- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Зачем знать алгоритмы презентация
Содержание
- 1. Зачем знать алгоритмы
- 2. Who is Mr. Aksenov?
- 4. честно листал все!
- 5. не прочитал ни одной :(
- 7. делал веб-сайты и веб-движок
- 9. делал игры и 3D движок
- 12. делаю поисковой движок
- 13. free open source search
- 16. что могу рассказать?
- 17. как устроены всякие движки
- 19. на пальцах, не по книжке! (см. “не читатель”)
- 20. про движок СУБД (любой)
- 21. Система Управления Базой Данных
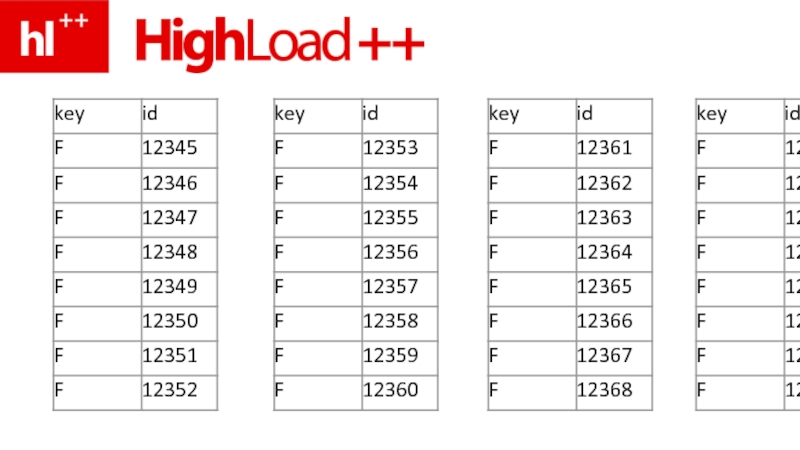
- 22. данные – это таблицы. из строк
- 24. строки – нужно где-то хранить
- 27. это, кстати, данные – без индексов
- 28. добавляем PK, и брюки превращаются…
- 31. почему так? разные стратегии хранения строк
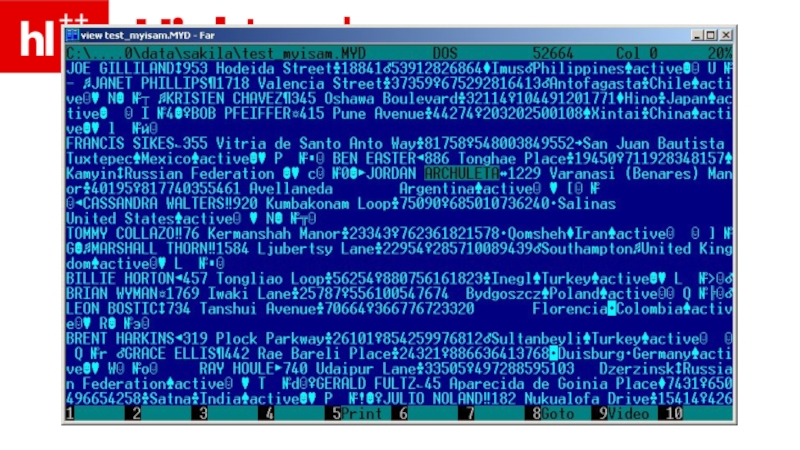
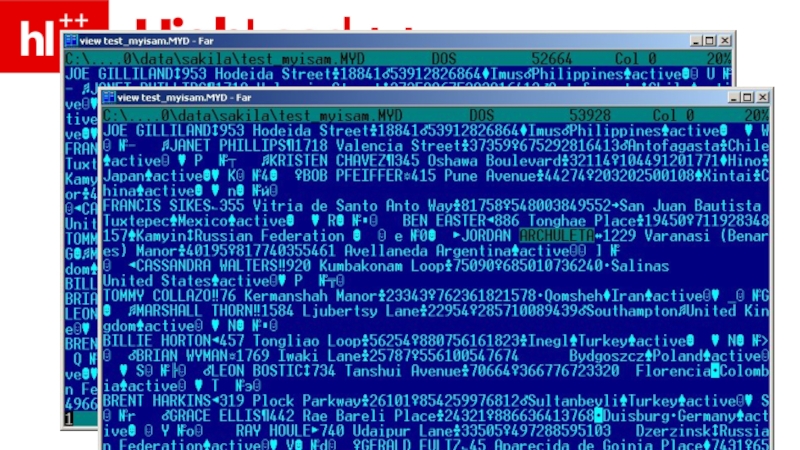
- 32. MyISAM – в порядке поступления (в конец файла)
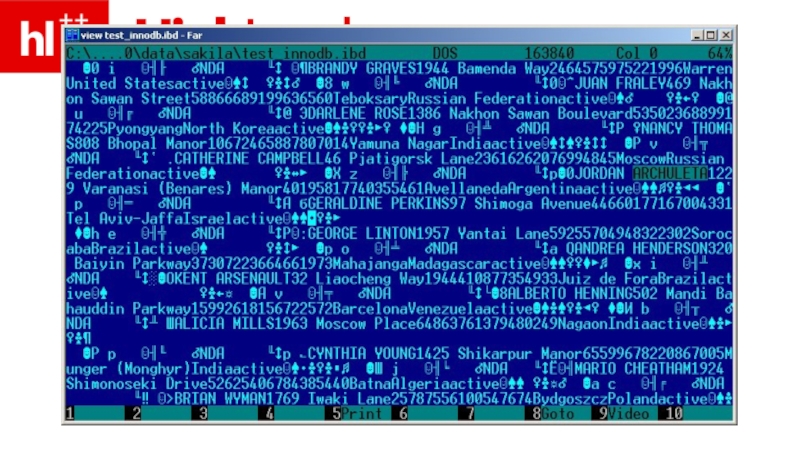
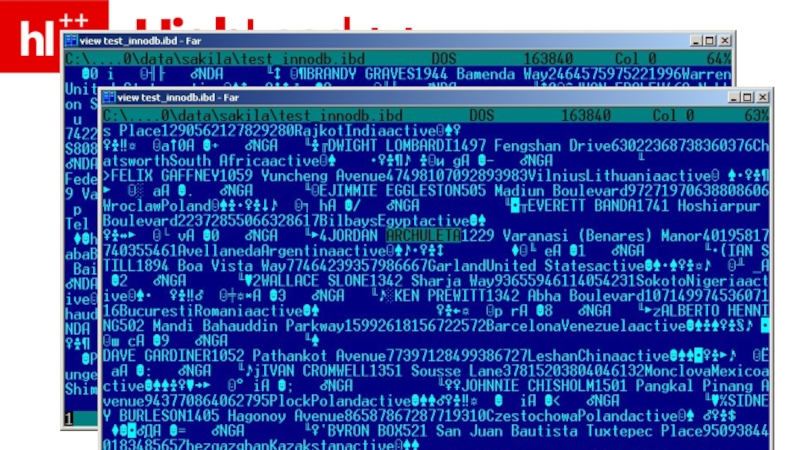
- 33. InnoDB – хранит постранично, внутри странички – в порядке PK
- 34. (InnoDB, после добавления PK)
- 35. MyISAM – “обычное” хранение InnoDB – т.н. “кластерное”
- 36. умеем хранить – теперь нужно быстро искать!
- 37. SELECT * FROM users WHERE id=123
- 38. SELECT * FROM users WHERE lastname=‘Pupkin’
- 39. SELECT * FROM users WHERE lastname LIKE ‘Pu%’
- 40. SELECT * FROM goods WHERE MATCH(‘ipod’) ORDER BY price ASC
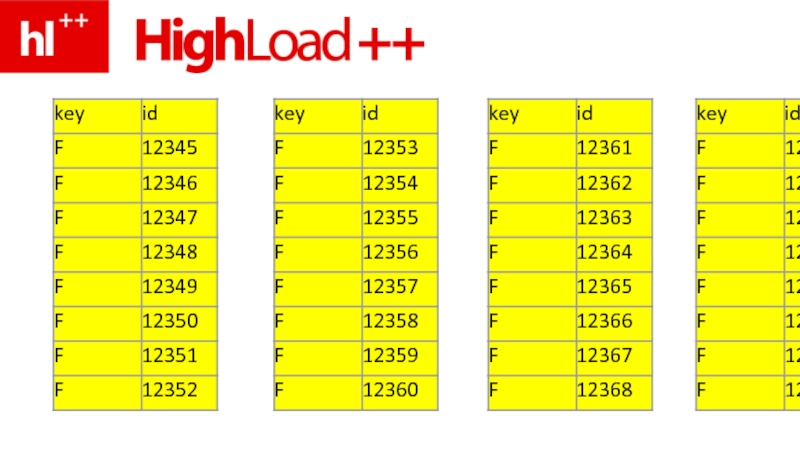
- 41. SELECT * FROM users WHERE sex=‘F’ AND age>=18 AND age
- 43. как выполнять запрос?
- 44. полный перебор? мееедленно
- 45. нас спасут…
- 47. индексы! алгоритмы уже спешат на помощь!
- 48. смысл любого вида индекса?
