институт проблем информатики Национальной академии наук Беларуси (ОИПИ НАН Беларуси),
Зав. лабораторией идентификации систем
Другие дисциплины: СиФО ЭВМ, АП ВМиС
Научные интересы:
автоматизация логического проектирования дискретных устройств
цифровая обработка изображений и распознавание образов
системы компьютерного зрения
К.т.н. - Синтез быстродействующих дискретных устройств на программируемых логических матрицах
Д.т.н. - Методы обработки и анализа цифровых изображений топологических слоев интегральных микросхем
- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Интерфейсы и периферийные устройства презентация
Содержание
- 1. Интерфейсы и периферийные устройства
- 2. План Предмет, цели и задачи курса «ИПУ»
- 3. Предмет курса Предмет курса «ИПУ» - это
- 4. Цели и задачи Цель курса – в
- 5. Рекомендуемая литература Авдеев, В.А. Периферийные устройства:
- 6. Периферия Периферия Архитектура ЭВМ Вычислительное ядро Устройство
- 7. Архитектура ЭВМ Принципы концепции ВМ фон Неймана
- 8. Состав ВМ. Ядро В составе ВМ (или
- 9. Периферия Все устройства, не входящие в вычислительное
- 10. Классификация ПУ Первоначальное деление периферийных устройств по
- 11. Классификация ПУ Устройства ввода предназначены для преобразования
- 12. Другие критерии классификации ПУ можно также классифицировать
- 13. Определение понятий «шина» ПУ и системные компоненты
- 14. Параметры, характеризующие шину совокупность сигнальных линий; физические,
- 15. Протоколы - строго заданная процедура или
- 16. Транзакции Операции на шине называют транзакциями.
- 17. Арбитраж В принципе к шине может быть
- 18. Схемы приоритетов Известны разные схемы приоритетов.
- 19. Наибольшее распространение получили следующие алгоритмы динамического
- 20. В алгоритме простой циклической смены приоритетов
- 21. При смене приоритетов по случайному закону
- 22. Помимо рассмотренных существует несколько алгоритмов смены
- 23. Арбитраж запросов на управление шиной может
- 24. При децентрализованном (или распределенном) арбитраже единый
- 25. Типы шин Важным критерием, определяющим характеристики шины,
- 26. Структура системной шины С целью снижения стоимости
- 27. Иерархия шин
- 29. Интерфейсы ПУ и системные компоненты ЭВМ соединяются
- 30. Интерфейсы ЭВМ
- 31. Системные интерфейсы Системные интерфейсы образуют единую логическую
- 32. Классификация интерфейсов В рамках данного курса предусматривается
- 33. Классификация интерфейсов По направлению передачи: Однонаправленные (симплексные);
- 34. Топология интерфейса
- 35. Характеристики интерфейсов Интерфейс предназначен для передачи данных,
- 36. Обмен данными с ПУ Программирование доступа к
- 37. Методы управления обменом Наиболее простым методом обмена
- 38. Методы управления обменом Метод прямого доступа к
- 39. Программные интерфейсы ПУ Разработчики новых устройств зачастую
- 40. Программные интерфейсы ПУ Использование портов ввода-вывода не
- 41. Архитектура современного ПК Оперативная память CPU 1
- 42. Архитектура современного ПК Персональный компьютер (ПК) семейства
- 43. Архитектура современного ПК Большинство систем класса ПК,
- 44. Архитектура современного ПК Подключение устройств во внутреннем
- 45. Заключение Основные понятия Архитектура ЭВМ, ядро (
- 46. Пропускная способность канала - Наибольшая возможная
Слайд 1Интерфейсы и периферийные устройства
Вводная лекция. Основные понятия
Проф., д.т.н. Дудкин Александр Арсентьевич
Объединенный

Слайд 2План
Предмет, цели и задачи курса «ИПУ»
Рекомендации по литературе
Обобщенная архитектура ЭВМ, ядро
и периферия
Классификация периферийных устройств
Классификация и характеристики интерфейсов
Методы обмена данными с периферийными устройствами
Основные программные интерфейсы доступа к периферийным устройствам
Архитектура типичной ЭВМ класса ПК, стандартные интерфейсы и устройства
56 Лекции + 24 Лаб. + Инд. Задание + контр. + Экзамен
Программа
Классификация периферийных устройств
Классификация и характеристики интерфейсов
Методы обмена данными с периферийными устройствами
Основные программные интерфейсы доступа к периферийным устройствам
Архитектура типичной ЭВМ класса ПК, стандартные интерфейсы и устройства
56 Лекции + 24 Лаб. + Инд. Задание + контр. + Экзамен
Программа

Слайд 3Предмет курса
Предмет курса «ИПУ» - это конструкция, принципы подключения и функционирования
периферийных устройств ЭВМ различного назначения, а также вопросы их практического применения и интеграции в IT-инфраструктуру с учетом их характеристик и особенностей.
Основное внимание уделяется широко распространенным в настоящее время устройствам, доступным на массовом рынке и предназначенным для подключения к системам класса ПК и Enterprise.
В рамках курса также изучается подсистема ввода-вывода современных компьютеров класса x86 (системные и периферийные шины, внутренние и внешние интерфейсы), классификация, архитектурные особенности, структура и принципы функционирования интерфейсов.
Принципы программирования тех или иных интерфейсов и устройств в лекционном курсе рассматриваются поверхностно, эти вопросы вынесены на лабораторные занятия и индивидуальное задание.
Основное внимание уделяется широко распространенным в настоящее время устройствам, доступным на массовом рынке и предназначенным для подключения к системам класса ПК и Enterprise.
В рамках курса также изучается подсистема ввода-вывода современных компьютеров класса x86 (системные и периферийные шины, внутренние и внешние интерфейсы), классификация, архитектурные особенности, структура и принципы функционирования интерфейсов.
Принципы программирования тех или иных интерфейсов и устройств в лекционном курсе рассматриваются поверхностно, эти вопросы вынесены на лабораторные занятия и индивидуальное задание.

