- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Задача кластеризации. Алгоритмы кластеризации презентация
Содержание
- 1. Задача кластеризации. Алгоритмы кластеризации
- 2. Кластеризация — группировка объектов по похожести их
- 3. Цели кластеризации в Data Mining могут быть
- 4. Алгоритмы кластеризации К-средних (K-means) Нейронная сеть Кохонена
- 5. Алгоритм кластеризации k-means От англ. mean
- 6. Например, если в кластер вошли три записи
- 7. Шаги 3 и 4 повторяются до тех
- 8. Меры расстояний Ключевой момент алгоритма k-means: на
- 9. □ Расстояние Манхэттена (Manhattan distance), или метрика
- 10. Пример работы алгоритма k-means Пусть имеется
- 11. Шаг 1. Определим число кластеров, на которое
- 13. Таким образом, кластер 1 содержит точки А,
- 14. На рис. начальные центры кластеров представлены светлыми
- 15. Шаг 3, проход 2. После того как
- 16. Таким образом, кластер 1 будет содержать точки
- 17. Шаг 4, проход 2. Для каждого кластера
- 18. По сравнению с предыдущим проходом центры кластеров
- 19. Следует отметить, что записей, сменивших кластер на
- 20. Таким образом, сумма квадратов ошибок изменилась незначительно
- 21. Сети Кохонена Термин «сети Кохонена» был введен
- 22. Объекты имеют 3 признака (на самом деле
- 23. Взглянув на рисунок, можно увидеть, как расположены
- 25. Берем один объект (точку в этом пространстве)
- 27. В основе построения сети Кохонена лежит конкурентное
- 28. Входные нейроны образуют входной слой сети, который
- 29. Однако в отличие от большинства нейронных сетей
- 30. В процессе обучения и функционирования сеть KCN
- 31. 3. Подстройка весов. Нейроны, соседние с нейроном-победителем,
- 32. Обучение сети Кохонена Сети Кохонена — это
- 33. Алгоритм Кохонена включает шаги: Инициализация. Для нейронов
- 34. Иными словами, рассчитывается расстояние между векторами весов
- 36. Пример работы сети Кохонена Имеется множество данных;
- 38. Для первого входного вектора X1 = (0,8;
- 39. Таким образом, для первой записи победителем стал
- 40. Тогда для признака Возраст: Тогда для признака
- 41. Произведем аналогичные действия для второго входного вектора Х2 = (0,8; 0,1). Конкуренция.
- 42. Таким образом, для второй записи победителем стал
- 43. Как можно увидеть, веса вновь корректируются в
- 44. Теперь выполним ту же последовательность действий для
- 45. Теперь победителем стал нейрон 3, поскольку вектор
- 46. И наконец выполним ту же последовательность действий
- 47. Теперь победителем стал нейрон 4, поскольку вектор
- 48. Таким образом, можно увидеть, что четыре выходных
- 50. Карты Кохонена Самоорганизующиеся карты признаков не
- 51. В большинстве практических приложений приходится иметь дело
- 52. Методика построения карты Чем отличаются понятия «сеть
- 53. Карта Кохонена состоит из сегментов прямоугольной или
- 54. Хотя расстояние между объектами позволяет сделать выводы
- 55. В зависимости от значения признака определяется цвет
- 56. Ячейки бывают прямоугольной и шестиугольной формы.

Слайд 2Кластеризация — группировка объектов по похожести их свойств; каждый кластер состоит

Слайд 3Цели кластеризации в Data Mining могут быть различными и зависят от
Изучение данных. Разбиение множества объектов на схожие группы помогает выявить структуру данных, увеличить наглядность их представления, выдвинуть новые гипотезы, понять, насколько информативны свойства объектов.
Облегчение анализа. При помощи кластеризации можно упростить дальнейшую обработку данных и построение моделей: каждый кластер обрабатывается индивидуально и модель создается для каждого кластера в отдельности. В этом смысле кластеризация является подготовительным этапом перед решением других задач Data Mining: классификации, регрессии, ассоциации, последовательных шаблонов.

