- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Актуальные вопросы компьютерной лингвистики презентация
Содержание
- 1. Актуальные вопросы компьютерной лингвистики
- 2. Введение История Обзор существующих систем с разным
- 3. Цель исследований по генерации текстов на ЕЯ:
- 4. История Самой популярной теорией генерации становится
- 5. К середине 90ых годов новое направление
- 6. Special Interest Group on GENeration (SIGGEN)
- 7. Отечественная традиция Во второй половине 70ых годов
- 8. основная проблематика синтеза –
- 9. Отечественные разработки 80-90х А.Б.Сосинский - штамповая грамматика
- 10. Принципы организации систем 1. Шаблонные системы система
- 11. Пример 1. система Employee Appraiser (производитель –
- 12. Performance Now (производитель – фирма KnowledgePoint) поддерживает
- 13. Пример генерации текста в 09 Шаблоны: Как___
- 14. Генерация реплик в диалоговых системах диалоговая система
- 15. «Идеальный» генератор Основные компоненты системы: Система
- 16. Лингвистические уровни преобразоваия: концептуальный уровень, семантический
- 17. Основные этапы Планирование содержания текста или Макропланирование.
- 18. Действующие прикладные системы В всегда четко задан
- 19. Типы входных данных для систем генерации ЕЯ
- 20. Генерация из входных данных типа «поток данных»
- 21. Генерация из входных данных типа «поток
- 22. Генерация из входных данных типа «поток
- 23. PostGraphe (1996) – синтезирует текстовые отчеты
- 24. Gossip (1988) – синтезирует на английском языке
- 25. Генерация из входных данных типа «информация об
- 26. Генерация из входных данных типа «информация об
- 27. Структура БЗ системы Text
- 28. Caption Generation System (1998) – порождает графики
- 29. M-PIRO (2001-2003) – многоязыковая система генерации, синтезирующая
- 30. система генерации на корейском языке XEplainer (2001),
- 31. Генерация из входных данных типа «формальная спецификация»
- 32. Генерация из входных данных типа «семантическое представление
- 33. SUREGEN-2 (2002) – генерирует на немецком языке
- 34. Организация лингвистически мотивированных систем генерации
- 35. Общая схема процесса генерации ([Bateman & Zock 2001])
- 36. Архитектура системы генерации Конвейер генерации традиционно разделяют
- 37. Архитектура системы генерации Входами генератора могут быть
- 38. Промежуточные представления данных: Объектная структура содержания текста
- 39. Макропланирование Основная цель этапа макропланирования –
- 40. Макропланирование 2. коммуникативная цель текста и запрос
- 41. 3. Модель предметной области (МПО) определяет типы
- 42. Макропланирование 4. дискурсивная стратегия – элемент культуры
- 43. Макропланирование Многие приложения для определения содержания генерируемого
- 44. Определение содержания сообщения как элементы плана текста
- 45. процесс обобщения сырых данных, приведения их к
- 46. Рис.3. Сообщение, записанное в виде матрицы
- 47. Концептуальное представление состоит из объектов и отношений
- 48. Риторическое представление Принципы риторического моделирования структуры
- 49. План текста: планирующие операторы, [Hovy 1993] и [Paris 1993] предикативные схемы
- 50. Теория планирующих операторов [Sacerdoti 1977]: Планировщик
- 51. Предикативные схемы Каждая схема – это
- 52. К. Маккьюин система TEXT [McKeown 1985]. входные
- 53. упрощенный пример описания, построенного по схеме “состав”
- 54. Тема-рематическая организация сообщений правила установления фокуса внимания
- 55. Переместить фокус на объект, упомянутый в предшествующем
- 56. Микропланирование Семантическое представление
- 57. Семантическое представление плана предложения язык SPL (Sentence
- 58. (s0 / study :actor
- 59. Задачи микропланирования агрегация сообщений до структур, соответствующих
- 60. Большую помощь в выборе лексико-грамматических соответствий
- 62. Этап языкового оформления три теоретические базы:

Слайд 2Введение
История
Обзор существующих систем с разным типом входных данных:
поток данных
Информация об объектах
Формальные спецификации
Семантическое представление

Слайд 3Цель исследований по генерации текстов на ЕЯ:
создание интеллектуальных компьютерных систем,
На входе: например, таблицы баз данных (БД), формальные спецификации программ, метеорологические карты.
На выходе: типовые документы, такие как отчеты, разъяснения и справочная информация.