- 49. быстрый поиск по ключу(-ам)
- 55. видов индексов – тоже много
- 56. hash index
- 57. R-tree index
- 58. full-text index
- 59. индекс общего назначения – типично B-tree
- 60. поиск – по равенству, диапазону (чисел, строк, и т.п.)
- 61. дискует – страничками (хорошо!)
- 62. используется – всеми
- 67. используется несмотря ни на что!!!
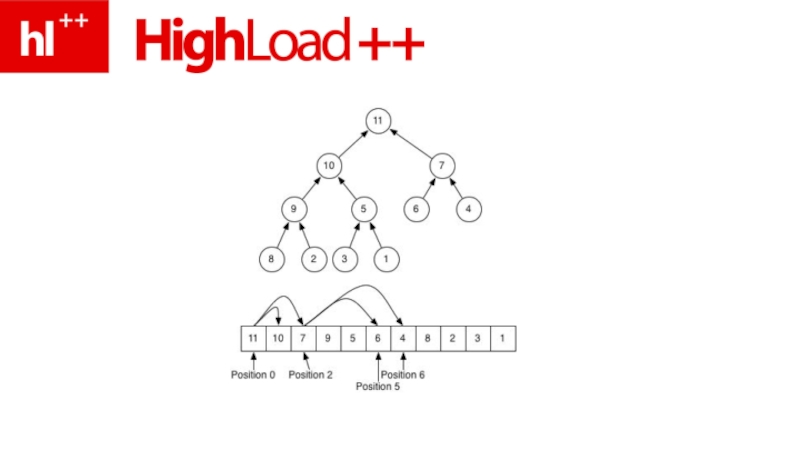
- 68. как устроено?
- 69. (B-дерево; странички; масштаб 1:72)
- 70. два вида страничек
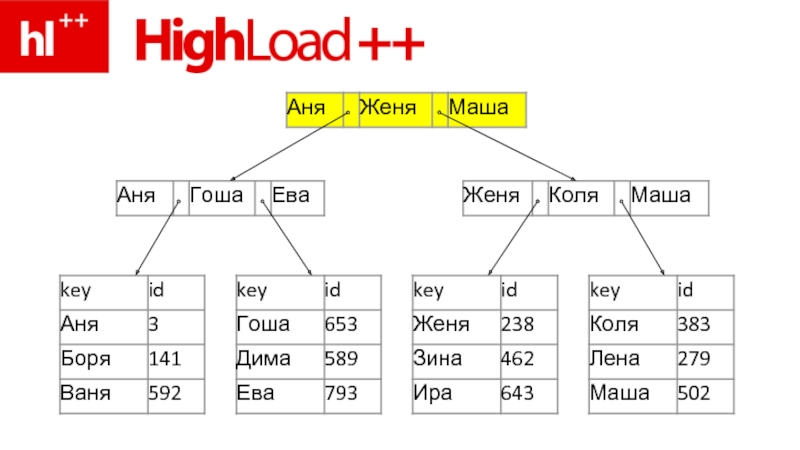
- 71. Промежуточные = ключи + указатели на другие
- 72. Листовые = ключи + соотв-е им данные
- 73. Промежуточные Листовые
- 74. почему все используют этот ужас?!
- 75. во-1х – легко искать по ключу
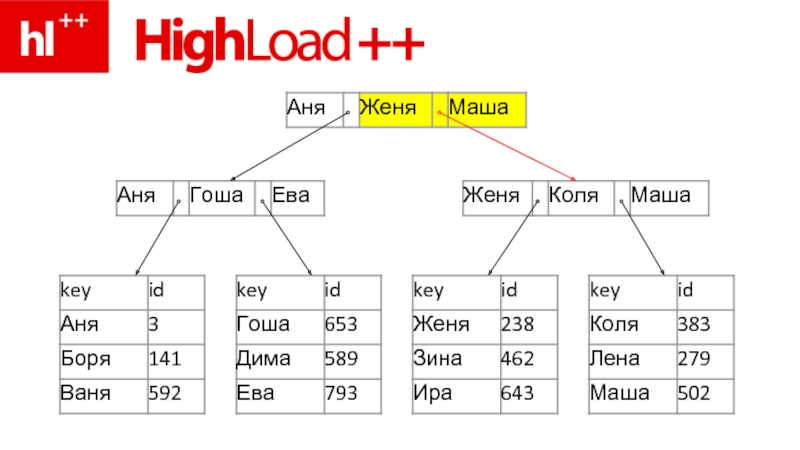
- 76. пример – ищем Зину
- 83. ура – Зина нашлась!!!
- 84. хорошо – поиск работает…
- 85. …но он чё, всегда такой резкий?
- 87. – В жизни – под 1000 (а
- 88. почему все используют этот ужас?!
- 89. во-2х – легко обновлять
- 90. странички обычно НЕ полны
- 91. вставляем…
- 92. вставляем…
- 93. вставляем… оп-па, некуда!!
- 94. создаем новую страничку
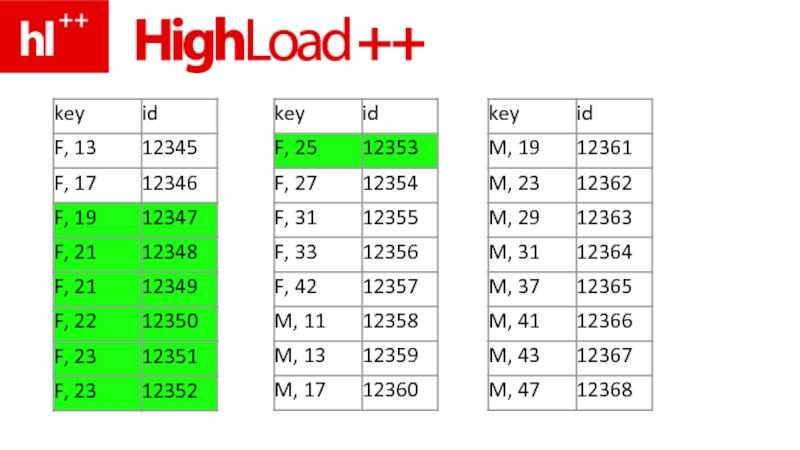
- 95. создаем новую страничку
- 96. …и суем “ее” в родителя
- 97. это все – тоже трогаем max 2-3 странички
- 99. B-tree Kung Fu!!!
- 100. вернемся к запросам?
- 101. SELECT * FROM users WHERE id=123 1.
- 102. усложним – добавим условий
- 103. SELECT * FROM users WHERE sex=‘F’ AND age>=18 AND age
- 104. индекс “в лоб” по sex?
- 107. они ВСЕ подходят по условию ‘F’!
- 109. …и нам надо прочитать с диска (!) 5,000,000+ строк…
- 110. …и для каждой лично проверить паспорт и age>=18 and age
- 112. неселективный индекс – косяк и западло!
