- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Компиляторы Интел для высокопроизводительных вычислений презентация
Содержание
- 1. Компиляторы Интел для высокопроизводительных вычислений
- 2. Упрощенная модель процессора Оперативная память (RAM) Системная
- 3. Упрощенная модель процессора Со времен изобретения
- 4. Высокая производительность МП Высокая производительность
- 5. Тактовая частота: Поскольку процессор состоит из
- 6. Скорость выполнения инструкций и полнота базового набора
- 7. Использование внутренней памяти, распределение регистров:
- 8. Конвейер Instruction fetch Register fetch
- 9. Качество конвейеризации, уровень параллелизма инструкций
- 10. Качество предсказания переходов: Инструкции могут быть
- 11. Качество упреждающей выборки: Поскольку программы часто работают
- 12. Суперскалярность: Суперскалярный процессор – это процессор способный
- 13. Упрощенная модель процессора Оперативная память (RAM) Упреждающая
- 14. Параллелизация и многоядерность: Многозадачность, многопоточность. Одновременно
- 15. Основные характеристики влияющие на производительность МП
- 16. Измерение производительности Потребителям необходимы критерии определения
- 17. Место и роль компилятора. Компиля́тор —
- 18. Программа должна быть: Легко читаемой и
- 19. Мы обсуждали факторы влияющие на производительность.
- 20. Скорость выполнения инструкций и полнота базового набора
- 21. Использование внутренней памяти, распределение регистров. Трансформация данных
- 22. Интеловские компиляторы Интел имеет С/C++
- 23. Оптимизации: 1.) Скалярные оптимизации Свертка констант, протяжка
- 24. 2.) Цикловые оптимизации Вынесение инвариантов цикла (Loop
- 25. Помимо этих оптимизаций существуют и другие,
- 26. 3.) Векторизация Векторизация, в компьютерной науке,
- 27. 4.)Автоматическая параллелизация Автоматическая параллелизация – это
- 28. 5.)Оптимизация вызовов функций, межпроцедурный анализ.
- 29. Статический и динамический профилировщики. Подсчет «весовых»
- 30. Зависимость основных характеристик компиляции. Производительность программы Время компиляции Размер кода Отладка, надежность
- 31. Пошаговый алгоритм отладки/улучшения производительности программы 1.) Проверка
- 32. Инструменты и методы используемые для оптимизации производительности
- 35. 6.) Добавление межпроцедурных оптимизаций –ipo 7.)

Слайд 2Упрощенная модель процессора
Оперативная
память
(RAM)
Системная шина
Вычислительное
устройство
(ALU)
Управляющее
устройство
(CU)
Устройство
взаимодействия
с внешней
памятью
Внешняя
память
Шина
ввода-вывода
Процессор
Команды
Данные
Регистры
Системная шинаВычислительное устройство(ALU)Управляющееустройство(CU)Устройство взаимодействияс внешней памятьюВнешняя памятьШинаввода-выводаПроцессорКомандыДанныеРегистры")
Слайд 3Упрощенная модель процессора
Со времен изобретения микросхемы в мире было разработано
большое число разных процессоров, но в любом процессоре можно выделить:
устройство управления (Control Unit, CU)
арифметико-логическое устройство (Arithmetic and Logic Unit,ALU)
системные регистры
Чтобы превратить все это в вычислительную систему необходимо как минимум добавить
системную шину (Front Side Bus, FSB)
память
периферийные устройства
Устройство управления (CU):
проводит дешифрацию инструкций, поступающих из памяти компьютера.
управляет ALU.
осуществляет пересылку данных между регистрами ЦП, памятью, периферийными устройствами.
и т.д.
Арифметико-логическое устройство состоит из различных микросхем, позволяющих производить арифметические и логические операции над системными регистрами.
Системные регистры – это определенный участок памяти внутри ЦП, используемый для промежуточного хранения информации, обрабатываемой процессором.
Системная шина используется для пересылки данных между ЦП и памятью, а также между ЦП и периферийными устройствами. В современных компьютерах ЦП через шину связывается с системным контроллером ПК, а он уже управляет периферийными устройствами.
устройство управления (Control Unit, CU)
арифметико-логическое устройство (Arithmetic and Logic Unit,ALU)
системные регистры
Чтобы превратить все это в вычислительную систему необходимо как минимум добавить
системную шину (Front Side Bus, FSB)
память
периферийные устройства
Устройство управления (CU):
проводит дешифрацию инструкций, поступающих из памяти компьютера.
управляет ALU.
осуществляет пересылку данных между регистрами ЦП, памятью, периферийными устройствами.
и т.д.
Арифметико-логическое устройство состоит из различных микросхем, позволяющих производить арифметические и логические операции над системными регистрами.
Системные регистры – это определенный участок памяти внутри ЦП, используемый для промежуточного хранения информации, обрабатываемой процессором.
Системная шина используется для пересылки данных между ЦП и памятью, а также между ЦП и периферийными устройствами. В современных компьютерах ЦП через шину связывается с системным контроллером ПК, а он уже управляет периферийными устройствами.