Слайд 4История
Самой популярной теорией генерации становится
системно-функциональная грамматика
(Systemic Functional grammar -
(лингвистическая основа первой системы искусственного интеллекта с развитым лингвистическим компонентом - робот Т. Винограда)
в конце 80ых – генератор английского языка PENMAN
в конце 90ых годов - универсальная среда KPML (http://purl.org/net/kpml)
 M.A.K. Хэллидэя (лингвистическая")
Слайд 5К середине 90ых годов
новое направление
– многоязыковая генерация (МЯГ),
(Канада,
сплав двух направлений – МП на основе языка-посредника и генерации ЕЯ
система FoG (Канада в начале 90ых годов) - предназначена для генерации морских сводок погоды на французском и английском языках на основе метеорологических данных.
, (Канада, Великобритания, Германия)сплав двух направлений")
Слайд 6Special Interest Group on GENeration (SIGGEN)
http://www.cs.columbia.edu/~acl/.
каталог выполненных проектов по
 http://www.cs.columbia.edu/~acl/. каталог выполненных проектов по созданию систем ГЕЯ (“The")
Слайд 7Отечественная традиция
Во второй половине 70ых годов проводятся пионерские исследования Ю.С.Мартемьянова по
Э.В.Попова « Общение с ЭВМ на естественном языке» (Москва, 1987 г.)


Слайд 9Отечественные разработки 80-90х
А.Б.Сосинский - штамповая грамматика в предметной области (ПО) математических
система синтеза описания трехмерной сцены (уличные сцены с 30 объектами),
работы по генерации формулы изобретения
С.Шаров, Е.Г.Соколова - многоязыковой генератор AGILE (русская часть)
Болдасов, Е.Г.Соколова – генерация запросов к БД
 математических статейсистема синтеза описания трехмерной")
Слайд 10Принципы организации систем
1. Шаблонные системы
система хранит уже готовую строку, шаблон, возможно
Например, система, выдающая сообщение о невозможности найти тот или иной файл, может использовать строку «Не могу найти » « файл(ы)!».
Более сложные шаблонные системы дополнительно проводят ограниченную лингвистическую обработку генерируемого текста

Слайд 11Пример 1. система Employee Appraiser (производитель – фирма Austin-Haynes)
система, помогающая
набор оценочных тем, таких как, Общение,
более специфичные подтемы, например, Устный обмен идеями
Множество готовых абзацев или предложений, соответствующих этим темам и подтемам
Параметры, уточняемые пользователем, например, пол сотрудника, лицо (Например, текст во втором лице (вы) адресован самому сотруднику, текст в третьем лице (он / она) – администрации)
 система, помогающая менеджерам составлять деловые характеристики")
Слайд 12Performance Now (производитель – фирма KnowledgePoint)
поддерживает генерацию только в третьем лице,
Bert does not display the verbal communication skills required, and his written communications fall short of the quality needed. Additionally, he does not exhibit the listening and comprehension skills necessary for satisfactory performance of his job.
Текст составлен из 3-х фраз, полученных из библиотеки, вставлены подчеркнутые слова. В тексте характеристике фразы упорядочиваются по степени их «негативности»
поддерживает генерацию только в третьем лице, зато осуществляет простейшее планирование")
Слайд 13Пример генерации текста в 09
Шаблоны:
Как___ Х?
У нас два Z: X и
Х находится на У и т.п.
Состояние, вызывающее обращение к определенному шаблону:
Фрейм запроса:
Результат: На какой улице находится булочная?

Слайд 14Генерация реплик в диалоговых системах
диалоговая система ELIZA (1966 г.).
Типы реплик:
штамп,
штамп - реакцией на семантику слова из реплики пользователя, например, “Расскажите мне о своей семье” (как реакция на слово “мать”),
моделируется из опознанного системой лексико-синтаксического шаблона реплики пользователя (замена в нем некоторых элементов:
например, шаблон “X he Y me” (“Because he hates me.”) ⇒ две синтаксических реакции: “Why do you think he hates you?”; “Supose he did hate you?” )
. Типы реплик:штамп, - продолжение диалога, например,")
Слайд 15«Идеальный» генератор
Основные компоненты системы:
Система знаний
Коммуникативная цель
Модель адресата
Контекст повествования
")
Слайд 16Лингвистические уровни преобразоваия:
концептуальный уровень,
семантический уровень,
риторический уровень,
синтаксический уровень
текстовый
")
Слайд 17Основные этапы
Планирование содержания текста или Макропланирование.
Планирование предложений или Микропланирование.
Языковое
План текста (ср. дерево сообщений, например, A-box в системе AGILE;
Ср. исследования Чейфа «Память и вербализация прошлого опыта». Новое в зарубежной лингвистике вып. XII.
Построенные грамматические струткуры с накопленными в них морфологическими признаками преобразуются в ЕЯ предложения, а затем в текст
уточняется структура отдельных предложений текста, строятся семантические планы предложений, например, представления SPL в системе AGILE;