- 113. sex=‘F’ AND age>=18 AND age
- 114. но – вдруг это мужики?!
- 115. мужики нам не нужны!!!
- 116. либо опять читать ненужные строки (мужиков) – либо…
- 117. покрывающий (covering) индекс по обоим полям
- 119. список нужных строк – ясен сразу
- 120. чтений с диска – минимум скорости – максимум
- 121. бонус – сортировка по age
- 122. кстати, про сортировку…
- 123. SELECT * FROM users WHERE sex=‘F’ AND age>=18 AND age
- 124. как выполнять? есть варианты
- 126. налево – read_index(WHERE) + read_rows + sort_rows(ORDER)
- 127. индекс данные сортировка результат
- 128. read_index – мало и быстро
- 129. 10K*( 1+4+8 bytes ) = 130 KB 5-10 ms/seek, 50+ MB/s read
- 130. read_random_rows – медленно! 10K*5-10 ms/seek = 50-100 sec…
- 131. sort_rows – обычно быстро 10K*0.1-1 KB/row = 1-10 MB (in RAM)
- 132. мораль – все зло от random rows!
- 133. (еще от sort_rows, если их много)
- 135. … sex=‘F’ AND age>=18 AND age
- 136. направо – read_fat_index(WHERE) + sort_index(ORDER) + LIMIT + read_less_rows + sort_rows
- 137. нужен утолщенный INDEX ( sex, age, hotness )
- 138. вместе с поиском по sex, age – сразу узнаем hotness (+40 KB)
- 139. sort ( 10K * [ hotness, rowptr ] )
- 140. read_rows – почти не нужен (10 строк результата…)
- 141. sort_rows – вообще не нужен
- 142. PROFIT?
- 143. не панацея – даже в теории
- 144. INDEX ( sex, age, hotness ) WHERE sex=‘F’ ORDER BY hotness LIMIT 10
- 145. в теории – обработать 50% индекса затем – прочитать 10 строк (пф!)
- 146. INDEX ( sex, age, hotness ) 1M rows, ~20 MB, 50% = ~10 MB
- 147. INDEX ( sex, age, hotness )
- 148. в теории – читаем индекс линейно – пока не заполним limit
- 149. что на практике?