Слайд 4Высокая производительность МП
Высокая производительность МП –один из ключевых факторов
в конкурентной борьбе производителей процессоров.
Интуитивно понятно, что производительность процессора напрямую связана с количеством работы, вычислений, которые он может выполнить за единицу времени.
Очень условно:
Производительность = Кол-во инструкций / Время
Мы будем беседовать о производительности на базе IA32 и IA32e архитектур.
(IA32 with EM64T).
Факторы влияющие на производительность процессора:
Тактовая частота процессора
Объем адресуемой памяти и скорость доступа к внешней памяти
Скорость выполнения инструкций и полнота базового набора инструкций
Использование внутренней памяти, распределение регистров
Уровень конвейеризации
Качество предсказания переходов
Качество упреждающей выборки
Суперскалярность
Параллелизация и многоядерность
Интуитивно понятно, что производительность процессора напрямую связана с количеством работы, вычислений, которые он может выполнить за единицу времени.
Очень условно:
Производительность = Кол-во инструкций / Время
Мы будем беседовать о производительности на базе IA32 и IA32e архитектур.
(IA32 with EM64T).
Факторы влияющие на производительность процессора:
Тактовая частота процессора
Объем адресуемой памяти и скорость доступа к внешней памяти
Скорость выполнения инструкций и полнота базового набора инструкций
Использование внутренней памяти, распределение регистров
Уровень конвейеризации
Качество предсказания переходов
Качество упреждающей выборки
Суперскалярность
Параллелизация и многоядерность

Слайд 5Тактовая частота:
Поскольку процессор состоит из разных микросхем, и каждая работает
разное время, то в процессоре существует таймер, который отвечает за синхронизацию работы микросхем, посылая периодический синхроимпульс. Его частота и называется тактовой частотой процессора.
Объем адресуемой памяти и скорость доступа к памяти:
8086 мог одновременно работать всего с 4 сегментами по 64 КБ каждый и всего мог адресовать 1МБ памяти.
80286 – добавились новые системные регистры и новый режим работы с памятью в котором процессор мог адресовать 16МБ памяти.
80386 – первый 32-битный процессор, позволяет адресовать 4ГБ памяти
технология EM64T (Extended Memory 64 Technology) – сняла и это ограничение.
Объем адресуемой памяти и скорость доступа к памяти:
8086 мог одновременно работать всего с 4 сегментами по 64 КБ каждый и всего мог адресовать 1МБ памяти.
80286 – добавились новые системные регистры и новый режим работы с памятью в котором процессор мог адресовать 16МБ памяти.
80386 – первый 32-битный процессор, позволяет адресовать 4ГБ памяти
технология EM64T (Extended Memory 64 Technology) – сняла и это ограничение.