Слайд 4Алгоритмы кластеризации
К-средних (K-means)
Нейронная сеть Кохонена
Графовые алгоритмы кластеризации
Статистические алгоритмы кластеризации
Алгоритмы
Иерархическая кластеризация или таксономия
Ансамбль кластеризаторов
Алгоритмы семейства КRAB
EM-алгоритм
Алгоритм, основанный на методе просеивания
Метод опорных векторов
Нейронная сеть КохоненаГрафовые алгоритмы кластеризации Статистические алгоритмы кластеризации Алгоритмы семейства FOREL Иерархическая кластеризация")
Слайд 5Алгоритм кластеризации k-means
От англ. mean — «среднее значение». Он состоит
Задается число кластеров k, которое должно быть сформировано из объектов исходной выборки.
Случайным образом выбирается k записей исходной выборки, которые будут служить начальными центрами кластеров. Начальные точки, из которых потом вырастает кластер, часто называют «семенами». Каждая такая запись представляет собой своего рода «эмбрион» кластера, состоящий только из одного элемента.
Для каждой записи исходной выборки определяется ближайший к ней центр кластера.
Производится вычисление центроидов — центров тяжести кластеров.

Слайд 6Например, если в кластер вошли три записи с наборами признаков (х1,
Затем старый центр кластера смещается в его центроид. На рис. 2 центры тяжести кластеров представлены в виде крестиков.
Таким образом, центроиды становятся новыми центрами кластеров для следующей итерации алгоритма.
, (х2,у2), (х3, у3),")
Слайд 7Шаги 3 и 4 повторяются до тех пор, пока выполнение алгоритма
Остановка алгоритма производится, когда границы кластеров и расположение центроидов перестают изменяться от итерации к итерации, то есть на каждой итерации в каждом кластере остается один и тот же набор записей.
Что касается критерия сходимости, то чаще всего используется сумма квадратов ошибок между центроидом кластера и всеми вошедшими в него записями:
где р — произвольная точка данных, принадлежащая кластеру Сi; mi; — центроид данного кластера.
Иными словами, алгоритм остановится тогда, когда ошибка E достигнет достаточно малого значения.

Слайд 8Меры расстояний
Ключевой момент алгоритма k-means: на каждой итерации вычисляется расстояние между
□ Евклидово расстояние , или метрика L2. Использует для вычисления расстояний следующее правило:

Слайд 9□ Расстояние Манхэттена (Manhattan distance), или метрика L1 вычисляется по формуле
□ Для категориальных признаков в качестве меры расстояния можно использовать функцию отличия (different function), которая задается следующим образом:
где xi и y i — категориальные значения.
, или метрика L1 вычисляется по формуле □ Для категориальных признаков")
Слайд 10
Пример работы алгоритма k-means
Пусть имеется набор из 8 точек данных в

Слайд 11Шаг 1. Определим число кластеров, на которое требуется разбить исходное множество:
Шаг 2. Случайным образом выберем две точки, которые будут начальными центрами кластеров. Пусть это будут точки m1 = (1; 1) и m2 = (2; 1). На рис. 3 они представлены ромбами.
Шаг З, проход 1. Для каждой точки определим ближайший к ней центр кластера с помощью евклидова расстояния. В табл. 2 представлены вычисленные с помощью формулы (7.1) расстояния между центрами кластеров m1 = (1; 1) и m2 = (2; 1) и каждой точкой исходного множества и указано, к какому кластеру принадлежит та или иная точка.