- 150. welcome to real world
- 151. CREATE TABLE usertest ( id INTEGER PRIMARY
- 152. 500,000 записей 56 MB данных (.ibd файл)
- 153. mysql> explain select * from usertest where sex='f' and age>=18 and age
- 154. filesort – НЕ про временный файл filesort – про “сортировку строк”
- 155. Using where – проверка условия НЕ по индексу – ?!!
- 156. запрос проще, точно по индексу?
- 157. mysql> explain select * from usertest where
- 158. проверим экспериментально!!!
- 159. mysql> select * from usertest where sex='f'
- 160. причина?
- 161. mysql> explain select * from usertest where sex='f' and age>=18 and age
- 162. MySQL не умеет сортировать элементы индекса :(
- 163. сортировка “по индексу” – только если индекс гарантирует порядок
- 164. 1) в куске индекса sex=F, 18
- 165. 2) optimizer лажанул, 18
- 166. (теория говорит – можно лучше!)
- 167. проверяем дальше!
- 168. mysql> explain select * from usertest where
- 169. и последний запрос
- 170. mysql> explain select * from usertest where
- 171. итого
- 172. теория была оптимистична…
- 173. …реальность внесла коррективы.
- 174. не учли детали реализации
- 175. 1. нету “досортировки” индекса (MySQL specific)
- 176. 2. limit обрабатывается… так себе (MySQL specific)
- 177. 3. optimizer ошибается (везде и у всех)
- 178. про ошибки optimizer и спасительный full-scan
- 179. mysql> select * from usertest where sex='f'
- 180. 10,000 x 10 ms = 100 sec
- 181. мораль: random IO очень плохо (водка яд водка яд водка яд)
- 182. про “обработку” limit
- 183. теория – приоритетная очередь
- 186. технически – heap
- 188. или просто double buffer
- 191. ключевое свойство – в памяти храним только top-N
- 192. LIMIT 10 – надо хранить 10 строк