Слайд 4Цели и задачи
Цель курса – в приобретении знаний о классификации, назначении,
конструктивных и архитектурных особенностях ПУ, технологиях их производства, принципах функционирования, основных потребительских характеристиках.
Изучение курса позволит получить знания об организации подсистемы ввода-вывода, принципах обмена информацией, принципах функционирования основных интерфейсов и шин, их характеристиках и возможностях. А также об истории возникновения, развития и перспективах развития различных платформ ЭВМ, их подсистем ввода-вывода, интерфейсах и ПУ.
Курс имеет познавательно-практическую направленность. В его рамках рассматриваются не только основы функционирования систем, интерфейсов и устройств, но и условия их появления, существования и развития. Не игнорируются такие аспекты, как потребительские свойства систем и устройств, их рыночные ниши, конкурентоспособность, оптимальные сферы применения, перспективы развития. Кратко рассматриваются перспективные решения и разработки.
Изучение курса позволит получить знания об организации подсистемы ввода-вывода, принципах обмена информацией, принципах функционирования основных интерфейсов и шин, их характеристиках и возможностях. А также об истории возникновения, развития и перспективах развития различных платформ ЭВМ, их подсистем ввода-вывода, интерфейсах и ПУ.
Курс имеет познавательно-практическую направленность. В его рамках рассматриваются не только основы функционирования систем, интерфейсов и устройств, но и условия их появления, существования и развития. Не игнорируются такие аспекты, как потребительские свойства систем и устройств, их рыночные ниши, конкурентоспособность, оптимальные сферы применения, перспективы развития. Кратко рассматриваются перспективные решения и разработки.

Слайд 5Рекомендуемая литература
Авдеев, В.А. Периферийные устройства: интерфейсы, схемотехника, программирование / В.А. Авдеев.
– М.: ДМК Пресс, 2012 г. - 848 с.
Гук, М.Ю. Аппаратные интерфейсы ПК. Энциклопедия / М.Ю. Гук. - СПб.: Питер, 2006. – 1072 с.
Гук, М.Ю. Шины PCI, USB и FireWire. Энциклопедия / М.Ю. Гук. - СПб.: Питер, 2005. – 540 с.
Петров, С.В. Шины PCI, PCI Express. Архитектура, дизайн, принципы функционирования / С.В. Петров. – СПб.: БХВ, 2006. – 416 с.
Гук, М.Ю. Дисковая подсистема ПК / М.Ю. Гук. - СПб: Питер, 2001. - 336 с.
Гук, М. Интерфейсы устройств хранения: ATA, SCSI и другие. Энциклопедия / М. Гук. - СПб.: Питер, 2006. – 448 с.
Гук, М.Ю. Аппаратные интерфейсы ПК. Энциклопедия / М.Ю. Гук. - СПб.: Питер, 2006. – 1072 с.
Гук, М.Ю. Шины PCI, USB и FireWire. Энциклопедия / М.Ю. Гук. - СПб.: Питер, 2005. – 540 с.
Петров, С.В. Шины PCI, PCI Express. Архитектура, дизайн, принципы функционирования / С.В. Петров. – СПб.: БХВ, 2006. – 416 с.
Гук, М.Ю. Дисковая подсистема ПК / М.Ю. Гук. - СПб: Питер, 2001. - 336 с.
Гук, М. Интерфейсы устройств хранения: ATA, SCSI и другие. Энциклопедия / М. Гук. - СПб.: Питер, 2006. – 448 с.

Слайд 6Периферия
Периферия
Архитектура ЭВМ
Вычислительное ядро
Устройство управления
Оперативное запоминающее устройство (ОЗУ)
Вычислительное устройство (АЛУ)
Устройства ввода
Устройства вывода
Вычислительное устройство (АЛУ)Устройства вводаУстройства вывода")
Слайд 7Архитектура ЭВМ
Принципы концепции ВМ фон Неймана
Двоичного кодирования.
Однородности памяти.
Адресуемости памяти.
Последовательного программного управления.
Жесткости архитектуры.
Архитектура ЭВМ фон Неймана
• последовательно адресуемая единственная память линейного типа для хранения программ и данных;
• команды и данные различаются через идентификатор неявным способом лишь при выполнении операций (позволяют обращаться с командой как с данными, например, для ее модификации);
• назначение данных определяется лишь логикой программы, так как в памяти машины набор бит может представлять собой как десятичное число с фиксированной точкой, так и строку символов.