Слайд 18Действующие прикладные системы
В всегда четко задан тип входных данных и тип
Во входных данных определяющую роль играет система знаний.
Часто другие составляющие жестко зашиты в системе
Например, в системе TEXT выбирается тип текста (коммуникативная цель), в системе AGILE выбирается стиль текста, учитывающий как компетенцию адресата, так и его социальный статус (модель адресата).

Слайд 19Типы входных данных для систем генерации ЕЯ
Поток данных,
Информация об объектах
Формальные спецификации;
Семантическое представление.

Слайд 20Генерация из входных данных типа «поток данных»
«поток данных» - физические
например, метеорологические (погода), социологические (занятость населения), финансовые (биржевые сводки) и др.
констатируется наличие определенных объектов, отношений, значений атрибутов.
Эта информация не организована для передачи адресату в ходе ЕЯ коммуникации.
поток данных ➔ синтез текстов отчетов, описывающих состояние объектов или состояние дел.

Слайд 21Генерация из входных данных типа
«поток данных». Примеры систем
FoG (1989-2000)
(Bateman, J. A. Anabling technology for multilingual natural language generation: the KPML environment. In: Natural Language Engineering, 1997, 1(1). Goldberg, E., Driedgar, N., and Kittredge, R. Using natural-language processing to produce weather forecasts. IEEE Expert, 1994, 9(2): 45-53.)
Система синтезирует метеорологические сводки о состоянии погоды для кораблей на основании таблицы замеров погодных параметров (направление и сила ветра, температура и др.) на английском и французском языках
В настоящее время система FoG успешно применяется в службе Гидрометцентра Канады и позволяет экономить этой службе значительные затраты на составление описаний сводок погоды на двух государственных языках – английском и французском
 – (Bateman, J. A. Anabling")
Слайд 22Генерация из входных данных типа
«поток данных». Примеры систем
ANA (1983) –
синтезирует на английском языке отчеты о состоянии биржи (объем продаж, состояние на момент закрытия биржи, изменение индекса Доу Джонса и т.д.) на основании таблицы данных фондовой биржи за день.
 – синтезирует на английском языке")
Слайд 23PostGraphe (1996) –
синтезирует текстовые отчеты и графики динамики прибыли компаний
De 1987 à 1989 les profits de la compagnie A ont augmenté de 30$ á 40$. Jusqu’en 1990 ils ont diminué de 40$ á 35$.
De 1987 à 1988 les profits de B ont augmenté de 160$ á 165$. Pendant 1 année ils ont diminué de 25$. Jusqu’en 1990 ils ont augmenté de 140$ á 155$.
Генерация из входных данных типа
«поток данных». Примеры систем
 – синтезирует текстовые отчеты и графики динамики прибыли компаний по статистической табличной информации")
Слайд 24Gossip (1988)
– синтезирует на английском языке отчеты об использовании машинного времени
Пример текста, порожденного системой Gossip:
The system was used for 7 hours 32 minutes 12 seconds. The users of the system ran compilers and editors during this time. The compilers were run six times, for 47% of the cpu time. The editors were run twelve times, for 53% of the cpu time. Two users, Jessie and Martin, logged on to the system. Jessie used the system for 63% of the time in use. Martin used the system for 40% of the time in use.
Генерация из входных данных типа «поток данных». Примеры систем
– синтезирует на английском языке отчеты об использовании машинного времени пользователями на основании таблицы")
Слайд 25Генерация из входных данных типа «информация об объектах и явлениях»
Как и
Эта информация также не организована для передачи адресату в ходе ЕЯ коммуникации.
Однако, она имеет более структурированный вид.
Данные этого типа обычно представляется реляционными отношениями БД или объектными структурами.

