аналитическая модель производительности определяется аналитическим выражением:
P=S(w),
где w – модель
рабочей нагрузки, а S(w) – модель системы, получаемая из функциональной модели применительно к конкретной модели рабочей нагрузки.
структурные модели; функциональные модели; модели производительности.
Эмпирические модели
Эмпирические модели производительности строятся на основе анализа данных, полученных при измерении параметров рабочей нагрузки и соответствующих значений производительности системы. Эмпирические данные это одна из форм представления временной диаграммы использования ресурсов системы в интересующем пользователей аспекте. Эмпирическая модель может быть представлена либо в виде таблицы, либо в виде графика и т.п., то есть в любой из форм представления функций. Саму функцию можно построить с помощью регрессионного анализа.
,где w – модель рабочей нагрузки, а S(w)")
Слайд 19Способы получения данных
Делятся на четыре группы:
экспериментальный;
численное решение функциональной модели;
использование эмулятора анализируемой
системы;
имитационное моделирование.
имитационное моделирование.

Слайд 20Измерение параметров функционирование систем
Концепция наблюдателя
Наблюдатель может быть внутренним либо внешним.
Внешний наблюдатель
рассматривает систему как "черный ящик", который содержит ограниченное число известных функций. Наблюдение сводится к измерению изменений в реакции системы при контролируемых изменениях рабочей нагрузки.
Внутренний наблюдатель обеспечивает измерения и контроль за изменениями, происходящими внутри системы.
Наблюдаемое поведение системы есть последовательность изменений наблюдаемых состояний системы. Наблюдаемое состояние, отражающее поведение системы даже на самом нижнем уровне системы – это состояние всех запоминающих элементов в системе: основной памяти, регистровой, внешней, регистровой памяти внешних устройств и т.д. Обычно в понятие состояния системы включают лишь память, отражающую значения объектов в программе.
Внутренний наблюдатель обеспечивает измерения и контроль за изменениями, происходящими внутри системы.
Наблюдаемое поведение системы есть последовательность изменений наблюдаемых состояний системы. Наблюдаемое состояние, отражающее поведение системы даже на самом нижнем уровне системы – это состояние всех запоминающих элементов в системе: основной памяти, регистровой, внешней, регистровой памяти внешних устройств и т.д. Обычно в понятие состояния системы включают лишь память, отражающую значения объектов в программе.

Слайд 21Измерение параметров функционирование систем
Описание поведения программ.
денотационный. – Программа рассматривается как отображение
Ф: X=>Y, где X – исходные данные, а Y – результаты (акцент ставится на преобразовании программой данных). Отображение состоит из последовательности отображений {Фi}, реализуемых операторами программы, которые изменяют значения ее переменных.
операционный. – Динамика программы рассматривается как последовательность событий (под событием понимается смена состояния). В этом походе значительно расширяется понятие состояния. В него включены не только непосредственно память программы, но и другие виды памяти в системе.
Данные, собираемые в ходе измерений, можно подразделить по форме на четыре категории: трассы, относительная активность, частотные характеристики действий и статистические (усредненные) характеристики действий.
операционный. – Динамика программы рассматривается как последовательность событий (под событием понимается смена состояния). В этом походе значительно расширяется понятие состояния. В него включены не только непосредственно память программы, но и другие виды памяти в системе.
Данные, собираемые в ходе измерений, можно подразделить по форме на четыре категории: трассы, относительная активность, частотные характеристики действий и статистические (усредненные) характеристики действий.

Слайд 22Трассы
Исследуемое действие Ak описывается тройкой:
(Ak , ti , Ti ),
где Ak
– признак исследуемого действия либо соответствующее ему событие;
ti – время начала i-го наступления действия;
Ti – продолжительность i-го действия.
ti – время начала i-го наступления действия;
Ti – продолжительность i-го действия.
, где Ak – признак исследуемого действия")
Слайд 23Относительная активность
Относительная активность – показывает какую часть времени от общего времени
работы программы заняло время выполнения действия Ak
где ak(t)=1, если система находится в состоянии, соответствующем выполнению действия Ak ; и
ak(t)=0 в противном случае;
t и t0 – моменты начала и окончания измерения, причем t>t0.

Слайд 24Частотные характеристики действия
Основной характеристикой является частота выполнения исследуемого действия, сk ,
измеряемая числом событий ek , инициирующих действие Ak .
где t>tn>t0
ek(t )=1 если t=n и
ek(t )=0, в противном случае;
tn – время наступления ek .

Слайд 25Статистические характеристики действия
Действие характеризуется функцией распределения времени его выполнения, если оно
изменяется от одного его выполнения к другому.
Пусть – функция распределения времени выполнения действия Ak к моменту окончания его n-го наступления, тогда:
Пусть – функция распределения времени выполнения действия Ak к моменту окончания его n-го наступления, тогда:
где T – длительность i-го наступления Ak ;
g(T1 ,T2 )=1 если T1=T2 и
g(T1 ,T2 )=0 в противном случае.

Слайд 26Измерение параметров функционирование систем
Виды наблюдателей.
Все средства наблюдения за информационными потоками в
вычислительных системах можно подразделить на программные, микропрограммные и аппаратные
Программный наблюдатель – это специализированная программа (или комплекс программ), встроенная в измеряемую систему. Наблюдатель выступает посредником между теми компонентами системы, за которыми он наблюдает. Программный наблюдатель всегда изменяет измеряемую систему.
Микропрограммные наблюдатели. С микропрограммного уровня доступны такие индикаторы аппаратуры, которые с вышележащих уровней не доступны. Недостатки: использование специализированной дорогостоящей аппаратуры; события, возникающие в системе на столь низком уровне, трудно транслировать в события более высокого уровня, на котором обычно работает программист.
Аппаратные наблюдатели подразделяются на внутренние и внешние. Внешний аппаратный наблюдатель подключается к определенным точкам системы, "подслушивает" сигналы на ее линиях, обрабатывает и записывает их у себя, вне измеряемой системы. Аппаратный наблюдатель представляет собой совершенно автономную систему, которая не нуждается ни в какой помощи со стороны измеряемой системы. Он практически не вмешивается в ее работу, а, стало быть, не изменяет ее поведения.
Программный наблюдатель – это специализированная программа (или комплекс программ), встроенная в измеряемую систему. Наблюдатель выступает посредником между теми компонентами системы, за которыми он наблюдает. Программный наблюдатель всегда изменяет измеряемую систему.
Микропрограммные наблюдатели. С микропрограммного уровня доступны такие индикаторы аппаратуры, которые с вышележащих уровней не доступны. Недостатки: использование специализированной дорогостоящей аппаратуры; события, возникающие в системе на столь низком уровне, трудно транслировать в события более высокого уровня, на котором обычно работает программист.
Аппаратные наблюдатели подразделяются на внутренние и внешние. Внешний аппаратный наблюдатель подключается к определенным точкам системы, "подслушивает" сигналы на ее линиях, обрабатывает и записывает их у себя, вне измеряемой системы. Аппаратный наблюдатель представляет собой совершенно автономную систему, которая не нуждается ни в какой помощи со стороны измеряемой системы. Он практически не вмешивается в ее работу, а, стало быть, не изменяет ее поведения.