Слайд 8Состав ВМ. Ядро
В составе ВМ (или узла более сложной системы) можно
выделить вычислительное ядро и его периферию.
Ядро обычно состоит из АЛУ, выполняющего также некоторые из задач управления, и ОЗУ.
В современных ВМ большинство принципов фон Неймана не соблюдены:
микропроцессоров может быть несколько, и каждый обладает поддержкой многопоточности (содержит реальные или виртуальные симметричные вычислительные модули),
суперскалярность (выполнение нескольких инструкций одновременно), MISD, MIMD, переупорядочивания команд, поддержкой SIMD-инструкций.
ОЗУ – это комбинация контроллера памяти и микросхем памяти.
Ядро обычно состоит из АЛУ, выполняющего также некоторые из задач управления, и ОЗУ.
В современных ВМ большинство принципов фон Неймана не соблюдены:
микропроцессоров может быть несколько, и каждый обладает поддержкой многопоточности (содержит реальные или виртуальные симметричные вычислительные модули),
суперскалярность (выполнение нескольких инструкций одновременно), MISD, MIMD, переупорядочивания команд, поддержкой SIMD-инструкций.
ОЗУ – это комбинация контроллера памяти и микросхем памяти.
 можно выделить вычислительное ядро и")
Слайд 9Периферия
Все устройства, не входящие в вычислительное ядро (ядра), относятся к периферийным.
Они могут располагаться снаружи / внутри корпуса ЭВМ, а также входить в состав основных микросхем системы.
Основная задача периферийных устройств – поставка данных на обработку, а также вывод их за пределы вычислительного ядра. Данная задача охватывает такие процессы, как оцифровка и преобразование данных в электрическую форму (из оптической, механической, электромагнитной и т.д.), регистрация различных внешних воздействий, преобразование данных, сохранение на внешних носителях, изготовление «твердой копии» на бумаге, передача по каналам связи, отображение в графической форме на экране и т.д.
Можно выделить отдельный класс устройств управления и обслуживания системы (system management and control), которые по назначению неправомерно относить к периферийным. Однако по принципу действия они являются именно периферийными.
Основная задача периферийных устройств – поставка данных на обработку, а также вывод их за пределы вычислительного ядра. Данная задача охватывает такие процессы, как оцифровка и преобразование данных в электрическую форму (из оптической, механической, электромагнитной и т.д.), регистрация различных внешних воздействий, преобразование данных, сохранение на внешних носителях, изготовление «твердой копии» на бумаге, передача по каналам связи, отображение в графической форме на экране и т.д.
Можно выделить отдельный класс устройств управления и обслуживания системы (system management and control), которые по назначению неправомерно относить к периферийным. Однако по принципу действия они являются именно периферийными.
, относятся к периферийным. Они могут располагаться снаружи")
Слайд 10Классификация ПУ
Первоначальное деление периферийных устройств по назначению на устройства ввода и
вывода неполно описывает их особенности.
Общепринятым и более полным является деление на 4 базовых класса:
Общепринятым и более полным является деление на 4 базовых класса:

Слайд 11Классификация ПУ
Устройства ввода предназначены для преобразования информации некоторой физической природы в
электрические сигналы, пригодные для обработки ядром системы.
Устройства вывода оформляют информацию, обработанную ядром системы, таким образом, что она становится пригодной для обработки человеком или другой системой.
Устройства хранения данных обеспечивают хранение и последующую загрузку машинного кода и/или данных. По сути они расширяют объем оперативной памяти системы, но, в отличие от нее, не обеспечивают непосредственного доступа со стороны процессора.
Сетевые и коммуникационные устройства (Network & Communication) выполняют передачу данных между вычислительными системами, минуя промежуточные носители информации. Как правило, передача выполняется на большие расстояния, не сравнимые с размерами самой ЭВМ, и требует затрат на кодирование для защиты от искажений, помех, потери, злонамеренного перехвата и т.п.
Устройства вывода оформляют информацию, обработанную ядром системы, таким образом, что она становится пригодной для обработки человеком или другой системой.
Устройства хранения данных обеспечивают хранение и последующую загрузку машинного кода и/или данных. По сути они расширяют объем оперативной памяти системы, но, в отличие от нее, не обеспечивают непосредственного доступа со стороны процессора.
Сетевые и коммуникационные устройства (Network & Communication) выполняют передачу данных между вычислительными системами, минуя промежуточные носители информации. Как правило, передача выполняется на большие расстояния, не сравнимые с размерами самой ЭВМ, и требует затрат на кодирование для защиты от искажений, помех, потери, злонамеренного перехвата и т.п.

Слайд 12Другие критерии классификации
ПУ можно также классифицировать по другим признакам, например, по
конструктивному исполнению:
Внешние – имеющие свой корпус и (зачастую) отдельный источник питания (если питание по интерфейсу не предусмотрено или его мощности недостаточно).
Внутренние – расположенные внутри корпуса системы и питающиеся от системного блока питания или интерфейса.
Встроенные – расположенные на системной (материнской) плате или являющиеся частью одной из микросхем на этой плате.
Общепринятой является классификация по основной функции ПУ. При этом в одном физическом корпусе могут объединяться несколько устройств различного класса (монитор со встроенными колонками и камерой, клавиатура с IP-телефоном, МФУ с принтером, сканером и факс-аппаратом и т.д.).
Каждому классу устройств присущ свой набор характеристик.
Внешние – имеющие свой корпус и (зачастую) отдельный источник питания (если питание по интерфейсу не предусмотрено или его мощности недостаточно).
Внутренние – расположенные внутри корпуса системы и питающиеся от системного блока питания или интерфейса.
Встроенные – расположенные на системной (материнской) плате или являющиеся частью одной из микросхем на этой плате.
Общепринятой является классификация по основной функции ПУ. При этом в одном физическом корпусе могут объединяться несколько устройств различного класса (монитор со встроенными колонками и камерой, клавиатура с IP-телефоном, МФУ с принтером, сканером и факс-аппаратом и т.д.).
Каждому классу устройств присущ свой набор характеристик.