Слайд 6Скорость выполнения инструкций и полнота базового набора инструкций: (качество ALU ?)
Производительность
зависит от того, насколько качественно реализованы инструкции, насколько полно базовый набор инструкций покрывает все возможные задачи.
CISC,RISC (complex, reduced instruction set computing)
Современные Интел процессоры представляют собой гибрид CISC и RISC процессоров, перед исполнением преобразуют CISC инструкции в более простой набор RISC инструкций.
В Pentium III новая технология SSE (Streaming SIMD Extensions), которая добавила в МП 8 128 битных регистра (XMM0-XMM7) и 70 новых инструкций в том числе для работы с вещественными числами. SSE2,SSE3,SSEE3,SSE4 – последующие расширения этой идеи.
CISC,RISC (complex, reduced instruction set computing)
Современные Интел процессоры представляют собой гибрид CISC и RISC процессоров, перед исполнением преобразуют CISC инструкции в более простой набор RISC инструкций.
В Pentium III новая технология SSE (Streaming SIMD Extensions), которая добавила в МП 8 128 битных регистра (XMM0-XMM7) и 70 новых инструкций в том числе для работы с вещественными числами. SSE2,SSE3,SSEE3,SSE4 – последующие расширения этой идеи.
Производительность зависит от того, насколько")
Слайд 7Использование внутренней памяти, распределение регистров:
Скорость доступа к внешней памяти
значительно ниже скорости вычислений.
Cоздание на процессоре кэш-памяти. Блоки оперативной памяти отображаются на быстрый кэш.
«Попадание» и «промах» (cash miss).
Различные виды кэш-памяти.
полностью ассоциативная кэш-память (каждый блок может отображаться в любое место кэша)
память с прямым отображением (каждый блок может отображаться в одно место)
различные гибридные варианты (секторная память, память с множественно-ассоциативным доступом)
Множественно-ассоциативный доступ – по младшим разрядам определяется строка кэша, где может отображаться данная память, но в этой строке может находиться несколько слов основной памяти, выбор из которых проводится на ассоциативной основе.
Работа с регистрами:
Технология EM64T – добавлены дополнительные системные регистры.
Регистры – самая быстрая память процессора. Чем больше регистров, тем больше временных данных может быть размещено для вычислений в ALU.
Cоздание на процессоре кэш-памяти. Блоки оперативной памяти отображаются на быстрый кэш.
«Попадание» и «промах» (cash miss).
Различные виды кэш-памяти.
полностью ассоциативная кэш-память (каждый блок может отображаться в любое место кэша)
память с прямым отображением (каждый блок может отображаться в одно место)
различные гибридные варианты (секторная память, память с множественно-ассоциативным доступом)
Множественно-ассоциативный доступ – по младшим разрядам определяется строка кэша, где может отображаться данная память, но в этой строке может находиться несколько слов основной памяти, выбор из которых проводится на ассоциативной основе.
Работа с регистрами:
Технология EM64T – добавлены дополнительные системные регистры.
Регистры – самая быстрая память процессора. Чем больше регистров, тем больше временных данных может быть размещено для вычислений в ALU.

Слайд 8Конвейер
Instruction
fetch
Register
fetch
Instruction
decode
Execution
Data
fetch
Write
back
instr. 1
-
-
-
-
-
instr. 2
instr. 1
-
-
-
-
instr. 3
instr. 1
-
-
-
instr. 4
instr. 1
-
-
instr. 5
instr.
1
-
instr. 1
instr. 2
instr. 2
instr. 2
instr. 2
instr. 2
instr. 3
instr. 3
instr. 3
instr. 3
instr. 4
instr. 4
instr. 4
instr. 5
instr. 5
instr. 6
instr. 6
instr. 7
tick
0
1
2
3
4
5
6
Качество работы командного устройства (CU)

Слайд 9 Качество конвейеризации, уровень параллелизма инструкций
Конвейеризация предполагает, что последовательные
инструкции будут перекрываться при выполнении.
Выполнение типичной команды можно разделить на следующие этапы:
выборка команды – IF;
декодирование команды / выборка операндов из регистров - ID;
выполнение операции / вычисление эффективного адреса памяти - EX;
обращение к памяти - MEM;
запоминание результата - WB.
Конвейеризация улучшает пропускную способность процессора, но если инструкции зависят от результата предыдущих инструкций, то возникают задержки. Т.е. польза от конвейеризации определяется уровнем параллелизма инструкций.
Выполнение типичной команды можно разделить на следующие этапы:
выборка команды – IF;
декодирование команды / выборка операндов из регистров - ID;
выполнение операции / вычисление эффективного адреса памяти - EX;
обращение к памяти - MEM;
запоминание результата - WB.
Конвейеризация улучшает пропускную способность процессора, но если инструкции зависят от результата предыдущих инструкций, то возникают задержки. Т.е. польза от конвейеризации определяется уровнем параллелизма инструкций.

Слайд 10Качество предсказания переходов:
Инструкции могут быть зависимыми по данным и по
управляющей логике программы. (Data dependence and control flow dependence).
Эффективность конвейерных механизмов ограничивается различными условными переходами внутри программы.
Механизм предсказания переходов (branch prediction). МП выбирает один из возможных направлений потока управления и продолжает выбирать инструкции и нагружать конвейеры МП работой.
Ошибка предсказания (branch misprediction) вызывает большую задержку при выполнении программы, поскольку вызывают необходимость заново заполнить конвейеры МП.
Существует также механизм предсказания цели ветвления (branch target prediction), который предсказывает безусловные переходы.
Эффективность конвейерных механизмов ограничивается различными условными переходами внутри программы.
Механизм предсказания переходов (branch prediction). МП выбирает один из возможных направлений потока управления и продолжает выбирать инструкции и нагружать конвейеры МП работой.
Ошибка предсказания (branch misprediction) вызывает большую задержку при выполнении программы, поскольку вызывают необходимость заново заполнить конвейеры МП.
Существует также механизм предсказания цели ветвления (branch target prediction), который предсказывает безусловные переходы.