- 193. LIMIT 130,10 – надо 140
- 194. практика – MySQL vs. LIMIT
- 195. выбрать и отсортировать ВСЕ (*) * – всегда, когда индекс не гарантирует точный порядок
- 196. выбрать OK – избежать нельзя
- 198. сортировать все плохо…
- 200. лишний удар по CPU/RAM/IO :(
- 201. как убирать mysql сортировку?
- 202. строить более другие индексы
- 203. ставить более другой софт
- 204. умеет и “обычный” поиск!
- 205. трюки про WHERE вместо LIMIT (я не пробовал, но говорят, возможно)
- 206. …именно в таком порядке.
- 207. более практический пример?
- 208. импортируем дамп Wikipedia
- 209. XML дамп → 2 толстые таблицы хочется – а) одну б) тонкую!
- 210. INSERT INTO mycontent SELECT t.old_id, p.page_id, UNIX_TIMESTAMP(p.page_touched),
- 211. mysql> EXPLAIN SELECT t.old_id, ... \G **********************
- 212. что хотим? scan 15 GB text, join 0.5 GB page
- 213. почему не выходит? … FROM text t, page p WHERE t.old_id=p.page_latest
- 214. решение – index(page_latest)
- 215. еще пришлось STRAIGHT_JOIN (optimizer опять лажанул!)
- 216. результат – 40 минут, включая CREATE INDEX
- 218. так зачем же знать алгоритмы?
- 219. “did we learn something today?”
- 221. как устроено B-дерево
- 222. как работает индекс
- 223. как работают выборки
- 224. зачем нужны full-scans
- 225. как работает сортировка с LIMIT
- 226. чего можно добиться в идеале – в теории
- 227. …и как оно, бывает, не работает – на практике!
- 228. а толку?!
- 229. чего ждать от БД
- 230. чего не ждать
- 231. как и что тестировать
- 232. как объяснять потом результаты
- 234. в итоге – как заставлять таки работать
- 236. …БЫСТРО работать.
- 237. “это все” (с) вопросы?!

