Слайд 13Определение понятий «шина»
ПУ и системные компоненты ЭВМ соединяются друг с другом
посредством средств подключения, организованных по иерархическому принципу.
Средства (аппаратные и программные), используемые для соединения двух компонентов или систем, называются интерфейсом.
Система шин,
иерархия шин оптимизирована под определенный вид коммуникаций
Чтобы охарактеризовать конкретную шину, нужно описать:
Средства (аппаратные и программные), используемые для соединения двух компонентов или систем, называются интерфейсом.
Система шин,
иерархия шин оптимизирована под определенный вид коммуникаций
Чтобы охарактеризовать конкретную шину, нужно описать:

Слайд 14Параметры, характеризующие шину
совокупность сигнальных линий;
физические, механические и электрические характеристики шины;
используемые сигналы
арбитража, состояния, управления и синхронизации;
правила взаимодействия подключенных к шине устройств (протокол шины).
правила взаимодействия подключенных к шине устройств (протокол шины).

Слайд 15
Протоколы - строго заданная процедура или совокупность правил, определяющая способ выполнения
определенного класса функций соответствующими СВТ.
Практически любой интерфейс содержит больше или меньше элементов протокола, определяемых процедурными и функциональными интерфейсами.
Практически любой интерфейс содержит больше или меньше элементов протокола, определяемых процедурными и функциональными интерфейсами.

Слайд 16Транзакции
Операции на шине называют транзакциями.
Основные виды транзакций -транзакции чтения и
транзакции записи. Если в обмене участвует устройство ввода/вывода, можно говорить о транзакциях ввода и вывода, по сути эквивалентных транзакциям чтения и записи соответственно. Шинная транзакция включает в себя две части: посылку адреса и прием (или посылку) данных.
Когда два устройства обмениваются информацией по шине, одно из них должно инициировать обмен и управлять им. Такого рода устройства называют ведущими (bus master). В компьютерной терминологии «ведущий» — это любое устройство, способное взять на себя владение шиной и управлять пересылкой данных. Ведущий не обязательно использует данные сам. Он, например, может захватить управление шиной в интересах другого устройства. Устройства, не обладающие возможностями инициирования транзакции, носят название ведомых (bus slave).
Когда два устройства обмениваются информацией по шине, одно из них должно инициировать обмен и управлять им. Такого рода устройства называют ведущими (bus master). В компьютерной терминологии «ведущий» — это любое устройство, способное взять на себя владение шиной и управлять пересылкой данных. Ведущий не обязательно использует данные сам. Он, например, может захватить управление шиной в интересах другого устройства. Устройства, не обладающие возможностями инициирования транзакции, носят название ведомых (bus slave).

Слайд 17Арбитраж
В принципе к шине может быть подключено несколько потенциальных ведущих, но
в любой момент времени активным может быть только один из них: если несколько устройств передают информацию одновременно, их сигналы перекрываются и искажаются. Для предотвращения одновременной активности нескольких ведущих в любой шине предусматривается процедура допуска к управлению шиной только одного из претендентов (арбитраж). В то же время некоторые шины допускают широковещательный режим записи, когда информация одного ведущего передается сразу нескольким ведомым (здесь арбитраж не требуется). Сигнал, направленный одним устройством, доступен всем остальным устройствам, подключенным к шине.

Слайд 18Схемы приоритетов
Известны разные схемы приоритетов.
Каждому потенциальному ведущему присваивается определенный уровень
приоритета, который может оставаться неизменным (статический или фиксированный приоритет)
либо изменяться по какому-либо алгоритму (динамический приоритет).
Основной недостаток статических приоритетов в том, что устройства, имеющие высокий приоритет, в состоянии полностью блокировать доступ к шине устройств с низким уровнем приоритета. Системы с динамическими приоритетами дают шанс каждому из запросивших устройств рано или поздно получить право на управление шиной, то есть в таких системах реализуется принцип равнодоступности.
либо изменяться по какому-либо алгоритму (динамический приоритет).
Основной недостаток статических приоритетов в том, что устройства, имеющие высокий приоритет, в состоянии полностью блокировать доступ к шине устройств с низким уровнем приоритета. Системы с динамическими приоритетами дают шанс каждому из запросивших устройств рано или поздно получить право на управление шиной, то есть в таких системах реализуется принцип равнодоступности.

Слайд 19
Наибольшее распространение получили следующие алгоритмы динамического изменения приоритетов:
простая циклическая смена
приоритетов,
циклическая смена приоритетов с учетом последнего запроса,
смена приоритетов по случайному закону,
схема равных приоритетов,
алгоритм «наиболее давнего» использования.
циклическая смена приоритетов с учетом последнего запроса,
смена приоритетов по случайному закону,
схема равных приоритетов,
алгоритм «наиболее давнего» использования.