Слайд 27Основные виды производительности
Производительность (быстродействие) ЭВМ – среднестатистическое число операций, выполняемых вычислительной
машиной в единицу времени.
Производительность можно подразделить на пиковую (предельная), номинальную и реальную:
Пиковая производительность (быстродействие) определяется средним числом команд типа «регистр-регистр», выполняемых в одну секунду без учета их статистического веса в выбранном классе задач.
Номинальная производительность определяется средним числом команд, выполняемых вычислительной системой, при использовании подсистемы памяти для доступа за операндами и командами программы.
При выполнении реальных прикладных программ может быть определена эффективная (реальная) производительность компьютера, Для оценки производительности различных вычислительных средств в мировой практике наибольшее распространение получило использование наборов, характерных для выбранной области применения вычислительной техники, задач.
Производительность можно подразделить на пиковую (предельная), номинальную и реальную:
Пиковая производительность (быстродействие) определяется средним числом команд типа «регистр-регистр», выполняемых в одну секунду без учета их статистического веса в выбранном классе задач.
Номинальная производительность определяется средним числом команд, выполняемых вычислительной системой, при использовании подсистемы памяти для доступа за операндами и командами программы.
При выполнении реальных прикладных программ может быть определена эффективная (реальная) производительность компьютера, Для оценки производительности различных вычислительных средств в мировой практике наибольшее распространение получило использование наборов, характерных для выбранной области применения вычислительной техники, задач.
 ЭВМ – среднестатистическое число операций, выполняемых вычислительной машиной в единицу времени.Производительность")
Слайд 28Методы определения быстродействия
расчетные, основанные на информации, получаемой теоретическим или эмпирическим
путем;
экспериментальные, основанные на информации, получаемой с использованием аппаратно-программных измерительных средств;
имитационные, применяемые для сложных ЭВМ.
экспериментальные, основанные на информации, получаемой с использованием аппаратно-программных измерительных средств;
имитационные, применяемые для сложных ЭВМ.

Слайд 29Оценка производительности вычислительных систем
Если несколько процессоров составляют вычислительную систему (ВС), то
важной характеристикой ее эффективности при специализированном использовании (например, в составе АСУ) является коэффициент загрузки процессоров kЗ
Ti (i=1, … , n) – время занятости каждого процессора решением задачи на всем отрезке полного решения задачи, длиной Треш.
, то важной характеристикой ее эффективности")
Слайд 30Оценка производительности вычислительных систем
Если P0 – производительность одного процессора, то реальная
производительность ВС, состоящей из n процессоров, при решении данной задачи составляет:
P0 - определяется классом решаемых задач

Слайд 31Подходы к формированию тестов определения производительности
Смеси операций различных типов в случайном
порядке, отражающие их процентное соотношение в задачах интересующего класса.
Ядра. Ядро – небольшая программа, часть решаемой задачи. Характеристики ядра могут быть точно измерены. Известны ядра Ауэрбаха: коррекция последовательного файла и файла на диске, сортировка, обращение матрицы и др.
Бенчмарки – реальные программы, характеристики которых можно оценить или измерить при использовании. Обычно берут из числа тех, для которых разрабатывается система.
Программа синтетической нагрузки – параметрически настраиваемая программа, представляющая смеси определенных программных конструкций.
Модель вычислительной нагрузки. Модель позволяет перейти с уровня оценки одного процессора ВС на уровень комплексной оценки ВС. Составляется и параметризуется с учетом сложной структуры ВС и ее устройств, параллельного участия этих устройств в решении задач, доли участия и порядка взаимодействия устройств.
Сравнительные оценки исследуемой ВС с другими ЭВМ или ВС, для которых уже известны значения производительности по числу операций в секунду. Используется сравнительная оценка характеристик решения задачи на исследуемой ВС и на ВС или ЭВМ, для которой уже известны характеристики производительности.
Ядра. Ядро – небольшая программа, часть решаемой задачи. Характеристики ядра могут быть точно измерены. Известны ядра Ауэрбаха: коррекция последовательного файла и файла на диске, сортировка, обращение матрицы и др.
Бенчмарки – реальные программы, характеристики которых можно оценить или измерить при использовании. Обычно берут из числа тех, для которых разрабатывается система.
Программа синтетической нагрузки – параметрически настраиваемая программа, представляющая смеси определенных программных конструкций.
Модель вычислительной нагрузки. Модель позволяет перейти с уровня оценки одного процессора ВС на уровень комплексной оценки ВС. Составляется и параметризуется с учетом сложной структуры ВС и ее устройств, параллельного участия этих устройств в решении задач, доли участия и порядка взаимодействия устройств.
Сравнительные оценки исследуемой ВС с другими ЭВМ или ВС, для которых уже известны значения производительности по числу операций в секунду. Используется сравнительная оценка характеристик решения задачи на исследуемой ВС и на ВС или ЭВМ, для которой уже известны характеристики производительности.

Слайд 32Основные проблемы, связанные с анализом результатов контрольного тестирования производительности
отделение показателей,
которым можно доверять безоговорочно, от тех, которые должны восприниматься с известной долей настороженности (проблема достоверности оценок);
выбор контрольно-оценочных тестов, наиболее точно характеризующих производительность при обработке типовых задач пользователя (проблема адекватности оценок);
правильное истолкование результатов тестирования производительности, особенно если они выражены в довольно экзотических единицах типа MWIPS, Drystones/s и т.д. (проблема интерпретации).
выбор контрольно-оценочных тестов, наиболее точно характеризующих производительность при обработке типовых задач пользователя (проблема адекватности оценок);
правильное истолкование результатов тестирования производительности, особенно если они выражены в довольно экзотических единицах типа MWIPS, Drystones/s и т.д. (проблема интерпретации).

Слайд 33Группы тестов для измерения реальной производительности
Тесты производителей (тесты, подготовленные компаниями разработчика
ВС).
Стандартные тесты (тестовые программы, основанные на выполнении стандартных операций и не зависящие от платформы ВС
Пользовательские тесты (учитывают конкретную специфику применения ВС)
Стандартные тесты (тестовые программы, основанные на выполнении стандартных операций и не зависящие от платформы ВС
Пользовательские тесты (учитывают конкретную специфику применения ВС)
HPC Challenge Benchmark
. Стандартные тесты (тестовые")
Слайд 34Стандартные тесты
LinPack - совокупность программ для решения задач линейной алгебры
В качестве
параметров используются: порядок матрицы, формат значений элементов матрицы, способ компиляции.
SPEC XX - два тестовых набора Cint89 и Cfp89.
SPEC 98 – четыре программы целочисленной обработки шесть программ с операциями на числами с плавающей запятой.
SPEC 92 – 6 эталонных тестов, а также 14 реальных прикладных программ
SPEC 95 – расширен набор тестовых программ, а также добавлена возможность тестирования многопроцессорных ВС.
современные тесты SPEC – тестирование многомашинных и многопроцессорных вычислительных комплексов.
TPC – оценка производительности систем при работе с базами данных. Тестирование позволяет определить:
а. производительность обработки запросов QppD (Query Processing Performance), измеряемая количеством запросов, которое может быть обработано при монопольном использовании всех ресурсов тестируемой системы;
б. пропускная способность системы QthD (Query Throughput), измеряемая количеством запросов, которое система в состоянии совместно обрабатывать в течение часа;
в. отношение стоимости к производительности $/QphD, измеряемое как стоимость 5-летней эксплуатации системы, отнесенная к числу запросов, обработанных в час.
SPEC XX - два тестовых набора Cint89 и Cfp89.
SPEC 98 – четыре программы целочисленной обработки шесть программ с операциями на числами с плавающей запятой.
SPEC 92 – 6 эталонных тестов, а также 14 реальных прикладных программ
SPEC 95 – расширен набор тестовых программ, а также добавлена возможность тестирования многопроцессорных ВС.
современные тесты SPEC – тестирование многомашинных и многопроцессорных вычислительных комплексов.
TPC – оценка производительности систем при работе с базами данных. Тестирование позволяет определить:
а. производительность обработки запросов QppD (Query Processing Performance), измеряемая количеством запросов, которое может быть обработано при монопольном использовании всех ресурсов тестируемой системы;
б. пропускная способность системы QthD (Query Throughput), измеряемая количеством запросов, которое система в состоянии совместно обрабатывать в течение часа;
в. отношение стоимости к производительности $/QphD, измеряемое как стоимость 5-летней эксплуатации системы, отнесенная к числу запросов, обработанных в час.
SPECratio
SPECmark
Sun Ultra5-10