")
")






")

")





 ORDER BY price ASC")








")










")
")







")


{ key1, data1, key2, data2, … }")




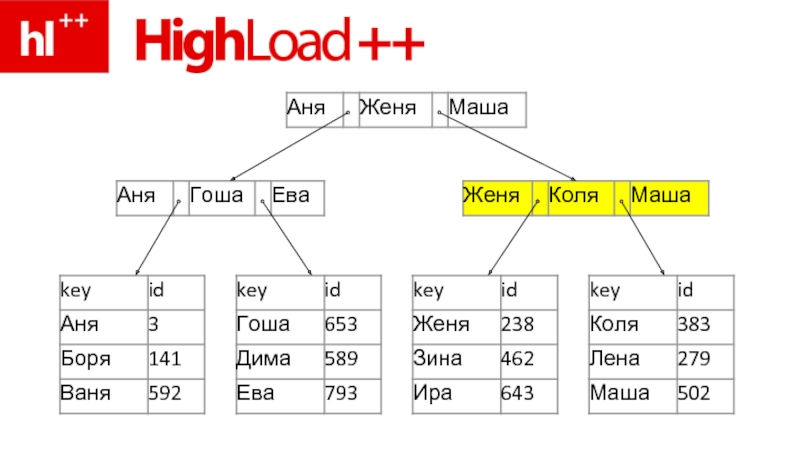




Слайд 87– В жизни – под 1000 (а не 3) записей на
страничку
– Два уровня страничек – 1000*1000 – миллион
– Три уровня – миллиард…
– Итого 2-3 странички max – практически всегда
 записей на страничку – Два уровня")













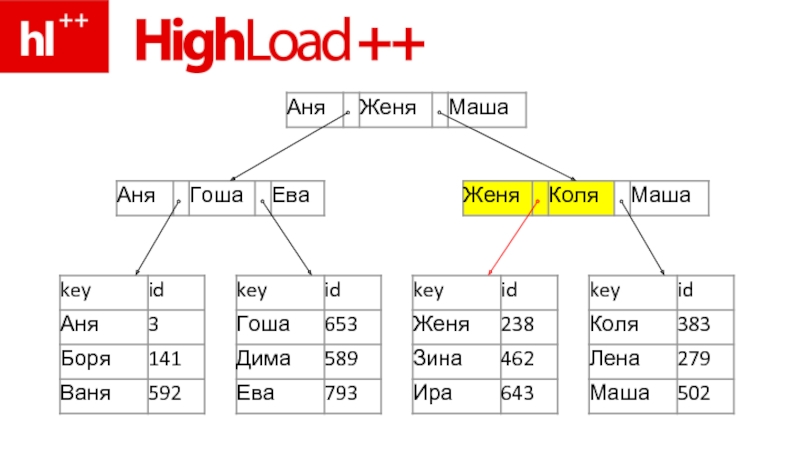
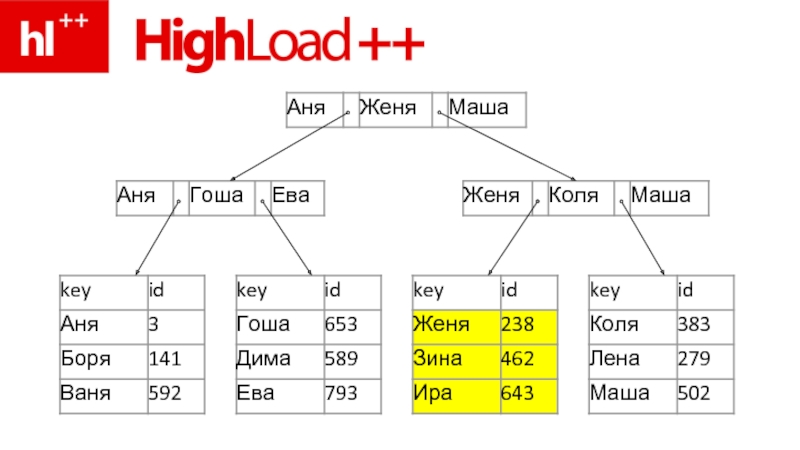
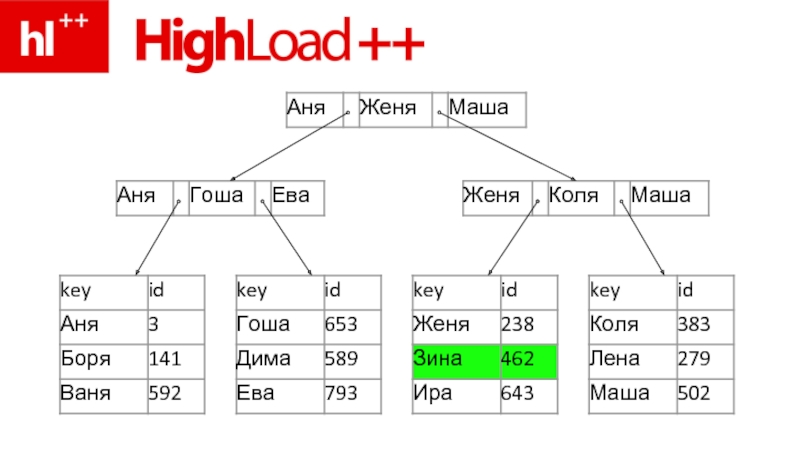
Слайд 101SELECT * FROM users WHERE id=123
1. “Ищем Зину” (rowoffset по id=123)
2.
seek(rowoffset) в файле строк (.MYD)
3. read(rowdata) из файла
4. и… все – результат готов
2. seek(rowoffset) в файле строк")