Слайд 11Качество упреждающей выборки:
Поскольку программы часто работают с протяженными данными (структурами, массивами),
то кэш оказывается неэффективным из-за большого количества промахов. Для преодоления этой проблемы был разработан механизм упреждающей выборки данных (data prefetching). МП, заметив тенденцию в обращении к памяти, пытается заранее закачать требуемую память в кэш.
Помимо процессорного механизма упреждающей выборки есть программный механизм упреждающей выборки.
Помимо процессорного механизма упреждающей выборки есть программный механизм упреждающей выборки.
, то кэш оказывается неэффективным")
Слайд 12Суперскалярность:
Суперскалярный процессор – это процессор способный выполнять несколько операций за один
такт.
Несколько исполнительных устройств в ALU (execution unit)
Основными компонентами суперскалярного процессора являются устройства для интерпретации команд, снабженные логикой, позволяющей определить, являются ли команды независимыми, и достаточное число исполняющих устройств. В исполняющих устройствах могут быть конвейеры.
Первым суперскалярным процессором x86 архитектуры был Pentium. В нем исполнительный блок был реализован в виде двух параллельных конвейеров (U и V). U мог исполнять все инструкции, в то время как V – простейшие наиболее часто выполняемые инструкции.
Выигрыш от суперскалярности также определяется уровнем параллелизма инструкций. Т.е. насколько последующая инструкция зависит от результатов выполнения предыдущей.
Несколько исполнительных устройств в ALU (execution unit)
Основными компонентами суперскалярного процессора являются устройства для интерпретации команд, снабженные логикой, позволяющей определить, являются ли команды независимыми, и достаточное число исполняющих устройств. В исполняющих устройствах могут быть конвейеры.
Первым суперскалярным процессором x86 архитектуры был Pentium. В нем исполнительный блок был реализован в виде двух параллельных конвейеров (U и V). U мог исполнять все инструкции, в то время как V – простейшие наиболее часто выполняемые инструкции.
Выигрыш от суперскалярности также определяется уровнем параллелизма инструкций. Т.е. насколько последующая инструкция зависит от результатов выполнения предыдущей.

Слайд 13Упрощенная модель процессора
Оперативная
память
(RAM)
Упреждающая выборка
Вычислительное
устройство
(ALU)
Управляющее
устройство
(CU)
Устройство
взаимодействия
с внешней
памятью
Внешняя
память
Шина
ввода-вывода
Суперскалярность
Конвейеризация, предсказание переходов
Регистры
Вычислительное
устройство
(ALU)
Регистры
Система
кэшей
Упреждающая выборкаВычислительное устройство(ALU)Управляющееустройство(CU)Устройство взаимодействияс внешней памятьюВнешняя памятьШинаввода-выводаСуперскалярностьКонвейеризация, предсказание переходовРегистрыВычислительное устройство(ALU)РегистрыСистема кэшей")
Слайд 14Параллелизация и многоядерность:
Многозадачность, многопоточность.
Одновременно выполняющиеся потоки конкурируют за ресурсы микропроцессора.
Ммногоядерные
МП (multi-core). Это процессор, который содержит несколько ядер (более или менее независимых процессоров) в одном пакете. Эти ядра содержат всю функциональность обычного процессора, но совместно используют системную шину и кэши.
Также для увеличения производительности используются многопроцессорные решения. Современные системы имеют по паре двух, а то и четырехядерных МП.
Также для увеличения производительности используются многопроцессорные решения. Современные системы имеют по паре двух, а то и четырехядерных МП.
. Это процессор,")
Слайд 15Основные характеристики влияющие на производительность МП
Эффективность работы с кэш-памятью.
Правильное предсказание
переходов.
Эффективность использования векторных инструкций.
Эффективность параллелизации.
Уровень параллелилизма.
Эффективность использования векторных инструкций.
Эффективность параллелизации.
Уровень параллелилизма.