Слайд 35Пакет SPEC 89
Включает два тестовых набора — Cint89, состоящий из четырех
программ целочисленной обработки, и Cfp89, объединяющий шесть программ со значительным объемом операций над числами с плавающей точкой.
Методика оценки производительности SPEC 89 предполагает формирование десяти дифференциальных оценок SPECratioi, каждая из которых определяется как отношение времени выполнения программы № i из наборов Cint89 и Cfp89 на тестируемом компьютере ко времени выполнения той же программы на ЭВМ DEC VAX 11/780.
Интегральной характеристикой производительности компьютера служит показатель SPECmark, являющийся средним геометрическим всех десяти частных оценок SPECratio.
К параметру SPECmark добавлены еще две оценки – SPECint89 и SPECfp89, раздельно характеризующие быстродействие компьютера при обработке целочисленных данных и вещественных чисел.

Слайд 36Оценка надежности вычислительных систем
Под надежностью ВС понимается вероятность решения поставленной перед
ней задачи.
Надежность ВС в составе сложной системы управления определяется следующими факторами:
вероятностью пребывания в исправном состоянии в момент начала цикла управления;
вероятностью пребывания в исправном состоянии в течение всего цикла управления;
помехоустойчивостью, т.е. способностью с допустимыми потерями временных, точностных и аппаратурных ресурсов на требуемом качественном уровне завершить цикл управления при возникновении неисправностей.
Надежность ВС в составе сложной системы управления определяется следующими факторами:
вероятностью пребывания в исправном состоянии в момент начала цикла управления;
вероятностью пребывания в исправном состоянии в течение всего цикла управления;
помехоустойчивостью, т.е. способностью с допустимыми потерями временных, точностных и аппаратурных ресурсов на требуемом качественном уровне завершить цикл управления при возникновении неисправностей.

Слайд 37Дерево логических возможностей
Дерево логических возможностей строится следующим образом. При исходе из
одной вершины на каждом уровне ветвления вводится исчерпывающее множество событий, т.е. сумма их вероятностей равна единице. Вероятности событий проставляются на дугах. Тогда вероятность интересующей нас совокупности событий находится как сумма произведений вероятностей, отмечающих пути, которые ведут к данным событиям. Пример проиллюстрирует сказанное выше.

Слайд 38Коэффициент готовности КГ
T0 – суммарное время работы вычислительной системы;
Tвосст – среднее
время восстановления (в т.ч. ремонта) после отказа.
Возможны три варианта:
в течение всего времени t решения задачи (t – цикл управления) ВС работала безотказно. Т.е. без каких-либо осложнений задача решена в предположении, что программы составлены правильно;
произошел сбой (не усложняя проблемы, учитывая обычную быстротечность процессов, считаем, что сбой — единственный);
произошел отказ.

Слайд 39Расчет модели надежности.
Пусть λ1 – частота сбоев (количество сбоев в единицу
времени), найденная как одна из характеристик выбранной ЭВМ; λ2 – частота отказов; λ1+λ2=λ.
Тогда λ*t – количество сбоев и отказов за время t, которое называется циклом управления.
Тогда λ*t – количество сбоев и отказов за время t, которое называется циклом управления.
Вероятность сбоя или отказа на таком элементарном отрезке:
Вероятность безотказной работы на элементарном отрезке :
на всех элементарных отрезках :
Вероятность безотказной работы:
Тогда P2(t)+P3(t)=1-P1(t)=1-e-λt
Вероятности сбоев и отказов:
Полная вероятность успешного решения задачи:
, найденная как одна")
Слайд 40Защита от сбоев.
Двойной просчет характерен для ЭВМ, не обладающих аппаратным контролем.
В случае несовпадения результатов двойного просчета задача считается третий раз.
Программно-алгоритмический контроль основан на способности предсказания ограниченной области, которой должны принадлежать результаты счета.
Аппаратный контроль устраняет синхронные аварии и сигнализирует об асинхронных авариях, порождая сигнал прерывания.

Слайд 41Резервирование
Резервирование не отдельной ЭВМ, а всего комплекса ЭВМ плюс внешних устройств
памяти, связи и обмена называется линейкой резервирования
Различают горячий и холодный резерв.
В горячем резерве ЭВМ работает в режиме дублирования или решения вспомогательных задач и в любой момент готова взять функции основной. В машина отключена.
Если в системе несколько ЭВМ, то каждая из них может иметь одну или более резервных, то такой механизм называется распределенным резервом.
Существует механизм скользящего резерва, когда несколько ЭВМ являются резервными, и каждая из них способна заменить любую из основных ЭВМ.

Слайд 42Реакция системы автоматического регулирования на аварии
Аппаратно выполняются следующие действия:
Обнаружение аварии
в модуле, определение ее типа, сохранение диагностической информации и приостановка работы аварийного модуля.
Передача информации об аварии по специальным шинам в другие модули.
Обработка сигналов аварии, приходящих от других модулей и исключение аварийного модуля из конфигурации.
Системная реакция на аварию: либо запуск специальных процедур ОС (малый рестарт), либо перезапуск комплекса (большой рестарт).
Передача информации об аварии по специальным шинам в другие модули.
Обработка сигналов аварии, приходящих от других модулей и исключение аварийного модуля из конфигурации.
Системная реакция на аварию: либо запуск специальных процедур ОС (малый рестарт), либо перезапуск комплекса (большой рестарт).
Программно выполняются следующие действия:
Сбор и обработка диагностической информации аварийного модуля.
Попытка вернуть его в рабочую конфигурацию в предположении, что авария произошла в результате сбоя.
Сохранение в системном журнале информации об аварии.

Слайд 43Методы повышения быстродействия компьютеров
Существуют три способа повышения производительности современных вычислительных систем:
за
счет использования конвейеров команд и арифметических конвейеров (конвейеризация).
за счет повышения быстродействия элементной базы (тактовой частоты).
за счет увеличения числа одновременно работающих в одной задаче ЭВМ, процессоров, АЛУ, умножителей и так далее, то есть за счет параллелизма выполнения операций (параллелизм).
за счет повышения быстродействия элементной базы (тактовой частоты).
за счет увеличения числа одновременно работающих в одной задаче ЭВМ, процессоров, АЛУ, умножителей и так далее, то есть за счет параллелизма выполнения операций (параллелизм).