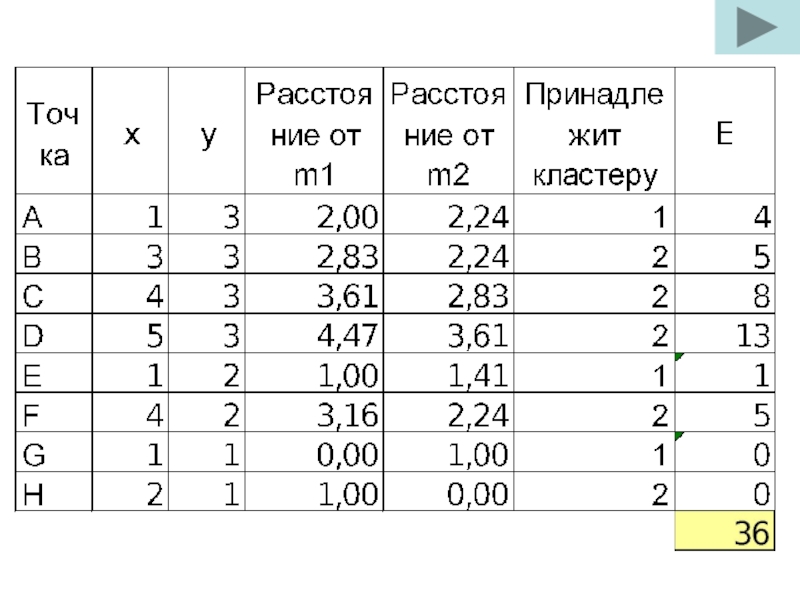
Слайд 13Таким образом, кластер 1 содержит точки А, Е, G, а кластер
Шаг 4, проход 1. Для каждого кластера вычисляется центроид, и в него перемещается центр кластера.
Центроид для кластера 1: [(1 + 1 + 1)/3; (3 + 2 + 1)/3] = (1; 2).
Центроид для кластера 2: [(3 + 4 + 5 + 4 + 2)/5; (3 + 3 + 3 + 2 + 1)/5] = (3,6; 2,4).
Расположение кластеров и центроидов после первого прохода алгоритма представлено на рис. 3

Слайд 14На рис. начальные центры кластеров представлены светлыми ромбами, а центроиды, вычисленные

Слайд 15Шаг 3, проход 2. После того как найдены новые центры кластеров,

Слайд 16Таким образом, кластер 1 будет содержать точки А, Е, G, Н,
Вычисление показывает уменьшение ошибки относительно начального состояния центров кластеров (на первом проходе она составляла 36). Это говорит об улучшении качества кластеризации, то есть о более высокой «кучности» объектов относительно центра кластера.

Слайд 17Шаг 4, проход 2. Для каждого кластера вновь вычисляется центроид, и
Новый центроид для кластера 1: [(1 + 1 + 1 + 2)/4, (3 + 2 + 1 +1)/4] = (1,25; 1,75).
Новый центроид для кластера 2: [(3 + 4 + 5 + 4)/4, (3 + 3 + 3 + 2)/4] = (4; 2,75).
Расположение кластеров и центроидов после второго прохода алгоритма представлено на рис. 4.

Слайд 18По сравнению с предыдущим проходом центры кластеров изменились незначительно.
Шаг 3, проход

Слайд 19Следует отметить, что записей, сменивших кластер на третьем проходе алгоритма, не

Слайд 20Таким образом, сумма квадратов ошибок изменилась незначительно по сравнению с предыдущим
Шаг 4, проход 3. Для каждого кластера вновь вычисляется центроид, и центр кластера перемещается в него. Но поскольку на данном проходе ни одна запись не изменила своего членства в кластерах и положение центроидов не поменялось, алгоритм завершает работу.
m1=(1,25;1,75)
m2=(4;2,75)

Слайд 21Сети Кохонена
Термин «сети Кохонена» был введен в 1982 г. финским ученым
Основная цель сетей Кохонена — преобразование сложных многомерных данных в более простую структуру малой размерности. Таким образом, они хорошо подходят для кластерного анализа, когда требуется обнаружить скрытые закономерности в больших массивах данных.
Сеть Кохонена состоит из узлов, которые объединяются в кластеры. Наиболее близкие узлы соответствуют похожим объектам, а удаленные друг от друга — непохожим.

Слайд 22Объекты имеют 3 признака (на самом деле их может быть любое
Теперь представим, что все эти три параметра объектов представляют собой их координаты в трехмерном пространстве. Тогда каждый объект можно представить в виде точки в этом пространстве, что мы и сделаем, в результате чего все точки попадут в куб единичного размера (рис.).
.Теперь представим, что все")
Слайд 23Взглянув на рисунок, можно увидеть, как расположены объекты в пространстве, причем