Слайд 16Измерение производительности
Потребителям необходимы критерии определения производительности вычислительной системы.
Репрезентативная выборка типичных
задач.
Универсальная схема тестирования
Независимость от производителей МП
Spec.org (Standart Performance Evaluated Corporation) – некоммерческая организация для подготовки, поддержки и сопровождения стандартного набора тестов для сравнения производительности различных вычислительных систем. Эта организация разрабатывает стандартные сюиты и публикует результаты измерений.
CPU2006 – разработана для измерения производительности. Может быть использована для сравнения работы программ выполняемых на различных вычислительных системах. CINT2006 для целочисленных вычислений.
CFP2006 для сравнения производительности работы с вещественными числами.
OMP2001 – измеряет производительность тестов использующих OpenMP стандарт для параллельных вычислений с совместно используемой памятью (shared-memory parallel processing).
Универсальная схема тестирования
Независимость от производителей МП
Spec.org (Standart Performance Evaluated Corporation) – некоммерческая организация для подготовки, поддержки и сопровождения стандартного набора тестов для сравнения производительности различных вычислительных систем. Эта организация разрабатывает стандартные сюиты и публикует результаты измерений.
CPU2006 – разработана для измерения производительности. Может быть использована для сравнения работы программ выполняемых на различных вычислительных системах. CINT2006 для целочисленных вычислений.
CFP2006 для сравнения производительности работы с вещественными числами.
OMP2001 – измеряет производительность тестов использующих OpenMP стандарт для параллельных вычислений с совместно используемой памятью (shared-memory parallel processing).

Слайд 17Место и роль компилятора.
Компиля́тор — транслятор — транслятор, который осуществляет
перевод всей исходной программы в эквивалентную ей результирующую программу на языке машинных команд или на языке ассемблера.
Играет ли компилятор какую-либо роль в борьбе за производительность МП?
Компилятор используется во время тестирования и отладки функциональности новых МП.
Только с помощью компилятора можно показать рост производительности МП связанный с новыми командами, увеличением количества регистров и т.п.
Компилятор способен скрыть неудачи архитекторов.
Играет ли компилятор какую-либо роль в борьбе за производительность МП?
Компилятор используется во время тестирования и отладки функциональности новых МП.
Только с помощью компилятора можно показать рост производительности МП связанный с новыми командами, увеличением количества регистров и т.п.
Компилятор способен скрыть неудачи архитекторов.

Слайд 18 Программа должна быть:
Легко читаемой и модифицируемой
Легко отлаживаемой
Быстро исполняемой
Cовременный компилятор должен
уметь:
создавать исполняемый модуль под любую архитектуру
варьировать уровни отладки и быстродействия.
Чтобы использовать умело средства компилятора, программист должен как минимум:
иметь представления о архитектуре, на которой будет использоваться его программа.
ознакомиться с флагами компилятора.
ознакомиться с основными техниками улучшения производительности, которые использует компилятор.
ознакомиться с основными проблемами вызывающими замедление работы программы.
знать примерные данные, с которыми будет работать программа.
уметь пользоваться инструментами для анализа производительности программы.
создавать исполняемый модуль под любую архитектуру
варьировать уровни отладки и быстродействия.
Чтобы использовать умело средства компилятора, программист должен как минимум:
иметь представления о архитектуре, на которой будет использоваться его программа.
ознакомиться с флагами компилятора.
ознакомиться с основными техниками улучшения производительности, которые использует компилятор.
ознакомиться с основными проблемами вызывающими замедление работы программы.
знать примерные данные, с которыми будет работать программа.
уметь пользоваться инструментами для анализа производительности программы.

Слайд 19 Мы обсуждали факторы влияющие на производительность. В каких случаях компилятор
способен помочь МП достичь наилучшей производительности?
Тактовая частота процессора
Объем адресуемой памяти и скорость доступа к внешней памяти
Скорость выполнения инструкций и полнота базового набора инструкций
Использование внутренней памяти, распределение регистров
Уровень конвейеризации
Качество предсказания переходов
Качество упреждающей выборки
Суперскалярность
Параллелизация и многоядерность
Тактовая частота процессора
Объем адресуемой памяти и скорость доступа к внешней памяти
Скорость выполнения инструкций и полнота базового набора инструкций
Использование внутренней памяти, распределение регистров
Уровень конвейеризации
Качество предсказания переходов
Качество упреждающей выборки
Суперскалярность
Параллелизация и многоядерность

Слайд 20Скорость выполнения инструкций и полнота базового набора инструкций.
В общем случае, одни
и те же конструкции языка высокого уровня могут быть по разному реализованы в машинных кодах.
Скалярные оптимизации
Цикловые оптимизации
Векторизация
Межпроцедурный анализ
…
- все эти оптимизации призваны создать оптимальный набор машинных инструкций соответствующих коду программы.
Скалярные оптимизации
Цикловые оптимизации
Векторизация
Межпроцедурный анализ
…
- все эти оптимизации призваны создать оптимальный набор машинных инструкций соответствующих коду программы.