Слайд 44Конвейеризация
Этапы конвейера:
IF (Instruction Fetch) - считывание команды в процессор;
ID (Instruction Decoding)
- декодирование команды;
OR (Operand Reading) - считывание операндов;
EX (Executing) - выполнение команды;
WB (Write Back) - запись результата.
OR (Operand Reading) - считывание операндов;
EX (Executing) - выполнение команды;
WB (Write Back) - запись результата.
 - считывание команды в процессор;ID (Instruction Decoding) - декодирование команды;OR (Operand")
Слайд 45Пусть для выполнения отдельных стадий обработки требуются следующие затраты времени (в
некоторых условных единицах):
TIF = 20, TID = 15, TOR = 20, TEX = 25, TWB = 20.
Тогда, предполагая, что дополнительные расходы времени составляют δ=5 единиц и выравнивая длину каждой ступени до максимальной, получим время такта:
T = max {TIF, TID, TOR, TEX, TWB} + δ = 30.
Основываясь на вышеизложенном можно оценить время выполнения одной команды и некоторой группы команд при последовательной и конвейерной обработке.
При последовательной обработке время выполнения N команд составит:
Tпосл = N*(TIF + TID + TOR + TEX + TWB) = 100N.
Tконв = 5T + (n-1) * T.
TIF = 20, TID = 15, TOR = 20, TEX = 25, TWB = 20.
Тогда, предполагая, что дополнительные расходы времени составляют δ=5 единиц и выравнивая длину каждой ступени до максимальной, получим время такта:
T = max {TIF, TID, TOR, TEX, TWB} + δ = 30.
Основываясь на вышеизложенном можно оценить время выполнения одной команды и некоторой группы команд при последовательной и конвейерной обработке.
При последовательной обработке время выполнения N команд составит:
Tпосл = N*(TIF + TID + TOR + TEX + TWB) = 100N.
Tконв = 5T + (n-1) * T.
:TIF =")
Слайд 46Эффективность конвейерной обработки
Под эффективностью обработки понимается реальная производительность Е конвейерного устройства,
равную отношению числа выполненных операций n к времени их выполнения t, то зависимость производительности от длины входных векторов: определяется следующим соотношением:

Слайд 47Повышение быстродействия элементной базы
1. Уменьшение (укорачивание) длина канала транзисторов (переход на
более тонки технологии), составляющих дискретные структуры процессора, что в свою очередь увеличивает их быстродействие.
 длина канала транзисторов (переход на более тонки технологии), составляющих")
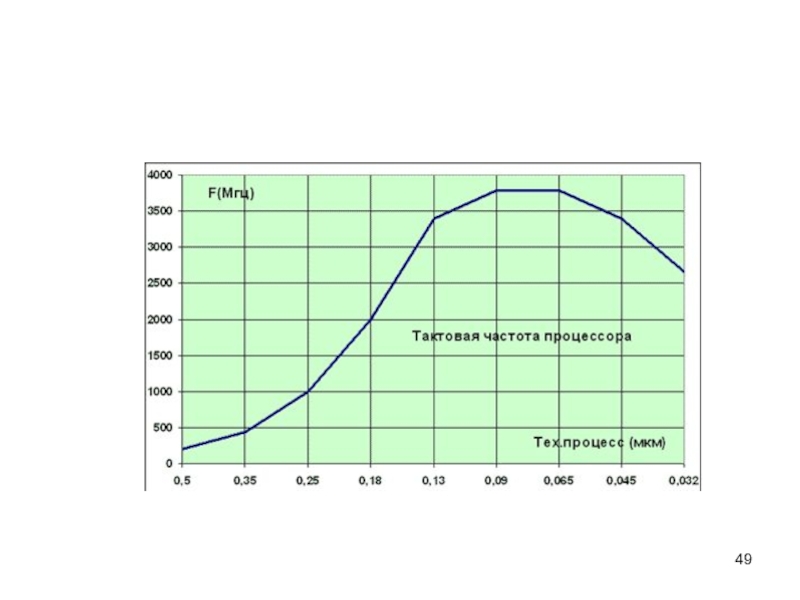
Слайд 48
2. Снижение площади транзистора, что должно сопровождаться уменьшением его внутренней емкости.
Однако применение high-k диэлектрика для изоляции затвора транзисторов выполненных по 45 нм тех. процессу, снижает емкость затвора незначительно и сохраняет емкость затвора на уровне близком к 65 нм тех. процессу. Данный факт не позволяет снизить удельную (на 1 ключ) потребляемую мощность не смотря на снижение размера
TDP (максимальное теоретическое тепловыделение процессора) > 150 Вт
TDP (максимальное теоретическое тепловыделение процессора) > 150 Вт
3. Отсутствие прироста тактовой частоты (более 3ГГц) при уменьшении площади кристалла процессора.
Мощность, потребляемая процессором (P, Вт) определяемая потерями в структурах процессора пропорциональна частоте переключения fn транзисторов и квадрату питающего напряжения Е2
P∼f* Е2

Слайд 50
4. Уменьшение площади занимаемой транзистором. Размещение большего число транзисторов и усложнение
структуры процессора на подложке, размер которой не превышает подложку предыдущей серии процессоров.

Слайд 515. Увеличение числа ядер процессоров и объема КЭШ-памяти.
Увеличение их количества вызвано
стремлением увеличить производительность системы. Как было отмечено выше, такое увеличение не может продолжаться бесконечно.
6. Увеличение числа контактов процессорного разъема (Soket'а).
3 фактора влияют на увеличение числа контактов:
усложнение структуры процессора;
рост потребляемого тока;
увеличение частоты помехи.

Слайд 52Формы параллелизма
Распараллеливание операций – перспективный путь повышения производительности вычислений. Согласно закону
Мура число транзисторов экспоненциально растёт, что позволяет в настоящее время включать в состав CPU большое количество исполнительных устройств самого разного назначения.

Слайд 53Закон Мура
Зако́н Му́ра — эмпирическое — эмпирическое наблюдение, сделанное в 1965 году — эмпирическое
наблюдение, сделанное в 1965 году (через шесть лет после изобретения интегральной схемы — эмпирическое наблюдение, сделанное в 1965 году (через шесть лет после изобретения интегральной схемы), в процессе подготовки выступления Гордоном Муром — эмпирическое наблюдение, сделанное в 1965 году (через шесть лет после изобретения интегральной схемы), в процессе подготовки выступления Гордоном Муром (одним из основателей Intel — эмпирическое наблюдение, сделанное в 1965 году (через шесть лет после изобретения интегральной схемы), в процессе подготовки выступления Гордоном Муром (одним из основателей Intel). Он высказал предположение, что число транзисторов на кристалле будет удваиваться каждые 24 месяца.


Слайд 55Зависимость по данным
Параллелизм – это возможность одновременного выполнения более одной арифметико-логической
операции. Возможность параллельного выполнения этих операций определяется правилом Рассела, которое состоит в следующем.
Программные объекты A и B (команды, операторы, программы) являются независимыми и могут выполняться параллельно, если выполняется следующее условие:
(InB ∧ OutA) ∨ (InA ∧ OutB) ∧ (OutA ∧ OutB) = ∅,
где In(A) – набор входных, а Out(A) – набор выходных переменных объекта A. Если условие не выполняется, то между A и B существует зависимость и они не могут выполняться параллельно.
Программные объекты A и B (команды, операторы, программы) являются независимыми и могут выполняться параллельно, если выполняется следующее условие:
(InB ∧ OutA) ∨ (InA ∧ OutB) ∧ (OutA ∧ OutB) = ∅,
где In(A) – набор входных, а Out(A) – набор выходных переменных объекта A. Если условие не выполняется, то между A и B существует зависимость и они не могут выполняться параллельно.