 5,000,000+ строк…")






 – либо…")
 индекс по обоим полям")







 + read_rows + sort_rows(ORDER)")


 = 130 KB 5-10 ms/seek, 50+ MB/s read")

")

")


 + sort_index(ORDER) + LIMIT + read_less_rows + sort_rows")
")
")
")
")



 WHERE sex=‘F’ ORDER BY hotness LIMIT 10")
")
 1M rows, ~20 MB, 50% = ~10 MB")
 WHERE sex=‘F’ AND hotness>0 ORDER BY age LIMIT 10")



Слайд 151CREATE TABLE usertest ( id INTEGER PRIMARY KEY NOT NULL, sex ENUM
('m','f'),
age INTEGER NOT NULL,
hotness INTEGER NOT NULL,
name VARCHAR(255) NOT NULL, INDEX(sex,age,hotness) )
, age INTEGER")
Слайд 152500,000 записей 56 MB данных (.ibd файл) 32 MB innodb_buffer_pool age \in [18.. 80] hotness
\in [-5.. 5]
 32 MB innodb_buffer_pool age \in [18.. 80] hotness")
Слайд 153mysql> explain select * from usertest where sex='f' and age>=18 and age
by hotness desc limit 10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: usertest
type: ref
possible_keys: sex
key: sex
key_len: 2
ref: const
rows: 25119
Extra: Using where; Using filesort
1 row in set (0.00 sec)




Слайд 157mysql> explain select * from usertest where sex='f' and age=18 order by hotness
desc limit 10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: usertest
type: ref
possible_keys: sex
key: sex
key_len: 6
ref: const,const
rows: 10386
Extra: Using where (bug #30733, 30 aug 2007?)
1 row in set (0.00 sec)


Слайд 159mysql> select * from usertest where sex='f' and age>=18 and age
hotness desc limit 10;
...
10 rows in set (23.05 sec)
mysql> select * from usertest where sex='f' and
age=18
order by hotness desc limit 10;
...
10 rows in set (0.05 sec)


Слайд 161mysql> explain select * from usertest where sex='f' and age>=18 and age
by hotness desc limit 10 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: usertest
type: ref
possible_keys: sex
key: sex
key_len: 2 ← используется только начало, поле “sex”!!!
ref: const
rows: 25119
Extra: Using where; Using filesort ← так и есть :(
1 row in set (0.00 sec)



 в куске индекса sex=F, 18")
 optimizer лажанул, 18")
")