Слайд 20
В алгоритме простой циклической смены приоритетов после каждого цикла арбитража все
приоритеты понижаются на один уровень, при этом устройство, имевшее ранее низший уровень приоритета, получает наивысший приоритет.
В схеме циклической смены приоритетов с учетом последнего запроса все возможные запросы упорядочиваются в виде циклического списка. После обработки очередного запроса обслуженному ведущему назначается низший уровень приоритета. Следующее в списке устройство получает наивысший приоритет, а остальным устройствам приоритеты назначаются в убывающем порядке, согласно их следованию в циклическом списке. В обеих схемах циклической смены приоритетов каждому ведущему обеспечивается шанс получить шину в свое распоряжение, однако большее распространение получил второй алгоритм.

Слайд 21
При смене приоритетов по случайному закону после очередного цикла арбитража с
помощью генератора псевдослучайных чисел каждому ведущему присваивается случайное значение уровня приоритета.
В схеме равных приоритетов при поступлении к арбитру нескольких запросов каждый из них имеет равные шансы на обслуживание. Возможный конфликт разрешается арбитром. Такая схема принята в асинхронных системах.
В алгоритме «наиболее давнего» использования после каждого цикла арбитража наивысший приоритет присваивается ведущему устройству, которое дольше чем другие не использовало шину.

Слайд 22
Помимо рассмотренных существует несколько алгоритмов смены приоритетов, которые не являются чисто
динамическими, поскольку смена приоритетов происходит не после каждого цикла арбитража. К таким алгоритмам относятся алгоритм очереди и алгоритм фиксированного кванта времени.
В алгоритме очереди запросы обслуживаются в порядке очереди, образовавшейся к моменту начала цикла арбитража. Сначала обслуживается первый запрос в очереди, то есть запрос, поступивший раньше остальных. Аппаратная реализация алгоритма связана с определенными сложностями, поэтому используется такой алгоритм редко.
В алгоритме фиксированного кванта времени каждому ведущему для захвата шины в течение цикла арбитража выделяется определенный квант времени. Если ведущий в этот момент не нуждается в шине, выделенный ему квант остается не использованным. Такой метод наиболее подходит для шин с синхронным протоколом.

Слайд 23
Арбитраж запросов на управление шиной может быть организован по централизованной или
децентрализованной схеме. Выбор конкретной схемы зависит от требований к производительности и стоимостных ограничений.
При централизованном арбитраже в системе имеется специальное устройство – центральный арбитр, которое ответственно за предоставление доступа к шине только одному из запросивших доступ ведущих устройств. Это устройство, называемое иногда центральным контроллером шины, может быть самостоятельным модулем или частью центрального процессора. Наличие на шине только одного арбитра означает, что в централизованной схеме имеется единственная точка отказа. В зависимости от того, каким образом ведущие устройства подключены к центральному арбитру, возможны параллельные и последовательные схемы централизованного арбитража.

Слайд 24
При децентрализованном (или распределенном) арбитраже единый арбитр отсутствует. Вместо этого каждый
ведущий содержит блок управления доступом к шине, и при совместном использовании шины такие блоки взаимодействуют друг с другом, разделяя между собой ответственность за доступ к шине. По сравнению с централизованной схемой децентрализованный арбитраж менее чувствителен к отказам претендующих на шину устройств. В целом схемы децентрализованного арбитража потенциально более надежны, поскольку отказ контроллера шины в одном из ведущих не нарушает работу с шиной на общем уровне. Тем не менее должны быть предусмотрены средства для обнаружения неисправных контроллеров. Основной недостаток децентрализованных схем заключается в относительной сложности логики арбитража, которая должна быть реализована в аппаратуре каждого ведущего.
 арбитраже единый арбитр отсутствует. Вместо этого каждый ведущий содержит блок управления")
Слайд 25Типы шин
Важным критерием, определяющим характеристики шины, может служить ее целевое назначение.
шины «процессор-память»;
Шина переднего плана (FSB - Front-Side Bus, обеспечивает непосредственную связь между ЦП иОП). Это Системная шина , но эффективнее – отдельная шина (для связи ЦП-кэш) - шина заднего плана — BSB (Back-Side Bus).
шины ввода/вывода;
не требуют от шины высокой пропускной способности (PCI, SCSI).

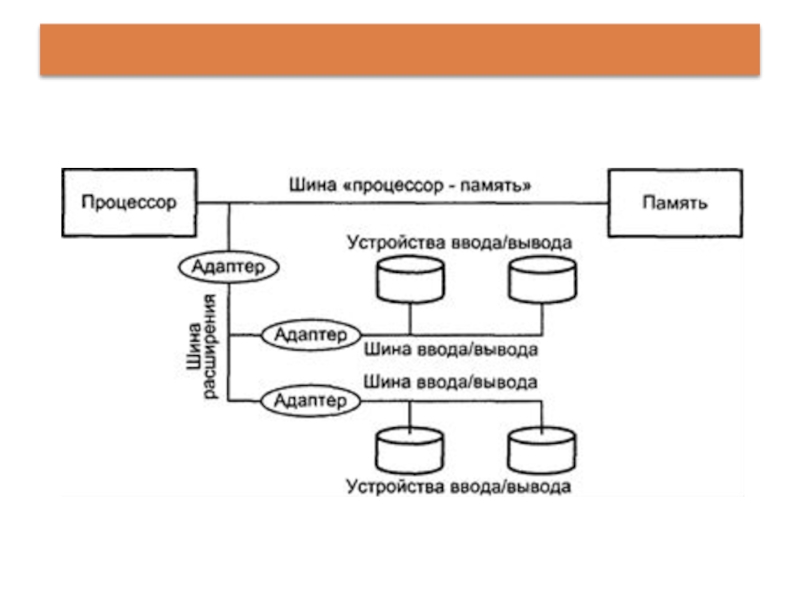
Слайд 26Структура системной шины
С целью снижения стоимости некоторые ВМ имеют общую шину
для памяти и устройств ввода/вывода. Такая шина часто называется системной. Системная шина служит для физического и логического объединения всех устройств ВМ.
3 функциональные группы
3 функциональные группы