Слайд 56Зависимость по данным
Нарушение условия в первом терме:
A: R = R1 +
R2
B: Z = R + C
Здесь операторы A и B не могут выполняться одновременно, так как результат A является операндом B.
Нарушение условия во втором терме:
A: R = R1 + R2
B: R1 = C1 + C2
Здесь операторы A и B не могут выполняться одновременно, так как выполнение B вызывает изменение операнда в A.
Нарушение условия в третьем терме:
A: R = R1 + R2
B: R = C1 + C2
Здесь одновременное выполнение операторов дает неопределенный результат.
B: Z = R + C
Здесь операторы A и B не могут выполняться одновременно, так как результат A является операндом B.
Нарушение условия во втором терме:
A: R = R1 + R2
B: R1 = C1 + C2
Здесь операторы A и B не могут выполняться одновременно, так как выполнение B вызывает изменение операнда в A.
Нарушение условия в третьем терме:
A: R = R1 + R2
B: R = C1 + C2
Здесь одновременное выполнение операторов дает неопределенный результат.

Слайд 57Информационный граф задачи
Наиболее общей формой представления этих зависимостей является информационный
граф задачи. В своей первоначальной форме ИГ, тем не менее, не используется ни математиком, ни программистом, ни ЭВМ.

Слайд 58Ярусно-параллельная форма
Более определенной формой представления параллелизма является ярусно-параллельная форма (ЯПФ): алгоритм
вычислений представляется в виде ярусов, причем в нулевой ярус входят операторы (ветви), не зависящие друг от друга, в первый ярус – операторы, зависящие только от нулевого яруса, во второй – от первого яруса и т. д.
Для ЯПФ характерны параметры, в той или иной мере отражающие степень параллелизма метода вычислений: bi – ширина i-го яруса; B – ширина графа ЯПФ (максимальная ширина яруса, т. е. максимум из bi, i = 1, 2, ...); li – длина яруса (время операций) и L длина графа; ε – коэффициент заполнения ярусов; θ – коэффициент разброса указанных параметров и т. д.
Для ЯПФ характерны параметры, в той или иной мере отражающие степень параллелизма метода вычислений: bi – ширина i-го яруса; B – ширина графа ЯПФ (максимальная ширина яруса, т. е. максимум из bi, i = 1, 2, ...); li – длина яруса (время операций) и L длина графа; ε – коэффициент заполнения ярусов; θ – коэффициент разброса указанных параметров и т. д.
: алгоритм вычислений представляется в виде")
Слайд 59Мелкозернистый (скалярный) параллелизм
При исполнении программы регулярно встречаются ситуации, когда исходные данные
для i-й операции вырабатываются заранее, например, при выполнении (i-2)-й или (i-3)-й операции. Тогда при соответствующем построении вычислительной системы можно совместить во времени выполнение i-й операции с выполнением (i-1)-й, (i-2)-й, ... операций.
 параллелизмПри исполнении программы регулярно встречаются ситуации, когда исходные данные для i-й операции вырабатываются")
Слайд 60Пример мелкозернистого параллелизма
Пусть имеется программа для расчета ширины запрещенной зоны транзистора
и в этой программе есть участок — определение энергии примесей по формуле:
Тогда последовательная программа для вычисления E будет такой:
F1 = m ∗ q ∗q∗ q ∗ q ∗ π ∗ π
F2 = 8 ∗ ε0 ∗ ε0 ∗ ε ∗ ε ∗ h ∗ h
E = F1/F2
Здесь имеется параллелизм, но при записи на Фортране (показано выше) или Ассемблере у нас нет возможности явно отразить его. Явное представление параллелизма для вычисления E задается ЯПФ:
Для скалярного параллелизма используют термин мелкозернистый параллелизм.

Слайд 61Крупнозернистый параллелизм
Векторный параллелизм. Наиболее распространенной в обработке структур данных является векторная
операция (естественный параллелизм). Вектор — одномерный массив, который образуется из многомерного массива, если один из индексов не фиксирован и пробегает все значения в диапазоне его изменения.
Области применения векторных операций над массивами обширны: цифровая обработка сигналов (цифровые фильтры); механика, моделирование сплошных сред; метеорология; оптимизация; задачи движения; расчеты электрических характеристик БИС и т. д.
Области применения векторных операций над массивами обширны: цифровая обработка сигналов (цифровые фильтры); механика, моделирование сплошных сред; метеорология; оптимизация; задачи движения; расчеты электрических характеристик БИС и т. д.
DO 1 I = 1,N
1 C(I,J) = A(I,J) + B(I,J)
C (∗, j) = A (∗, j) + B (∗, j)
. Вектор")
Слайд 62Параллелизм независимых ветвей
Суть параллелизма независимых ветвей состоит в том, что в
программе решения большой задачи могут быть выделены независимые программные части – ветви программы, которые при наличии нескольких обрабатывающих устройств могут выполняться параллельно и независимо друг от друга. Двумя независимыми ветвями программы считаются такие части задачи, при выполнении которых выполняются следующие условия:
1. ни одна из входных величин для ветви программы не является выходной величиной другой программы (отсутствие функциональных связей);
2. для обеих ветвей программы не должна производиться запись в одни и те же ячейки памяти (отсутствие связи по использованию одних и тех же полей оперативной памяти);
3. условия выполнения одной ветви не зависят от результатов или признаков, полученных при выполнении другой ветви (независимость по управлению);
4. обе ветви должны выполняться по разным блокам программы (программная независимость).
1. ни одна из входных величин для ветви программы не является выходной величиной другой программы (отсутствие функциональных связей);
2. для обеих ветвей программы не должна производиться запись в одни и те же ячейки памяти (отсутствие связи по использованию одних и тех же полей оперативной памяти);
3. условия выполнения одной ветви не зависят от результатов или признаков, полученных при выполнении другой ветви (независимость по управлению);
4. обе ветви должны выполняться по разным блокам программы (программная независимость).

Слайд 63Параллелизм вариантов
Это широко распространенный в практике вариант решение одной и той
же модели при разных входных параметрах, причем, все варианты (как правило, с длительным счетом) должны быть получены за ограниченное время. Например, варианты моделирования используются при анализе атмосферной модели климата, при расчете ядерного взрыва, обтекания летательного аппарата, расчета полупроводниковых приборов.
Параллелизм вариантов отличается от идеологии крупнозернистого параллелизма. Отличие состоит в том, что в случае крупнозернистого параллелизма вычисления проводятся внутри одной задачи и требования к скорости обмена между частями задачи достаточно высокие. В параллелизме вариантов распараллеливаются целые задачи, обмен между которыми в принципе отсутствует.
Системы распределенных вычислений идеальны для решения вариантных задач.
Параллелизм вариантов отличается от идеологии крупнозернистого параллелизма. Отличие состоит в том, что в случае крупнозернистого параллелизма вычисления проводятся внутри одной задачи и требования к скорости обмена между частями задачи достаточно высокие. В параллелизме вариантов распараллеливаются целые задачи, обмен между которыми в принципе отсутствует.
Системы распределенных вычислений идеальны для решения вариантных задач.