Слайд 26Генерация из входных данных типа «информация об объектах и явлениях». Примеры
TEXT [30] (1980-1985)
(McKeown [K Маккьюин К. (1989) Дискурсивные стратегии для синтеза текста на естественном языке // НЗЛ. Вып. XXIV. M, 1989. C. 311-356. ])
синтезирует ответы на вопросы пользователей о структуре базы данных по морским транспортным средствам и средствам разрушения. В качестве ответа системой выдается небольшой текст на английском языке. В зависимости от типа вопроса пользователя системой генерируются тексты типа определение, описание или сравнение.
(McKeown [K")

Слайд 28Caption Generation System (1998) – порождает графики и их ЕЯ описания
These charts show information about house sales from data set PGH-23. In the two charts, the X-axis shows the selling prices. The top chart emphasizes the relationship between the number of rooms and the selling price. The bottom chart emphasizes the relationship between the lot size and the selling price.
Генерация из входных данных типа «информация об объектах и явлениях». Примеры систем
 – порождает графики и их ЕЯ описания на английском языке. Пример")
Слайд 29M-PIRO (2001-2003) – многоязыковая система генерации, синтезирующая описание музейных экспонатов на
Artequakt (2002) – система генерации биографий художников на основе табличных данных их биографии. Тексты биографий генерируются на английском языке.
Demosthenes (2002) - система генерации описаний товаров, как в рекламных целях, так и для справки. Эта система синтезирует на немецком языке описания винных сортов винограда и получаемых из них вин.
Эти системы предназначены для обслуживания посетителей, поэтому они включают генератор звучащей речи.
Генерация из входных данных типа «информация об объектах и явлениях». Примеры систем
 – многоязыковая система генерации, синтезирующая описание музейных экспонатов на английском, греческом, итальянском и")
Слайд 30система генерации на корейском языке XEplainer (2001), обслуживающую web-магазины
На основе информации
Генерация из входных данных типа «информация об объектах и явлениях». Примеры систем
, обслуживающую web-магазиныНа основе информации о товарах, размещенной на")
Слайд 31Генерация из входных данных типа «формальная спецификация»
Integrated Software and On-Line
среда, позволяющая объединить и ускорить процессы разработки программного продукта и его документации.
(http://www.cmis.csiro.au/iit/Projects/Isolde/index.htm).
ModelExplainer (1997) – генерирует текстовые описания диаграмм объектно-ориентированного моделирования данных, полученных из программных средств RationalRose и Visio (http://www.cogentex.com/research/modex/index.shtml).
Система умеет строить иерехические HTML-справочники, отдельные страницы которых связаны контекстными ссылками.
Proverb (1996-2000) – строит на английском языке тексты доказательств математических утверждений, автоматически построенных системой OMEGA (интерактивная среда построения доказательств).
 (1992-2002)")
Слайд 32Генерация из входных данных типа «семантическое представление
AGILE [26] (2000) –
(реализованы болгарский, чешский и русский языки)
Создание полилинии из прямых и дуг
Запустите команду PLINE.
Windows Выберите пункт Poliline в палитре Poliline на панели инструментов Draw.
DOS/Unix Выберите пункт Poliline в меню Draw.
1. Нарисуйте отрезок.
Укажите начальную точку отрезка и укажите конечную точку отрезка.
2. Нарисуйте дугу.
Перейдите в режим Arc.
Введите команду a. На экране появится диалоговое окно Arc mode confirmation. Нажмите кнопку ОК в диалоговом окне Arc mode confirmation. Диалоговое окно Arc mode confirmation исчезнет с экрана.
 – макет, генерация софтверных руководств")
Слайд 33SUREGEN-2 (2002) – генерирует на немецком языке медицинскую документацию, такую как
MDA (Multilingual Document Authoring) (2000)
 – генерирует на немецком языке медицинскую документацию, такую как заключения, отчеты о ходе")

")
Слайд 36Архитектура системы генерации
Конвейер генерации традиционно разделяют на три этапа: Макропланирование –
Микропланирование – построение планов предложений и
Языковое оформление – реализация построенных планов предложений соответствующими грамматическими структурами. В прикладных системах генерации к этим трем этапам часто добавляется четвертый этап,
Физическое представление, на котором производится форматирование текста согласно выбранному формату (PDF, HTML и т.д.) или подключается генератор устной речи.