Слайд 21Использование внутренней памяти, распределение регистров.
Трансформация данных
Оптимизации циклов (Перестановка циклов, объединение циклов
// Loop interchange, loop fusion)
Уровень конвейеризации
За счет улучшения инструкционного параллелизма.
Оптимизации циклов (Объединение циклов)
Качество предсказания переходов
Статический и динамический профилировщик
Оптимизации циклов
Межпроцедурный анализ, инлайнинг функций
Качество упреждающей выборки
Программная упреждающая выборка (Software prefetch)
Суперскалярность
Улучшение параллелизма инструкций
Параллелизация и многоядерность
Автоматическая параллелизация
Уровень конвейеризации
За счет улучшения инструкционного параллелизма.
Оптимизации циклов (Объединение циклов)
Качество предсказания переходов
Статический и динамический профилировщик
Оптимизации циклов
Межпроцедурный анализ, инлайнинг функций
Качество упреждающей выборки
Программная упреждающая выборка (Software prefetch)
Суперскалярность
Улучшение параллелизма инструкций
Параллелизация и многоядерность
Автоматическая параллелизация

Слайд 22Интеловские компиляторы
Интел имеет С/C++ и Фортран для операционных платформ
Windows, Linux и Mac OS.
Для Windows INTEL компилятор сделан как настройка к Microsoft Visual Studio.
Главной целью корпорации является высокая производительность компиляторов и совместимость с Microsoft Visual Studio на Windows платформе и gcc на Linux и Mac OS.
Для Windows INTEL компилятор сделан как настройка к Microsoft Visual Studio.
Главной целью корпорации является высокая производительность компиляторов и совместимость с Microsoft Visual Studio на Windows платформе и gcc на Linux и Mac OS.

Слайд 23Оптимизации:
1.) Скалярные оптимизации
Свертка констант, протяжка констант, протяжка копий (Constant folding, constant
propagation, copy propagation)
Удаление общих подвыражений (Common subexpression elimination)
Удаление мертвого кода (Dead code elimination)
Удаление общих подвыражений (Common subexpression elimination)
Удаление мертвого кода (Dead code elimination)
 Скалярные оптимизацииСвертка констант, протяжка констант, протяжка копий (Constant folding, constant propagation, copy propagation)Удаление общих")
Слайд 242.) Цикловые оптимизации
Вынесение инвариантов цикла (Loop invariant code motion)
Вынесение условных переходов
(Loop unswitching)
Развертка цикла (Loop unrolling)
Перестановка циклов (Loop interchange)
Разбиение, объединение циклов (Loop distribution, loop fusion)
Развертка цикла (Loop unrolling)
Перестановка циклов (Loop interchange)
Разбиение, объединение циклов (Loop distribution, loop fusion)
 Цикловые оптимизацииВынесение инвариантов цикла (Loop invariant code motion)Вынесение условных переходов (Loop unswitching)Развертка цикла (Loop")
Слайд 25 Помимо этих оптимизаций существуют и другие, порой очень разнообразные:
Strength reduction
Scalar expansion
Loop tiling
Loop skewing
Loop coalescing
Loop collapsing и многие другие.
Одна из основных проблем и задач компилятора – доказательство правомерности тех или иных оптимизаций и оценка их выгодности.