Слайд 168mysql> explain select * from usertest where sex='f' order by hotness desc
limit 10 \G
...
key: sex
key_len: 2
ref: const
rows: 226072
Extra: Using where; Using filesort
mysql> explain select * from usertest
where sex='f' order by hotness desc limit 10 \G
...
10 rows in set (20.25 sec)


Слайд 170mysql> explain select * from usertest where sex='f' and hotness>0 order
by age asc limit 10 \G
...
key: sex
key_len: 2
ref: const
rows: 226072
Extra: Using where; Using filesort
mysql> select * from usertest where sex='f' and hotness>0 order by age asc limit 10;
...
10 rows in set (0.25 sec)





")
")
")

Слайд 179mysql> select * from usertest where sex='f' order by hotness desc
limit 10;
...
10 rows in set (20.25 sec)
mysql> select * from usertest ignore index(sex) where sex='f' order by hotness desc limit 10;
...
10 rows in set (0.55 sec)


")






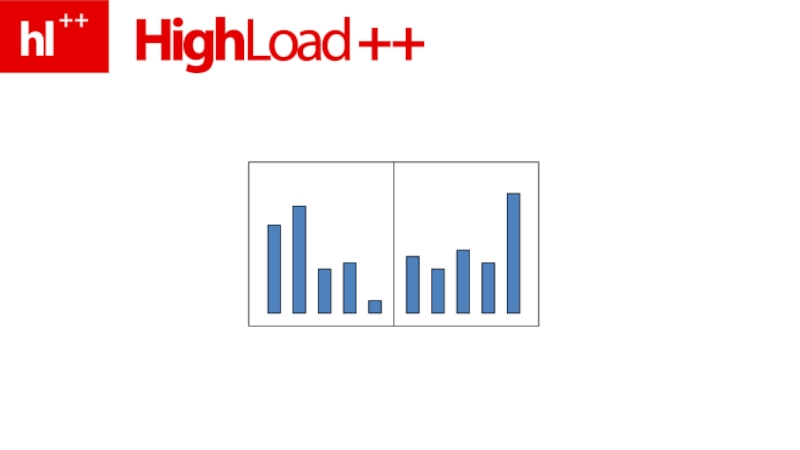
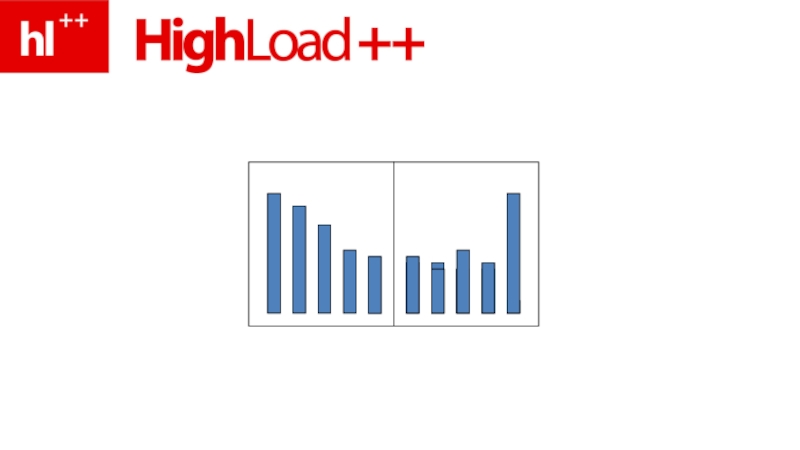




* – всегда, когда индекс не гарантирует точный порядок")









")



 одну б) тонкую!")
Слайд 210INSERT INTO mycontent SELECT t.old_id, p.page_id, UNIX_TIMESTAMP(p.page_touched), p.page_len, p.page_title, COMPRESS(t.old_text) FROM text t,
page p
WHERE t.old_id=p.page_latest
AND page_namespace=0 AND page_is_redirect=0;
15 GB text, 0.5 GB page, ~4.5M rows
tps=~200, bi/bo=~1 MB/sec
~200 MB .MYD in ~20 mins, ETA 10+ hrs
, p.page_len, p.page_title, COMPRESS(t.old_text) FROM text t, page p")
Слайд 211mysql> EXPLAIN SELECT t.old_id, ... \G ********************** 1. row **********************
table: page
type: ref
key: name_title
ref: const
rows: 4435392
Extra: Using where
********************** 2. row **********************
table: text
type: eq_ref
key: PRIMARY
ref: wiki.p.page_latest
rows: 1



")
")





















 вопросы?!")