Слайд 37Архитектура системы генерации
Входами генератора могут быть как рассыпанные представления типа баз
В случае БД выбираются объекты и атрибуты БД, которые войдут в содержание текста. Во втором случае все объекты уже выбраны и даже выражены в виде семантических сущностей и структурированы, т.е. задача структурирования содержания уже решена.
Но задача выбора содержания связана, в частности, с ориентацией на адресата и остается возможность опущения определенных фрагментов плана текста.
, так и")
Слайд 38Промежуточные представления данных:
Объектная структура содержания текста - концептуальная структура содержания текста,
Структура текста – структура дискурсивных отношений, организующая сообщения в текст (в частности, риторическая структура);
Сообщения - элементарные предикативные фреймы с объектами и отношениями ПО,
Семантические представления предложений текста (в частности, SPL);
Лексикализованные грамматические конструкции предложений текста

Слайд 39Макропланирование
Основная цель этапа макропланирования –
сформировать план текста.
Составляющие:
1. Входные данные.
Содержание процессов макропланирования зависит от типа входных данных. Если они представлены в виде сырых данных, БД или БЗ или иного вида организованных знаний, например, онтология, то они являются материалом для создания плана текста, из которого строятся объекты и значения свойств, о которых будет идти речь в тексте.

Слайд 40Макропланирование
2. коммуникативная цель текста и запрос автора
– эти составляющие определяют
Коммуникативная цель (сравнить, описать, определить, объяснить, и др…) определяет тип текста – описание (в том числе в форме сравнения), определение, объяснение, и др., а запрос автора фиксирует объект или группу объектов, которые становятся темой текста.
В системах ГЕЯ тема и тип текста (в том случае, если система может порождать несколько типов текстов) задаются пользователем.

Слайд 413. Модель предметной области (МПО) определяет типы объектов ПО, а также
Макропланирование
 определяет типы объектов ПО, а также те предметные отношения и")
Слайд 42Макропланирование
4. дискурсивная стратегия – элемент культуры говорящего сообщества. Она определяет конкретную

Слайд 43Макропланирование
Многие приложения для определения содержания генерируемого текста используют также модель читателя,

Слайд 44Определение содержания сообщения как элементы плана текста
На этом этапе создаются сообщения.

Слайд 45процесс обобщения сырых данных, приведения их к понятиям ПО и к

Слайд 46
Рис.3. Сообщение, записанное в виде матрицы «атрибут-значение», как элемент плана-текста, например,
В сообщении на рис.3 использовано отношение Время отправления поезда, связывающее концепты Поезд Экспресс-Каледония, Абердин и 10 часов утра.

Слайд 47Концептуальное представление
состоит из объектов и отношений ПО. Оно строится двумя способами:
 заполнением объектной МПО")
Слайд 48Риторическое представление
Принципы риторического моделирования структуры текста сформулированы в Теории риторических
Риторическое представление - это дерево составляющих текста, терминальные вершины которого сообщения.
Терминальные вершины соединяются во все более крупные фрагменты до получения структуры всего текста. Внутренние вершины риторического представления описывают, как сообщения сгруппированы вместе и связаны друг с другом риторическими отношениями, например, причина, цель, последовательность, уточнение, побуждение, разрешение и т.д.
Всего в классическом варианте ТРС определено 45 отношений. Каждая внутренняя вершина разделяет свое содержимое как минимум на две части: главную (nucleus) и второстепенную (satellite)
Группирование текстовых фрагментов риторическими отношениями накладывает ограничения на будущее разделение порождаемого текста на абзацы и на предложения.


Слайд 50Теория планирующих операторов [Sacerdoti 1977]:
Планировщик получает на входе цель (проблема,
,")
Слайд 51Предикативные схемы
Каждая схема – это шаблон, который определяет, как должен
Исходное предположение: каждой своей отдельно взятой коммуникативной цели люди пытаются сопоставить все время один и тот же вид информации в одном и том же порядке
В качестве базового набора берутся риторические предикаты Граймса и Уильямса (такие, как атрибутив, аналогия, состав, сравнение, тема, вывод, идентификация, переименование и др.)