Слайд 263.) Векторизация
Векторизация, в компьютерной науке, это процесс конвертации программы из
скалярного вида, который выполняет операции с парой операндов в векторизованную программу в которой каждая инструкция выполняется с парой векторных операндов.
DO I=1,100
A(I)=B(I)
END DO
Векторизация
DO I=1,25
A(I:I+4)=B(I:I+4)
END DO
Влияние выравнивания (alignment) на производительность.
Компилятор выполняет векторизацию, условную векторизацию.
DO I=1,100
A(I)=B(I)
END DO
Векторизация
DO I=1,25
A(I:I+4)=B(I:I+4)
END DO
Влияние выравнивания (alignment) на производительность.
Компилятор выполняет векторизацию, условную векторизацию.
 Векторизация Векторизация, в компьютерной науке, это процесс конвертации программы из скалярного вида, который выполняет")
Слайд 274.)Автоматическая параллелизация
Автоматическая параллелизация – это процесс автоматического преобразования последовательного программного
кода в многопоточный (multi-threaded) код для того чтобы использовать несколько вычислительных устройств одновременно. Актуально для современных многопроцессорных и многоядерных машин.
OpenMP (Open Multi-Processing) – это программный интерфейс, который поддерживает многоплатформенное многопроцессорное программирование с общей памятью на C/C++ и Фортране на многих архитектурах.
OpenMP (Open Multi-Processing) – это программный интерфейс, который поддерживает многоплатформенное многопроцессорное программирование с общей памятью на C/C++ и Фортране на многих архитектурах.
Автоматическая параллелизация Автоматическая параллелизация – это процесс автоматического преобразования последовательного программного кода в многопоточный (multi-threaded)")
Слайд 285.)Оптимизация вызовов функций, межпроцедурный анализ.
Инлайнинг – эта оптимизация вставляет код
функции вместо вызова функции.
Частичный инлайнинг (partial inlining) – инлайнинг части вызываемой функции внутрь вызывающей.
Протяжка аттрибутов функций.
Протяжка аттрибутов переменных.
Изменение области видимости переменных.
LPT анализ
Анализ потока данных
Функции, используемые только в одной программе получают атрибут static.
Удаление неиспользуемых глобальных переменных.
Удаление мертвого кода.
Протяжка информации о выравнивании аргументов.
Быстрый анализ типов. (Rapid type analysis)
Частичный инлайнинг (partial inlining) – инлайнинг части вызываемой функции внутрь вызывающей.
Протяжка аттрибутов функций.
Протяжка аттрибутов переменных.
Изменение области видимости переменных.
LPT анализ
Анализ потока данных
Функции, используемые только в одной программе получают атрибут static.
Удаление неиспользуемых глобальных переменных.
Удаление мертвого кода.
Протяжка информации о выравнивании аргументов.
Быстрый анализ типов. (Rapid type analysis)
Оптимизация вызовов функций, межпроцедурный анализ. Инлайнинг – эта оптимизация вставляет код функции вместо вызова функции.Частичный")
Слайд 29Статический и динамический профилировщики.
Подсчет «весовых» характеристик – вероятность перехода, вес
базового блока.
Используется при многих оптимизациях (трансформация данных).
Статический профилировщик вычисляет характеристики анализируя исходный код программы.
Динамический профилировщик работает в два прохода: создает инструментированную версию программы и прогоняет ее с неким репрезентативным набором данных, использует собранную динамическую информацию для оптимизации программы.
Некоторые оптимизации работают только при наличии динамической информации (трансформация данных).
Используется при многих оптимизациях (трансформация данных).
Статический профилировщик вычисляет характеристики анализируя исходный код программы.
Динамический профилировщик работает в два прохода: создает инструментированную версию программы и прогоняет ее с неким репрезентативным набором данных, использует собранную динамическую информацию для оптимизации программы.
Некоторые оптимизации работают только при наличии динамической информации (трансформация данных).

Слайд 30Зависимость основных характеристик компиляции.
Производительность программы
Время компиляции
Размер кода
Отладка, надежность