Слайд 29Интерфейсы
ПУ и системные компоненты ЭВМ соединяются друг с другом посредством средств
подключения, организованных по иерархическому принципу.
Средства (аппаратные и программные), используемые для соединения двух компонентов или систем, называются интерфейсом.
Средства (аппаратные и программные), используемые для соединения двух компонентов или систем, называются интерфейсом.


Слайд 31Системные интерфейсы
Системные интерфейсы образуют единую логическую системную шину, по которой информация
передается в виде данных, пригодных для обработки, снабженных адресами в общем адресном пространстве системы (физические адреса, с которыми оперирует процессор).
Системная шина может быть разделена несколько шин, имеющих различную физическую природу и протоколы передачи данных (на уровне электрических и/или логических сигналов).
Как правило, все системные интерфейсы имеют электрическую природу и реализованы в виде дорожек на печатных платах (или линий внутри микросхем).
При этом шина ввода-вывода отвечает за обмен данными с контроллерами внутренних периферийных устройств и контроллерами периферийных интерфейсов.
Системная шина может быть разделена несколько шин, имеющих различную физическую природу и протоколы передачи данных (на уровне электрических и/или логических сигналов).
Как правило, все системные интерфейсы имеют электрическую природу и реализованы в виде дорожек на печатных платах (или линий внутри микросхем).
При этом шина ввода-вывода отвечает за обмен данными с контроллерами внутренних периферийных устройств и контроллерами периферийных интерфейсов.

Слайд 32Классификация интерфейсов
В рамках данного курса предусматривается изучение периферийных интерфейсов, а также
системной шины ввода-вывода, которая обеспечивает соединение между ПУ и компонентами ядра системы.
По способу кодирования и передачи данных интерфейсы делятся:
Параллельные, характеризующиеся разрядностью (количеством бит одного машинного слова, передаваемых в один момент времени);
Последовательные, характеризующиеся количеством агрегированных каналов передачи данных (количеством бит различных машинных слов, передаваемых одновременно, не обязательно синхронно и с одной скоростью).
По способу кодирования и передачи данных интерфейсы делятся:
Параллельные, характеризующиеся разрядностью (количеством бит одного машинного слова, передаваемых в один момент времени);
Последовательные, характеризующиеся количеством агрегированных каналов передачи данных (количеством бит различных машинных слов, передаваемых одновременно, не обязательно синхронно и с одной скоростью).

Слайд 33Классификация интерфейсов
По направлению передачи:
Однонаправленные (симплексные);
Двунаправленные (дуплексные);
С возможностью изменения направления передачи (полудуплексные).
Современные
последовательные интерфейсы обычно обеспечивают дуплекс за счет работы двух встречно направленных симплексных каналов. При этом зачастую в одну сторону передаются данные, а в другую – пакеты квитирования и управления потоком.
По физическому явлению, используемому для кодирования информации:
Электрические (с управлением током или напряжением);
Оптические (оптоволоконные);
Беспроводные (радио).
По физическому явлению, используемому для кодирования информации:
Электрические (с управлением током или напряжением);
Оптические (оптоволоконные);
Беспроводные (радио).
;Двунаправленные (дуплексные);С возможностью изменения направления передачи (полудуплексные).Современные последовательные интерфейсы обычно обеспечивают")

Слайд 35Характеристики интерфейсов
Интерфейс предназначен для передачи данных, адресов и управляющих сигналов, поэтому
наиважнейшей его характеристикой является скорость передачи, или пропускная способность. Она измеряется в байтах в секунду (для параллельных) или в битах в секунду (для последовательных).
Зачастую выделяют «сырую» (raw) пропускную способность, пиковую (peak), теоретическую, усредненную (реально достижимую). Связано это с затратами на кодирование, избыточность (для определения и коррекции ошибок), квитирование, арбитраж, получение доступа к среде передачи, «зазоры», процедуры установление соединения, передачу различной управляющей информации (маркеры, номера пакетов, служебные поля в пакетах и т.д.).
Другие характеристики специфичны для интерфейсов различного типа. Например, количество подключаемых устройств, расстояние подключения, количество каскадов, поддержка функций «горячего» подключения, самонастройки и т.д.
Зачастую выделяют «сырую» (raw) пропускную способность, пиковую (peak), теоретическую, усредненную (реально достижимую). Связано это с затратами на кодирование, избыточность (для определения и коррекции ошибок), квитирование, арбитраж, получение доступа к среде передачи, «зазоры», процедуры установление соединения, передачу различной управляющей информации (маркеры, номера пакетов, служебные поля в пакетах и т.д.).
Другие характеристики специфичны для интерфейсов различного типа. Например, количество подключаемых устройств, расстояние подключения, количество каскадов, поддержка функций «горячего» подключения, самонастройки и т.д.