Слайд 25Берем один объект (точку в этом пространстве) и находим ближайший к
Теперь определяем, какие объекты у нас попали в какие узлы карты. Это также определяется ближайшим узлом – объект попадает в тот узел, который находится ближе к нему. В результате всех этих операций объекты со схожими параметрами попадут в один узел или в соседние узлы.
 и находим ближайший к нему узел сети. После")
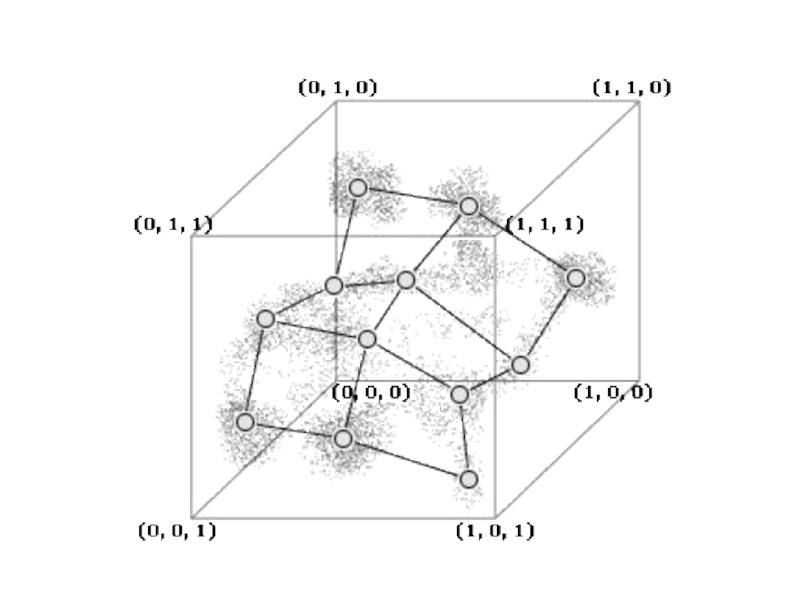
Слайд 27В основе построения сети Кохонена лежит конкурентное обучение, когда выходные узлы
 конкурируют между собой")
Слайд 28Входные нейроны образуют входной слой сети, который содержит по одному нейрону
Каждая связь между нейронами сети имеет определенный вес, который в процессе инициализации карты устанавливается для каждой связи случайным образом и значение которого лежит в интервале от 0 до 1. Процесс обучения заключается в подстройке весов.

Слайд 29Однако в отличие от большинства нейронных сетей других видов сеть Кохонена
Для записи значения каждого поля передаются через входные нейроны на каждый нейрон выходного слоя. Предположим, что нормированные значения возраста и дохода составляют 0,58 и 0,69 соответственно. Значение 0,58 поступает в сеть через входной нейрон Возраст и передается на все нейроны выходного слоя. Аналогично значение 0,69 поступает через нейрон Доход и также распространяется на все нейроны выходного слоя. Выходной нейрон, имеющий наилучший итог по некоторой скоринговой функции, объявляется нейроном-победителем.

Слайд 30В процессе обучения и функционирования сеть KCN выполняет три процедуры.
Конкуренция. Выходные
Объединение. Победивший нейрон становится центром некоторого соседства нейронов. Все нейроны такого соседства называют награжденными правом подстройки весов. Следовательно, несмотря на то что нейроны в выходном слое не соединяются непосредственно, они имеет тенденцию разделять общие свойства благодаря соседству с нейроном-победителем.

Слайд 313. Подстройка весов. Нейроны, соседние с нейроном-победителем, участвуют в подстройке весов,

Слайд 32Обучение сети Кохонена
Сети Кохонена — это нейросетевые структуры, в которых используется
где 0 < η < 1 — коэффициент скорости обучения.
(1)

Слайд 33Алгоритм Кохонена включает шаги:
Инициализация. Для нейронов сети устанавливаются начальные веса, а
η – скорость, с которой происходит обучение распределение весов.
R – линейное расстояние от любого нейрона до другого любого. В начале задается достаточно большим, затем 1 или меньше.
2. Возбуждение. На входной слой подается вектор воздействия Хn, содержащий значения входных полей некоторой записи обучающей выборки.
3. Конкуренция. Для каждого выходного нейрона вычисляется скоринговая функция D(Wj, Хn). Например, для евклидова расстояния она будет равна:

Слайд 34Иными словами, рассчитывается расстояние между векторами весов всех нейронов выходного слоя
4. Объединение. Определяются все нейроны, расположенные в пределах радиуса обучения относительно нейрона-победителя.
5. Подстройка. Производится подстройка весов нейронов в пределах радиуса обучения в соответствии с формулой (2). При этом веса нейронов, ближайших к нейрону-победителю, подстраиваются в сторону его вектора весов (рис.).
6. Коррекция. Изменяются радиус и параметр скорости обучения в соответствии с заданным законом.