Слайд 31Пошаговый алгоритм отладки/улучшения производительности программы
1.) Проверка корректности (/Od, -O0)
Версия 11.0 по
умолчанию включает векторизатор. Для того чтобы выполнять программу на старых процессорах “-mia32”
2.) Отладка.
-g или –debug [keyword] (all,full,minimal)
3.) Используйте стандартные опции оптимизации –O1, -O2, -O3
4.) Использование процессорно специфических опций
-xSSE3, -xSSSE3, -xSSE4.2
Можно так-же использовать –xhost и в этом случае компилятор будет использовать наиболее продвинутые опции процессора на котором выполняется компиляция.
5.) Использование VTune Performance Analyzer. Нахождение горячих функций и мест, где тратиться наибольшее процессорное время.
2.) Отладка.
-g или –debug [keyword] (all,full,minimal)
3.) Используйте стандартные опции оптимизации –O1, -O2, -O3
4.) Использование процессорно специфических опций
-xSSE3, -xSSSE3, -xSSE4.2
Можно так-же использовать –xhost и в этом случае компилятор будет использовать наиболее продвинутые опции процессора на котором выполняется компиляция.
5.) Использование VTune Performance Analyzer. Нахождение горячих функций и мест, где тратиться наибольшее процессорное время.
 Проверка корректности (/Od, -O0)Версия 11.0 по умолчанию включает векторизатор. Для")
Слайд 32Инструменты и методы используемые для оптимизации производительности программы.
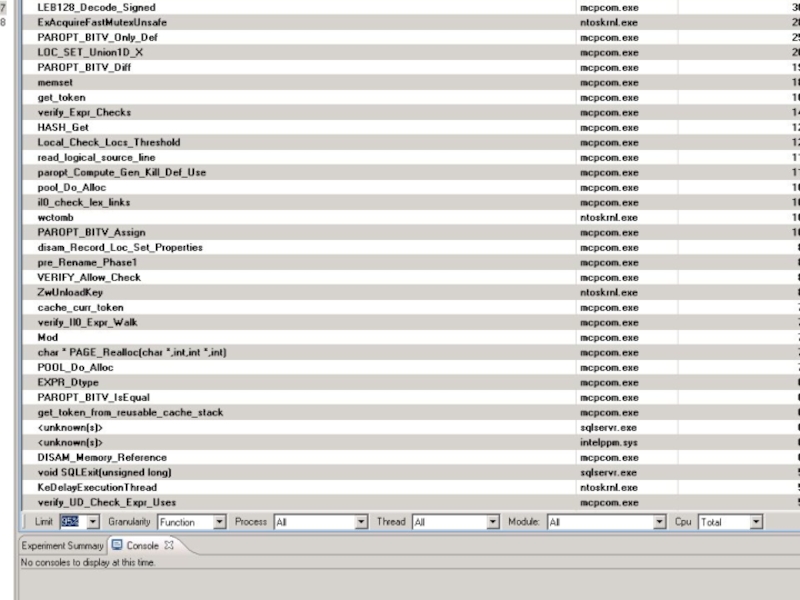
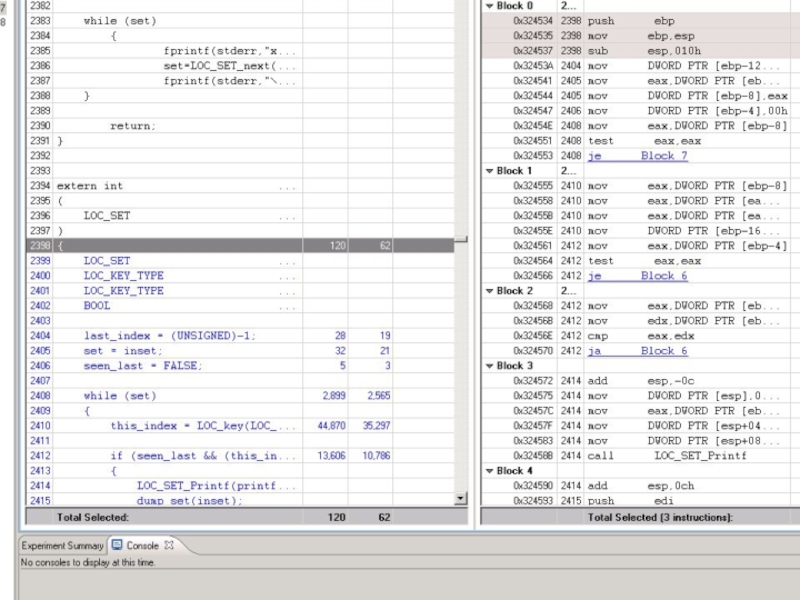
Intel VTune Performance
Analyzer – это инструмент предназначенный для анализа производительности программ. Он позволяет легко найти проблемные узкие места и проанализировать их. Для этого нужен только исполняемый файл. Желательно, чтобы он содержал информацию о строках кода.

Слайд 35 6.) Добавление межпроцедурных оптимизаций –ipo
7.) Использование динамического профилировщика.
построение программы
с опцией
-prof-gen (программа с инструментированием)
прогон с представительным набором данных (несколькими наборами)
построение программы с опцией –prof-use
8.) использование автоматической параллелизации –parallel для автоматической распараллелизации циклов.
9.) использовать OPENMP директивы и опцию –openmp для генерации многопоточного кода
-prof-gen (программа с инструментированием)
прогон с представительным набором данных (несколькими наборами)
построение программы с опцией –prof-use
8.) использование автоматической параллелизации –parallel для автоматической распараллелизации циклов.
9.) использовать OPENMP директивы и опцию –openmp для генерации многопоточного кода
 Добавление межпроцедурных оптимизаций –ipo7.) Использование динамического профилировщика. построение программы с опцией -prof-gen (программа")