Слайд 64Закон Амдала
Одной из главных характеристик параллельных систем является ускорение R параллельной
системы, которое определяется выражением:
R = T1 /Tn ,
где T1 − время решения задачи на однопроцессорной системе, а Tn − время решения той же задачи на n − процессорной системе.
Пусть W = Wск + Wпр, где W − общее число операций в задаче, Wпр − число операций, которые можно выполнять параллельно, а Wcк − число скалярных (нераспараллеливаемых) операций.
Если обозначить через t время выполнения одной операции. Тогда закон Амдала выглядит следующим образом:
R = T1 /Tn ,
где T1 − время решения задачи на однопроцессорной системе, а Tn − время решения той же задачи на n − процессорной системе.
Пусть W = Wск + Wпр, где W − общее число операций в задаче, Wпр − число операций, которые можно выполнять параллельно, а Wcк − число скалярных (нераспараллеливаемых) операций.
Если обозначить через t время выполнения одной операции. Тогда закон Амдала выглядит следующим образом:
Здесь a = Wск /W − удельный вес скалярных операций.

Слайд 65Следствия закона Амдала
Закон Амдала определяет принципиально важные для параллельных вычислений положения:
ускорение
зависит от потенциального параллелизма задачи (величина 1– а) и параметров аппаратуры (числа процессоров n);
предельное ускорение определяется свойствами задачи.
предельное ускорение определяется свойствами задачи.

Слайд 66Сетевой закон Амдала
Основной вариант закона Амдала не отражает потерь времени на
межпроцессорный обмен сообщениями. Эти потери могут не только снизить ускорение вычислений, но и замедлить вычисления по сравнению с однопроцессорным вариантом. Поэтому необходима некоторая модернизация выражения:
Здесь Wc − количество передач данных, tc − время одной передачи данных. Выражение:
является сетевым законом Амдала.

Слайд 67Особенности многопроцессорных вычислений
на основе закона Амдала
1. Коэффициент сетевой деградации вычислений с:
определяет
объем вычислений, приходящийся на одну передачу данных (по затратам времени). При этом сА определяет алгоритмическую составляющую коэффициента деградации, обусловленную свойствами алгоритма, а сТ − техническую составляющую, которая зависит от соотношения технического быстродействия процессора и аппаратуры сети.
Таким образом, для повышения скорости вычислений следует воздействовать на обе составляющие коэффициента деградации.
Таким образом, для повышения скорости вычислений следует воздействовать на обе составляющие коэффициента деградации.
2. Даже если задача обладает идеальным параллелизмом, сетевое ускорение определяется величиной:
и увеличивается при уменьшении с. Следовательно, сетевой закон Амдала должен быть основой оптимальной разработки алгоритма и программирования задач, предназначенных для решения на многопроцессорных ЭВМ
Если система имеет несколько архитектурных уровней с разными формами параллелизма, например, мелкозернистый параллелизм на уровне АЛУ, параллелизм среднего уровня на процесссорном уровне и параллелизм задач, то качественно общее ускорение в системе будет:
R = r1×r2×r3,
где ri - ускорение некоторого уровня.

Слайд 68Вычислительные системы
Компьютерные с общей памятью (мультипроцессорные системы)
Компьютерные с распределенной памятью
(мультикомпьютерные системы)
Компьютерные с распределенной памятью(мультикомпьютерные системы)")
Слайд 69Мультипроцессорные системы
Первый класс – это компьютеры с общей памятью. Системы, построенные
по такому принципу, иногда называют мультипроцессорными "системами или просто мультипроцессорами. В системе присутствует несколько равноправных процессоров, имеющих одинаковый доступ к единой памяти. Все процессоры "разделяют" между собой общую память.
Все процессоры работают с единым адресным пространством: если один процессор записал значение 79 в ячейку по адресу 1024, то другой процессор, прочитав содержимое ячейки, расположенное по адресу 1024, получит значение 79.
Все процессоры работают с единым адресным пространством: если один процессор записал значение 79 в ячейку по адресу 1024, то другой процессор, прочитав содержимое ячейки, расположенное по адресу 1024, получит значение 79.


Слайд 71Мультикомпьютерные системы
Второй класс — это компьютеры с распределенной памятью, которые по
аналогии с предыдущим классом иногда называют мультикомпьютерными системами. Каждый вычислительный узел является полноценным компьютером со своим процессором, памятью, подсистемой ввода/вывода, операционной системой.
В такой ситуации, если один процессор запишет значение 79 по адресу 1024, то это никак не повлияет на то, что по тому же адресу прочитает другой, поскольку каждый из них работает в своем адресном пространстве.
В такой ситуации, если один процессор запишет значение 79 по адресу 1024, то это никак не повлияет на то, что по тому же адресу прочитает другой, поскольку каждый из них работает в своем адресном пространстве.


Слайд 73Blue Gene/L
Расположение:
Ливерморская национальная лаборатория имени Лоуренса
Общее число процессоров 65536 штук
Состоит из
64 стоек
Производительность 280,6 терафлопс
В штате лаборатории - порядка 8000 сотрудников, из которых - более 3500 ученых и инженеров.
Машина построена по сотовой архитектуре, то есть, из однотипных блоков, что предотвращает появление "узких мест" при расширении системы.
Стандартный модуль BlueGene/L - "compute card" - состоит из двух блоков-узлов (node), модули группируются в модульную карту по 16 штук, по 16 модульных карт устанавливаются на объединительной панели (midplane) размером 43,18 х 60,96 х 86,36 см, при этом каждая такая панель объединяет 512 узлов. Две объединительные панели монтируются в серверную стойку, в которой уже насчитывается 1024 базовых блоков-узлов.
На каждом вычислительном блоке (compute card) установлено по два центральных процессора и по четыре мегабайта выделенной памяти
Процессор PowerPC 440 способен выполнять за такт четыре операции с плавающей запятой, что для заданной тактовой частоты соответствует пиковой производительности в 1,4 терафлопс для одной объединительной панели (midplane), если считать, что на одном узле установлено по одному процессору. Однако на каждом блоке-узле имеется еще один процессор, идентичный первому, но он призван выполнять телекоммуникационные функции.

Слайд 74Задачи параллельных вычислений
Построении вычислительных систем с максимальной производительностью
компьютеры с распределенной памятью
единственным
способом программирования подобных систем является использование систем обмена сообщениями
Поиск методов разработки эффективного программного обеспечения для параллельных вычислительных систем
компьютеры с общей памятью
технологии программирования проще
по технологическим причинам не удается объединить большое число процессоров с единой оперативной памятью
проблемным звеном является система коммутации
Поиск методов разработки эффективного программного обеспечения для параллельных вычислительных систем
компьютеры с общей памятью
технологии программирования проще
по технологическим причинам не удается объединить большое число процессоров с единой оперативной памятью
проблемным звеном является система коммутации