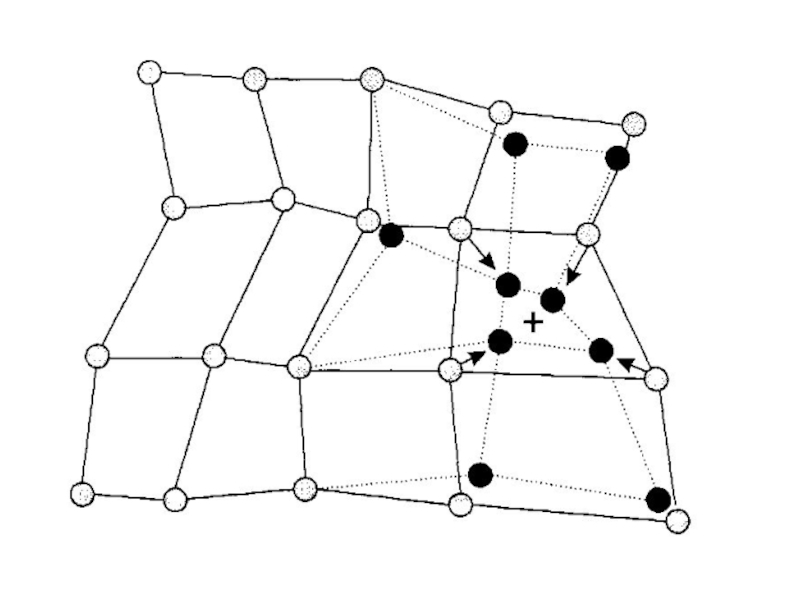
Слайд 36Пример работы сети Кохонена
Имеется множество данных; в нем содержатся атрибуты Возраст
Установим радиус обучения R = О, поэтому возможность подстройки весов будет предоставлена только нейрону-победителю. Коэффициент скорости обучения установим η = 0,5.
Выберем случайным образом начальные веса нейронов: w11 = 0,9; w21 = 0,8; w12 = 0,9; w22 = 0,2; w13 = 0,1; w23 = 0,8; w14 = 0,1; w24 = 0,2.
Набор записей исходной выборки


Слайд 38Для первого входного вектора X1 = (0,8; 0,8) выполним такие действия,
Конкуренция. Вычислим евклидово расстояние между входным вектором X1 и векторами весов всех четырех нейронов выходного слоя.
 выполним такие действия, как конкуренция, объединение и")
Слайд 39Таким образом, для первой записи победителем стал нейрон с номером 1,
Объединение. В данном примере установлен радиус обучения R = 0, поэтому уровень объединения между выходными нейронами также равен 0. Соответственно, только нейрон-победитель будет «награжден» возможностью подстройки своего вектора весов. В связи с этим мы не будем рассматривать этот этап в дальнейшем.
Подстройка. Поскольку для первого нейрона j = 1, для первой записи п = 1 при коэффициенте скорости обучения л = 0,5 в соответствии с правилом 1 получим:

Слайд 40Тогда для признака Возраст:
Тогда для признака Доход:
Веса «подталкиваются» в направлении значений

. Конкуренция.")
Слайд 42Таким образом, для второй записи победителем стал нейрон 2. Обратим внимание
Подстройка весов. Поскольку победил второй нейрон, то j = 2, и для второй записи n = 2 при коэффициенте скорости обучения η = 0,5 в соответствии с формулой 1 получим:

Слайд 43Как можно увидеть, веса вновь корректируются в направлении значений входных полей
Вес w22 для признака Возраст уменьшился, поскольку значение поля Доход для второй записи ниже, чем текущий вес связи Доход нейрона-победителя. Благодаря данной подстройке нейрон 2 сможет лучше «захватывать» записи, содержащие информацию о пожилых людях с низким доходом.
Тогда для признака Возраст:
Тогда для признака Доход:

Слайд 44Теперь выполним ту же последовательность действий для третьей записи, где входной
Конкуренция.
.Конкуренция.")
Слайд 45Теперь победителем стал нейрон 3, поскольку вектор его весов W3 =
Подстройка весов. Поскольку победил третий нейрон, то j = 3, и для третьей записи n = 3 при коэффициенте скорости обучения η = 0,5 в соответствии с формулой 1 получим:
 оказался ближе")
Слайд 46И наконец выполним ту же последовательность действий для входного вектора четвертой
Конкуренция.