Слайд 36Обмен данными с ПУ
Программирование доступа к ПУ в общем случае является
нетривиальной задачей, даже если не касаться особенностей работы с ПУ, связанных с архитектурой операционной системы (которая в общем случае реализует виртуализацию ПУ через систему драйверов). Единого интерфейса программирования (API) для работы с ПУ не существует, зачастую даже стандартный интерфейс для определенного типа устройств разрабатывается не сразу.
Ранее разработчики ПО полагались на API, предоставляемый системным BIOS (или BIOS самого устройства), а в сложных случаях прибегали к «ручному» программированию устройства. Однако в многозадачных средах такой подход не работает – требуется обеспечить множественный доступ к одному и тому же устройству. Реализуется это либо программно, через драйверы, либо через интеллектуальный хост-контроллер, функции которого распределены между «железом» и драйверами.
Ранее разработчики ПО полагались на API, предоставляемый системным BIOS (или BIOS самого устройства), а в сложных случаях прибегали к «ручному» программированию устройства. Однако в многозадачных средах такой подход не работает – требуется обеспечить множественный доступ к одному и тому же устройству. Реализуется это либо программно, через драйверы, либо через интеллектуальный хост-контроллер, функции которого распределены между «железом» и драйверами.

Слайд 37Методы управления обменом
Наиболее простым методом обмена является программно-управляемый доступ (программный доступ),
или PIO. Управляет обменом (определяет моменты передачи данных, подает адреса и т.д.) процессор, чаще всего центральный (но может быть и выделенный процессор ввода-вывода). При этом фактически происходит пересылка данных между регистрами процессора и регистрами/памятью ПУ (или контроллера интерфейса).
Преимущество PIO – в простоте аппаратной реализации ПУ. Требуется обеспечить лишь выставление на шину / чтение с шины содержимого регистров или ячеек памяти по сигналу доступа.
Недостаток – в низком быстродействии и необходимости задействовать процессор, который в общем случае будет простаивать ввиду более высокого быстродействия по сравнению с ПУ.
Преимущество PIO – в простоте аппаратной реализации ПУ. Требуется обеспечить лишь выставление на шину / чтение с шины содержимого регистров или ячеек памяти по сигналу доступа.
Недостаток – в низком быстродействии и необходимости задействовать процессор, который в общем случае будет простаивать ввиду более высокого быстродействия по сравнению с ПУ.
, или PIO. Управляет обменом")
Слайд 38Методы управления обменом
Метод прямого доступа к памяти (DMA) позволяет выполнять обмен
между оперативной памятью системы и ресурсами ПУ асинхронно по отношению к вычислительному процессу. Управление обменом берет на себя контроллер DMA. Последний может быть как общесистемным (как в старой архитектуре), так и входить в состав ПУ. Контроллер DMA требуется запрограммировать на пересылку данных между двумя адресатами, после чего он самостоятельно вырабатывает сигналы передачи данных.
Современные контроллеры интерфейсов снабжены интеллектуальным хост-контроллером – устройством, обеспечивающим более гибкое управление процессом обмена данными. В частности, такой хост-контроллер самостоятельно обрабатывает списки задач, формируемые в памяти системы, не требуя от процессора контроля за состоянием ПУ
Современные контроллеры интерфейсов снабжены интеллектуальным хост-контроллером – устройством, обеспечивающим более гибкое управление процессом обмена данными. В частности, такой хост-контроллер самостоятельно обрабатывает списки задач, формируемые в памяти системы, не требуя от процессора контроля за состоянием ПУ
 позволяет выполнять обмен между оперативной памятью системы")
Слайд 39Программные интерфейсы ПУ
Разработчики новых устройств зачастую создают собственные программные модели и
интерфейсы программирования, что привносит проблемы совместимости с прикладным и системным ПО. Тем не менее, для целого ряда современных устройств разработаны стандартные интерфейсы программирования. В особенности это касается универсальных внешних интерфейсов.
Изначально разработчики придерживались регистровой программной модели ПУ. Устройство представлялось программно доступным (в общем пространстве портов ввода-вывода) набором регистров, среди которых обязательно были три – состояния, управления и данных (т.н. модель CSD). Доступ предполагался методом PIO.
Устройства с большим объемом собственной памяти отображали ее на общее пространство памяти для прямого программного доступа.
Изначально разработчики придерживались регистровой программной модели ПУ. Устройство представлялось программно доступным (в общем пространстве портов ввода-вывода) набором регистров, среди которых обязательно были три – состояния, управления и данных (т.н. модель CSD). Доступ предполагался методом PIO.
Устройства с большим объемом собственной памяти отображали ее на общее пространство памяти для прямого программного доступа.

Слайд 40Программные интерфейсы ПУ
Использование портов ввода-вывода не всегда эффективно и удобно, поэтому
у современных устройств регистры обычно отображаются на пространство памяти.
По мере усложнения архитектуры и повышения требований к устройствам и интерфейсам появилась необходимость реализации более сложной многоуровневой модели программирования с применением объектно-ориентированного подхода.
Современные интерфейсы программирования устройств включают не только аппаратные, но и программные компоненты, входящие в состав ядра операционной системы. Программисту приходится иметь дело не с регистрами, а с системными объектами, а всю низкоуровневую работу с аппаратными ресурсами выполняет драйвер со стандартным интерфейсом программирования.
По мере усложнения архитектуры и повышения требований к устройствам и интерфейсам появилась необходимость реализации более сложной многоуровневой модели программирования с применением объектно-ориентированного подхода.
Современные интерфейсы программирования устройств включают не только аппаратные, но и программные компоненты, входящие в состав ядра операционной системы. Программисту приходится иметь дело не с регистрами, а с системными объектами, а всю низкоуровневую работу с аппаратными ресурсами выполняет драйвер со стандартным интерфейсом программирования.