Слайд 75Организация мультипроцессорных систем
(общая шина)
Мультипроцессорная система с общей шиной
Чтобы предотвратить одновременное
обращение нескольких процессоров к памяти, используются схемы арбитража, гарантирующие монопольное владение шиной захватившим ее устройством.
Недостаток:
заключается в том, что даже небольшое увеличение числа устройств на шине (4-5) очень быстро делает ее узким местом, вызывающим значительные задержки при обменах с памятью и катастрофическое падение производительности системы в целом
Достоинство: простота и дешевизна конструкции
Мультипроцессорная система с общей шиной Чтобы предотвратить одновременное обращение нескольких процессоров")
Слайд 76Организация мультипроцессорных систем
(матричный коммутатор)
Матричный коммутатор позволяет разделить память на независимые модули
и обеспечить возможность доступа разных процессоров к различным модулям одновременно.
На пересечении линий располагаются элементарные точечные переключатели, разрешающие или запрещающие передачу информации между процессорами и модулями памяти.
На пересечении линий располагаются элементарные точечные переключатели, разрешающие или запрещающие передачу информации между процессорами и модулями памяти.
Недостаток:
большой объем необходимого оборудования, поскольку для связи n процессоров с n модулями памяти требуется nxn элементарных переключателей
Мультипроцессорная система с матричным коммутатором
Преимущества:
возможность одновременной работы процессоров с различными модулями памяти
Матричный коммутатор позволяет разделить память на независимые модули и обеспечить возможность")
Слайд 77Организация мультипроцессорных систем
Мультипроцессорная система с омега-сетью
Использование каскадных переключателей
Каждый использованный коммутатор
может соединить любой из двух своих входов с любым из двух своих выходов. Это свойство и использованная схема коммутации позволяют любому процессору вычислительной системы обращаться к любому модулю памяти.
В общем случае для соединения n процессоров с n модулями памяти потребуется log2n каскадов по n/2 коммутаторов в каждом, т. е. всего (nlog2n)/2 коммутаторов.
В общем случае для соединения n процессоров с n модулями памяти потребуется log2n каскадов по n/2 коммутаторов в каждом, т. е. всего (nlog2n)/2 коммутаторов.
Проблема:
задержки

Слайд 78Топологические связи модулей ВС
Выбор той топологии связи процессоров в конкретной
вычислительной системе может быть обусловлен самыми разными причинами.
Это могут быть соображениями стоимости, технологической реализуемости, простоты сборки и программирования, надежности, минимальности средней длины пути между узлами, минимальности максимального расстояния между узлами и др.
Это могут быть соображениями стоимости, технологической реализуемости, простоты сборки и программирования, надежности, минимальности средней длины пути между узлами, минимальности максимального расстояния между узлами и др.


Слайд 80Топология двоичного гиперкубы
В n-мерном пространстве в вершинах единичного n-мерного куба размещаются
процессоры системы, т. е. точки (x1, x2, …, хn), в которых все координаты хi могут быть равны либо 0, либо 1. Каждый процессор соединим с ближайшим непосредственным соседом вдоль каждого из n измерений. В результате получается n-мерный куб для системы из N = 2n процессоров. Двумерный куб соответствует простому квадрату, а четырехмерный вариант условно изображен на рисунке. В гиперкубе каждый процессор связан лишь с log2N непосредственными соседями, а не с N, как в случае полной связности.
Гиперкуб имеет массу полезных свойств.
Например, для каждого процессора очень просто определить всех его соседей: они отличаются от него лишь значением какой-либо одной координаты хi. Каждая "грань" n-мерного гиперкуба является гиперкубом размерности n-1. Максимальное расстояние между вершинами n-мерного гиперкуба равно n. Гиперкуб симметричен относительно своих узлов: из каждого узла система выглядит одинаковой и не существует узлов, которым необходима специальная обработка.

Слайд 81Достоинства и недостатки компьютеров с общей и распределенной памятью
Для компьютеров с
общей памятью проще создавать параллельные программы, но их максимальная производительность сильно ограничивается небольшим числом процессоров.
Для компьютеров с распределенной памятью все наоборот.
Одним из возможных направлений объединения достоинств этих двух классов является проектирование компьютеров с архитектурой NUMA (Non Uniform Memory Access).
Для компьютеров с распределенной памятью все наоборот.
Одним из возможных направлений объединения достоинств этих двух классов является проектирование компьютеров с архитектурой NUMA (Non Uniform Memory Access).

Слайд 82Классификация вычислительных систем
Классификация Флинна
Классификация Хокни
Классификация Фенга
Классификация Дункана
Классификация
Хендлера

Слайд 83Классификация Флина
Базируется на понятии потока, под которым понимается последовательность элементов, команд
или данных, обрабатываемая процессором.


Слайд 85Недостатки классификации Флина
Некоторые архитектуры четко не вписываются в данную классификацию
Чрезмерная заполненность
класса MIMD

Слайд 86Классификация Хокни
Основная идея классификации состоит в следующем.
Множественный поток команд может быть
обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством.


Слайд 88Примеры классификации Флина
SISD – PDP-11, VAX 11/780, CDC 6600 и CDC
7600
SIMD – ILLIAC IV, CRAY-1
MISD – нет
MIMD – большинство современных машин
SIMD – ILLIAC IV, CRAY-1
MISD – нет
MIMD – большинство современных машин
Примеры классификации Хокни
MIMD конвейерные – Denelcor HEP
MIMD переключаемые с распределенной памятью – PASM, PRINGLE
MIMD переключаемы с общей памятью – CRAY X-MP, BBN Butterfly
MIMD звездообразная сеть – ICAP
MIMD регулярные решетки – Intel Paragon, CRAY T3D
MIMD гиперкубы – NCube, Intel iPCS
MIMD с иерархической структурой (кластеры) – Cm* , CEDAR

Слайд 89Классификация Фенга
Идея классификации вычислительных систем на основе двух простых характеристик. Первая
- число бит n в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной вычислительной системой. Вторую характеристику обычно называют шириной битового слоя.

Слайд 90Классификация Фенга
Любую вычислительную систему C можно описать парой чисел (n, m)
и представить точкой на плоскости в системе координат длина слова - ширина битового слоя. Площадь прямоугольника со сторонами n и m определяет интегральную характеристику потенциала параллельности P архитектуры и носит название максимальной степени параллелизма вычислительной системы: P(C)=mn.
 и представить точкой на")
Слайд 91Примеры классификации Фенга
Разрядно-последовательные пословно-последовательные (n=m=1):
MINIMA с естественным описанием (1,1)
Разрядно-параллельные пословно-последовательные
(n>1; m=1):
IBM 701 с описанием (36,1), PDP-11 (16,1), IBM 360/50,
VAX 11/780 - обе с описанием (32,1)
Разрядно-последовательные пословно-параллельные (n=1; m>1):
STARAN (1, 256) и MPP (1,16384) фирмы Goodyear Aerospace, прототип системы ILLIAC IV компьютер SOLOMON (1, 1024),
ICL DAP (1, 4096).
Разрядно-параллельные пословно-параллельные (n>1; m>1):
ILLIAC IV (64, 64), TI ASC (64, 32), C.mmp (16, 16), CDC 6600 (60, 10), BBN Butterfly GP1000 (32, 256).
IBM 701 с описанием (36,1), PDP-11 (16,1), IBM 360/50,
VAX 11/780 - обе с описанием (32,1)
Разрядно-последовательные пословно-параллельные (n=1; m>1):
STARAN (1, 256) и MPP (1,16384) фирмы Goodyear Aerospace, прототип системы ILLIAC IV компьютер SOLOMON (1, 1024),
ICL DAP (1, 4096).
Разрядно-параллельные пословно-параллельные (n>1; m>1):
ILLIAC IV (64, 64), TI ASC (64, 32), C.mmp (16, 16), CDC 6600 (60, 10), BBN Butterfly GP1000 (32, 256).
: MINIMA с естественным описанием (1,1) Разрядно-параллельные пословно-последовательные (n>1; m=1): IBM 701 с")
Слайд 92Недостаток
не делает никакого различия между процессорными матрицами, векторно-конвейерными и многопроцессорными системами;
отсутствует
акцент на том, за счет чего компьютер может одновременно обрабатывать более одного слова.