Слайд 47Теперь победителем стал нейрон 4, поскольку вектор его весов W4 =
Подстройка весов. Поскольку победил четвертый нейрон, то j = 4, и для четвертой записи n = 4 в соответствии с формулой (2) получим:
 оказался ближе")
Слайд 48Таким образом, можно увидеть, что четыре выходных нейрона представляют четыре различных
Конечно, кластеры, открытые сетью Кохонена в данном примере, достаточно очевидны. Однако здесь хорошо проиллюстрированы основы работы KCN с использованием конкуренции между нейронами и алгоритма обучения Кохонена.

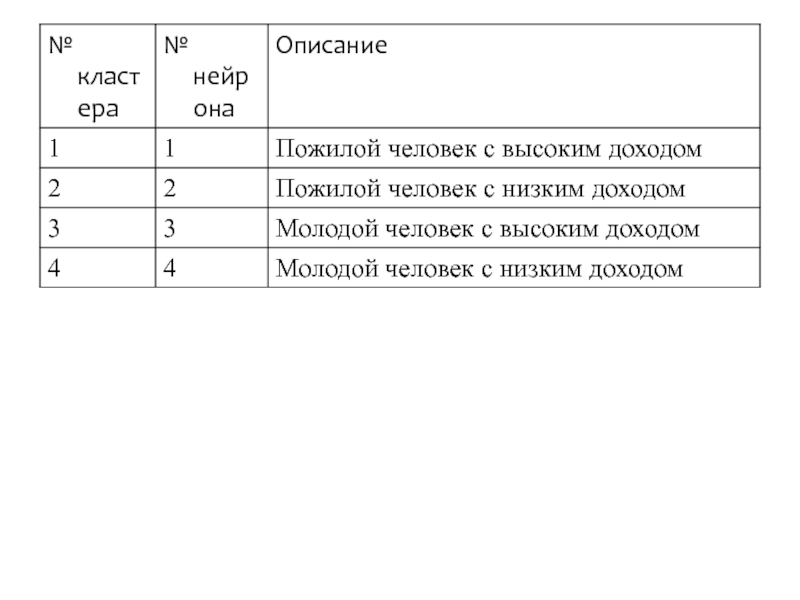
Слайд 50Карты Кохонена
Самоорганизующиеся карты признаков не только являются эффективным алгоритмом кластеризации,
Для отображение глубины выраженности признака используется специальная цветовая гамма: чем выше или глубже степень выраженности, тем более темным цветом он окрашивается. Таким образом, двумерная карта позволяет показывать три измерения.

Слайд 51В большинстве практических приложений приходится иметь дело с данными, для которых

Слайд 52Методика построения карты
Чем отличаются понятия «сеть Кохонена» и «карта Кохонена»?
в сети число выходных нейронов соответствует количеству кластеров, которое должно быть получено, а в карте — количеству сегментов, из которого будет состоять карта, или, иными словами, размеру карты.
Из вышесказанного можно сделать вывод, что карта Кохонена — это разновидность сети Кохонена.

Слайд 53Карта Кохонена состоит из сегментов прямоугольной или шестиугольной формы, называемых ячейками.
Объекты, векторы признаков которых оказываются ближе к вектору весов данного нейрона, попадают в ячейку, связанную с ним. Следовательно, если объекты на карте расположены близко друг к другу, то и векторы признаков этих объектов близки, и наоборот.

Слайд 54Хотя расстояние между объектами позволяет сделать выводы о степени их сходства
Таким образом, есть два важных фактора: положение объекта на карте (расстояние до других объектов) и цвет ячейки.
При данном способе визуализации на одной карте можно использовать расцветку только по одному признаку, то есть для значений нескольких признаков строятся отдельные карты.

Слайд 55В зависимости от значения признака определяется цвет для всех объектов в
Строятся две карты, и цвет ячейки определяется по среднему в них. Для признака Возраст он будет соответствовать (45 + 34)/2 = 39,5, то есть серому оттенку (в цветной палитре — зеленому), а для признака Доход — (21 + 14)/2 = 17,5, то есть белому оттенку (в цветной палитре — желто-зеленому). Заметим, что можно не усреднять значения признака, а брать минимальное или максимальное из них.