Слайд 41Архитектура современного ПК
Оперативная память
CPU 1
CPU N
CPU 2
. . .
Коммутатор
Корневой комплекс
PCI Express
USB
Serial
ATA
Видеокарта
Ethernet MAC
HD Audio
LPC
Super I/O
PCI
HDD
Монитор

Слайд 42Архитектура современного ПК
Персональный компьютер (ПК) семейства IBM PC, будучи созданным в
качестве персонального делового инструмента для обработки текста, таблиц, баз данных и деловой графики, стал основой для большого семейства ЭВМ различного класса. Практически все ЭВМ, использующие процессоры архитектуры x86, построены на базе архитектуры IBM PC AT с некоторыми дополнениями (прежде всего в плане поддержки многопроцессорности, управления энергопотреблением, самоконфигурации и т.д.). Данная архитектура применяется также для:
серверов, в т.ч. многопроцессорных;
рабочих станций;
мобильных ПК;
встраиваемых систем (embedded);
промышленных систем (industrial );
смартфонов.
серверов, в т.ч. многопроцессорных;
рабочих станций;
мобильных ПК;
встраиваемых систем (embedded);
промышленных систем (industrial );
смартфонов.
 семейства IBM PC, будучи созданным в качестве персонального делового инструмента")
Слайд 43Архитектура современного ПК
Большинство систем класса ПК, а также «выросших» из этой
архитектуры, конструктивно состоят из следующих блоков:
материнская плата с микросхемами системной логики (чипсетом) и разъемами расширения;
процессор(ы);
модули памяти;
платы расширения;
внутренние устройства хранения данных;
устройства питания и охлаждения.
Всю периферийную часть, изначально интегрированную в систему, в общем случае можно разделить на:
графическая подсистема;
подсистема хранения данных;
подсистема интерфейса с пользователем;
аудио-подсистема;
подсистема сетевых соединений.
материнская плата с микросхемами системной логики (чипсетом) и разъемами расширения;
процессор(ы);
модули памяти;
платы расширения;
внутренние устройства хранения данных;
устройства питания и охлаждения.
Всю периферийную часть, изначально интегрированную в систему, в общем случае можно разделить на:
графическая подсистема;
подсистема хранения данных;
подсистема интерфейса с пользователем;
аудио-подсистема;
подсистема сетевых соединений.

Слайд 44Архитектура современного ПК
Подключение устройств во внутреннем исполнении (обычно они имеют контроллеры,
подключаемые к логической системной шине), обеспечивает универсальная шина ввода-вывода PCI Express, а также устаревшая шина PCI.
Подключение внешних устройств обеспечивает универсальная шина USB.
Для подключения устройств хранения данных, а также аудио- и сетевых кодеков используются специализированные интерфейсы.
Для совместимости с устройствами старого поколения сохранилась шина LPC (логически эмулирует ISA) и контроллер устаревших внешних интерфейсов Super I/O.
Подключение внешних устройств обеспечивает универсальная шина USB.
Для подключения устройств хранения данных, а также аудио- и сетевых кодеков используются специализированные интерфейсы.
Для совместимости с устройствами старого поколения сохранилась шина LPC (логически эмулирует ISA) и контроллер устаревших внешних интерфейсов Super I/O.

Слайд 45Заключение
Основные понятия
Архитектура ЭВМ, ядро ( АЛУ, УУ, ОЗУ) и ПУ
Классификация ПУ
Классификация
интерфейсов, характеристика интерфейсов
Архитектура ПК
SIMD
IP
PIO
BIOS
API
DMA
CDS
PC
X86, IBM PC AT
PCI, Serial ATA, USB, LPC, ISA, Ethernet MAC, HD Audio, Super I/O
Архитектура ПК
SIMD
IP
PIO
BIOS
API
DMA
CDS
PC
X86, IBM PC AT
PCI, Serial ATA, USB, LPC, ISA, Ethernet MAC, HD Audio, Super I/O
 и ПУКлассификация ПУКлассификация интерфейсов, характеристика интерфейсовАрхитектура ПКSIMDIP")
Слайд 46
Пропускная способность канала - Наибольшая возможная в данном канале скорость передачи
информации называется его пропускной способностью. Пропускная способность канала есть скорость передачи информации при использовании «наилучших» (оптимальных) для данного канала источника, кодера и декодера, поэтому она характеризует только канал.
Пропускная способность дискретного (цифрового) канала без помех C = log(m) бит/символ где m — основание кода сигнала, используемого в канале.
Скорость передачи информации в дискретном канале без шумов (идеальном канале) равна его пропускной способности, когда символы в канале независимы, а все m символов алфавита равновероятны (используются одинаково часто).
Пропускная способность дискретного (цифрового) канала без помех C = log(m) бит/символ где m — основание кода сигнала, используемого в канале.
Скорость передачи информации в дискретном канале без шумов (идеальном канале) равна его пропускной способности, когда символы в канале независимы, а все m символов алфавита равновероятны (используются одинаково часто).