Слайд 93Классификация Дункана
Дункан определил набор требований для создания своей классификации.
Из классификации должны
быть исключены машины, параллелизм в которых заложен на самом низком уровне:
конвейеризация на этапе подготовки и выполнения команды;
наличие в архитектуре нескольких функциональных устройств, работающих независимо;
наличие отдельных процессоров ввода/вывода
Классификация должна быть согласованной с классификацией Флинна.
Классификация должна описывать архитектуры, которые однозначно не укладываются в систематику Флинна
конвейеризация на этапе подготовки и выполнения команды;
наличие в архитектуре нескольких функциональных устройств, работающих независимо;
наличие отдельных процессоров ввода/вывода
Классификация должна быть согласованной с классификацией Флинна.
Классификация должна описывать архитектуры, которые однозначно не укладываются в систематику Флинна


Слайд 95Основные архитектуры, представленные на рисунке рисунка
Систолические архитектуры представляют собой множество процессоров,
объединенных регулярным образом. Обращение к памяти может осуществляться только через определенные процессоры на границе массива. Выборка операндов из памяти и передача данных по массиву осуществляется в одном и том же темпе. Направление передачи данных между процессорами фиксировано. Каждый процессор за интервал времени выполняет небольшую инвариантную последовательность действий.
Гибридные MIMD/SIMD архитектуры, dataflow, reduction и wavefront вычислительные системы осуществляют параллельную обработку информации на основе асинхронного управления.
MIMD/SIMD - типично гибридная архитектура. Она предполагает, что в MIMD системе можно выделить группу процессоров, представляющую собой подсистему, работающую в режиме SIMD;
Dataflow используют модель, в которой команда может выполнятся сразу же, как только вычислены необходимые операнды;
Модель вычислений, применяемая в reduction машинах иная и состоит в следующем: команда становится доступной для выполнения тогда и только тогда, когда результат ее работы требуется другой, доступной для выполнения, команде в качестве операнда;
Wavefront array архитектура. В данной архитектуре процессоры объединяются в модули и фиксируются связи, по которым процессоры могут взаимодействовать друг с другом. Данная архитектура использует асинхронный механизм связи с подтверждением
Гибридные MIMD/SIMD архитектуры, dataflow, reduction и wavefront вычислительные системы осуществляют параллельную обработку информации на основе асинхронного управления.
MIMD/SIMD - типично гибридная архитектура. Она предполагает, что в MIMD системе можно выделить группу процессоров, представляющую собой подсистему, работающую в режиме SIMD;
Dataflow используют модель, в которой команда может выполнятся сразу же, как только вычислены необходимые операнды;
Модель вычислений, применяемая в reduction машинах иная и состоит в следующем: команда становится доступной для выполнения тогда и только тогда, когда результат ее работы требуется другой, доступной для выполнения, команде в качестве операнда;
Wavefront array архитектура. В данной архитектуре процессоры объединяются в модули и фиксируются связи, по которым процессоры могут взаимодействовать друг с другом. Данная архитектура использует асинхронный механизм связи с подтверждением

Слайд 96Классификация Хендлера
Предложенная классификация базируется на различии между тремя уровнями обработки данных
в процессе выполнения программ:
уровень выполнения программы
уровень выполнения команд
уровень битовой обработки
уровень выполнения программы
уровень выполнения команд
уровень битовой обработки
В основу классификации В.Хендлер закладывает явное описание возможностей параллельной и конвейерной обработки информации вычислительной системой. При этом он намеренно не рассматривает различные способы связи между процессорами и блоками памяти и считает, что коммуникационная сеть может быть нужным образом сконфигурирована и будет способна выдержать предполагаемую нагрузку.

Слайд 97Классификация Хендлера
t(C) = (k, d, w)
t( PEPE ) = (k×k',d×d',w×w')
где:
k - число процессоров (каждый со своим УУ), работающих параллельно
k' - глубина макроконвейера из отдельных процессоров
d - число АЛУ в каждом процессоре, работающих параллельно
d' - число функциональных устройств АЛУ в цепочке
w - число разрядов в слове, обрабатываемых в АЛУ параллельно
w' - число ступеней в конвейере функциональных устройств АЛУ
t(n,d,w)=[(1,d,w)+...+(1,d,w)]{n раз}
 = (k, d, w) t( PEPE ) = (k×k',d×d',w×w') где: k - число процессоров")
Слайд 98Дополнения к классификации Хендлера
Хендлер предлагает использовать три операции:
Первая операция (×) отражает
конвейерный принцип обработки и предполагает последовательное прохождение данных сначала через первый ее аргумент-подсистему, а затем через второй
Вторая операция параллельного исполнения (+), фиксирует возможность независимого использования процессоров разными задачами
Третья операция - операция альтернативы (V), показывает возможные альтернативные режимы функционирования вычислительной системы
Вторая операция параллельного исполнения (+), фиксирует возможность независимого использования процессоров разными задачами
Третья операция - операция альтернативы (V), показывает возможные альтернативные режимы функционирования вычислительной системы
Для описания:
сложных структур с подсистемами ввода-вывода
возможных режимов функционирования вычислительных систем, поддерживаемых для оптимального соответствия структуре программ.
 отражает конвейерный принцип обработки и")
Слайд 99Примеры классификации Хендлера
t( MINIMA ) = (1,1,1);
t( IBM 701 ) =
(1,1,36);
t( SOLOMON ) = (1,1024,1);
t( ILLIAC IV ) = (1,64,64);
t( STARAN ) = (1,8192,1) - в полной конфигурации;
t( C.mmp ) = (16,1,16) - основной режим работы;
t( PRIME ) = (5,1,16);
t( BBN Butterfly GP1000 ) = (256,~1,~32).
t( TI ASC ) = (1,4,64×8)
t(CDC 6600) = (1,1×10,~64)
t( PEPE ) = (1×3,288,32)
t( CDC 6600 ) = (10,1,12) × (1,1×10,64),
t( PEPE ) = t( CDC 7600 ) × (1×3, 288, 32) = = (15, 1, 12) × (1, 1×9, 60) × (1×3, 288, 32)
(15, 1, 12) × (1, 1×9, 60) = [(1, 1, 12) + ... +(1, 1, 12)]} {15 раз} × (1, 1×9, 60)
t( C.mmp ) = (16, 1, 16) V (1×16, 1,1 6) V (1, 16, 16).
t( TI ASC ) = (1,4,64×8)
t(CDC 6600) = (1,1×10,~64)
t( PEPE ) = (1×3,288,32)
t( CDC 6600 ) = (10,1,12) × (1,1×10,64),
t( PEPE ) = t( CDC 7600 ) × (1×3, 288, 32) = = (15, 1, 12) × (1, 1×9, 60) × (1×3, 288, 32)
(15, 1, 12) × (1, 1×9, 60) = [(1, 1, 12) + ... +(1, 1, 12)]} {15 раз} × (1, 1×9, 60)
t( C.mmp ) = (16, 1, 16) V (1×16, 1,1 6) V (1, 16, 16).
 = (1,1,1); t( IBM 701 ) = (1,1,36); t( SOLOMON")