Слайд 52К. Маккьюин система TEXT [McKeown 1985].
входные данные в системе TEXT:
база
ЕЯ запрос пользователя, который определял одну из трех коммуникативных целей: Определить, Описать или Сравнить,
фрагмент релевантных знаний БЗ, необходимый для составления ответа.
схемами представлены пять различных предикативных моделей: идентификации, состава, атрибутивности, сравнения и противопоставления (реализованы с использованием формализма, основанного на расширенной сети переходов (ATN) [Woods 1970])

Слайд 53упрощенный пример описания, построенного по схеме “состав” (Макьюин, 1989)
“Паровые и электрические
“Паровые и электрические торпеды. [состав: ] Современные")
Слайд 54Тема-рематическая организация сообщений
правила установления фокуса внимания на определнном объекте. Фокус внимания
в системе TEXT использовались адаптированные правила Синдера [Sinder 1979]

Слайд 55Переместить фокус на объект, упомянутый в предшествующем высказывании
Сохранить фокус
Вернуться к теме
Выбрать высказывание, имеющее наибольшее число имплицитных связей с предшествующим высказыванием.
Правила Синдера, упорядоченные по предпочтительности их использования для управления перемещением фокуса:


Слайд 57Семантическое представление плана предложения
язык SPL (Sentence Plan Language) [Kasper 1989]
Представление
- семантические элементы, каждый из которых сопоставляется с одним или несколькими семантическими типами
- каждый семантический элемент имеет набор атрибутов или ролей (например, :actee, :spatial-locating, и т.д.)
- каждая роль из этого набора сопоставляется с другим семантическим элементом или набором элементов
 [Kasper 1989] Представление SPL: - семантические элементы,")
Слайд 58(s0 / study
:actor (Anni-Albers / female)
:actee (x1 / art)
:temporal-locating (x2 / three-d-time :year 1916-1919))
Рис. 1: Пример представления SPL. Представление в примере определяет фразу
“В 1916-1919 Анни Алберс изучала искусство у Мартина Бранденбурга”
 :accompaniment (Martin-Brandenburg / male) :actee")
Слайд 59Задачи микропланирования
агрегация сообщений до структур, соответствующих отдельным предложениям создаваемого текста
лексикализация концептов
вставка ссылочных конструкций – для обеспечения лучшей слитности текста при многократном упоминании объектов в высказываниях для их идентификации нужно выбирать различные слова или словосочетания (интродукции, местоимения и дефинитные описания)

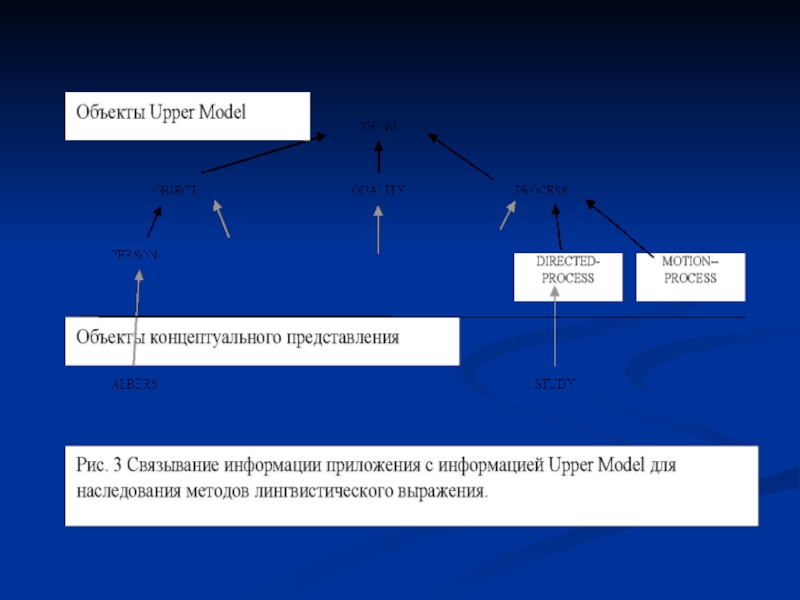
Слайд 60 Большую помощь в выборе лексико-грамматических соответствий понятиям предметной области (концептам
Upper Model (UM) – это иерархия классов концептов МПО и типичных отношений между ними с учетом их возможной лингвистической реализации.
Сегодня источник знаний Upper Model используется в основном в системах генерации, построенных на платформе KPML.
Самая большая иерархия Upper Model, включает в себя около 150 понятий. Классификация понятий МПО в терминах Upper Model позволяет объектам предметной области наследовать возможности своей лингвистической реализации.
")
Слайд 62Этап языкового оформления
три теоретические базы:
системно-функциональной грамматика (SFG: [Halliday 1994], реализована
tree-adjoining grammars (TAG: [Danlos 2000], реализована в системе TagGen)
Модель СМЫСЛ-ТЕКСТ (MTM: [Mel’cuk 1988], реализована в системе RealPro [Lavoie and Rambow 1997]).






