- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Введение в оптимизацию приложений с использованием инструментов Intel® презентация
Содержание
- 1. Введение в оптимизацию приложений с использованием инструментов Intel®
- 2. Из материалов курса вы узнаете:
- 3. После изучения курса вы сможете: описать
- 4. План Архитектура микропроцессора Intel® и основные факторы
- 5. Архитектура микропроцессора Intel® и основные факторы влияющие на его производительность.
- 6. Упрощенная модель процессора Оперативная память (RAM) Системная
- 7. Упрощенная модель процессора устройство управления
- 8. Высокая производительность МП –один из ключевых
- 9. Тактовая частота Процессор состоит из компонент,
- 10. Скорость выполнения и набор инструкций Производительность зависит
- 11. Использование регистров и оперативной памяти Время
- 12. Кэширование Кэш-память служит для уменьшения времени доступа
- 13. Характерные времена отклика при обращении к
- 14. Принцип локальности. Качество упреждающей выборки. Локальность ссылки
- 15. Конвейер Instruction fetch Register fetch
- 16. Качество конвейеризации, уровень параллелизма инструкций Конвейеризация предполагает,
- 17. Качество предсказания переходов Инструкции могут быть
- 18. Суперскалярность Суперскалярный процессор – процессор, способный выполнять
- 19. Упрощенная модель процессора Оперативная память (RAM) Упреждающая
- 20. Использование векторных инструкций, векторизация Типичная векторная инструкция
- 21. Опережающий просмотр потока инструкций Для того, чтобы
- 24. Параллельные вычисления Многозадачность. Многопоточность. Гиперпоточность (Hyper-threading
- 25. Основные характеристики приложения, влияющие на его производительность
- 26. Измерение производительности От каких факторов зависит
- 27. Место и роль компилятора. Компилятор — транслятор,
- 28. Литература Randy Allen & Ken Kennedy “Optimizing
- 29. Спасибо за внимание!
Слайд 1Введение в оптимизацию приложений с использованием инструментов Intel®
Андрей Ануфриенко
Intel Compiler Group
Ренат
Идрисов

Слайд 2 Из материалов курса вы узнаете:
о проблемах, влияющих на производительность
процессора.
о техниках улучшения производительности приложения
об инструментах Intel® для анализа производительности приложения
об оптимизирующем компиляторе Intel®, его основных компонентах и ключах компиляции
о теоретических основах некоторых основных оптимизаций
о техниках улучшения производительности приложения
об инструментах Intel® для анализа производительности приложения
об оптимизирующем компиляторе Intel®, его основных компонентах и ключах компиляции
о теоретических основах некоторых основных оптимизаций

Слайд 3 После изучения курса вы сможете:
описать главные проблемы, влияющие на производительность
процессора
исследовать приложение с помощью VTune™ Performance Analyzer и найти проблемные места
идентифицировать главные проблемы анализируемого приложения
разработать стратегию улучшения производительности приложения
описать главные компоненты компилятора, их основные функции
управлять уровнем оптимизации с помощью ключей компилятора
исследовать приложение с помощью VTune™ Performance Analyzer и найти проблемные места
идентифицировать главные проблемы анализируемого приложения
разработать стратегию улучшения производительности приложения
описать главные компоненты компилятора, их основные функции
управлять уровнем оптимизации с помощью ключей компилятора

Слайд 4План
Архитектура микропроцессора Intel® и основные факторы влияющие на его производительность.
Использование VTune™.
Роль
компилятора в улучшении производительности приложения.
Граф управления, анализ потока данных.
Перестановочные оптимизации и их применимость.
Векторизация.
Распараллеливание при помощи директив OpenMP, распараллеливание в автоматическом режиме.
Основные компоненты компилятора, их задачи и взаимосвязь.
Граф управления, анализ потока данных.
Перестановочные оптимизации и их применимость.
Векторизация.
Распараллеливание при помощи директив OpenMP, распараллеливание в автоматическом режиме.
Основные компоненты компилятора, их задачи и взаимосвязь.


Слайд 6Упрощенная модель процессора
Оперативная
память
(RAM)
Системная шина
Вычислительное
устройство
(ALU)
Управляющее
устройство
(CU)
Устройство
взаимодействия
с внешней
памятью
Внешняя
память
Шина
ввода-вывода
Процессор
Команды
Данные
Регистры
Системная шинаВычислительное устройство(ALU)Управляющееустройство(CU)Устройство взаимодействияс внешней памятьюВнешняя памятьШинаввода-выводаПроцессорКомандыДанныеРегистры")
Слайд 7 Упрощенная модель процессора
устройство управления (Control Unit, CU)
арифметико-логическое устройство (Arithmetic
and Logic Unit, ALU)
системные регистры
системная шина (Front Side Bus, FSB)
память
периферийные устройства
Устройство управления (CU):
выполняет дешифрацию инструкций, поступающих из памяти компьютера.
управляет ALU.
осуществляет пересылку данных между регистрами ЦП, памятью, периферийными устройствами.
Арифметико-логическое устройство:
позволяет производить арифметические и логические операции над системными регистрами.
Системные регистры:
определенный участок памяти внутри ЦП, используемый для промежуточного хранения информации, обрабатываемой процессором.
Системная шина:
используется для пересылки данных между ЦП и памятью, а также между ЦП и периферийными устройствами.
системные регистры
системная шина (Front Side Bus, FSB)
память
периферийные устройства
Устройство управления (CU):
выполняет дешифрацию инструкций, поступающих из памяти компьютера.
управляет ALU.
осуществляет пересылку данных между регистрами ЦП, памятью, периферийными устройствами.
Арифметико-логическое устройство:
позволяет производить арифметические и логические операции над системными регистрами.
Системные регистры:
определенный участок памяти внутри ЦП, используемый для промежуточного хранения информации, обрабатываемой процессором.
Системная шина:
используется для пересылки данных между ЦП и памятью, а также между ЦП и периферийными устройствами.
 арифметико-логическое устройство (Arithmetic and Logic Unit, ALU)системные")
Слайд 8 Высокая производительность МП –один из ключевых факторов в конкурентной борьбе
производителей процессоров.
Производительность процессора напрямую связана с количеством работы, вычислений, которые он может выполнить за единицу времени.
Очень условно:
Производительность = Кол-во инструкций / Время
Мы будем рассматривать производительность процессоров на базе IA32 и IA32e архитектур.
(IA32 with EM64T).
Факторы влияющие на производительность процессора:
Тактовая частота процессора.
Объем адресуемой памяти и скорость доступа к внешней памяти.
Скорость выполнения и набор инструкций.
Использование внутренней памяти, регистров.
Качество конвейеризации.
Качество предсказания переходов.
Качество упреждающей выборки.
Суперскалярность.
Наличие векторных инструкций.
Многоядерность.
Производительность процессора напрямую связана с количеством работы, вычислений, которые он может выполнить за единицу времени.
Очень условно:
Производительность = Кол-во инструкций / Время
Мы будем рассматривать производительность процессоров на базе IA32 и IA32e архитектур.
(IA32 with EM64T).
Факторы влияющие на производительность процессора:
Тактовая частота процессора.
Объем адресуемой памяти и скорость доступа к внешней памяти.
Скорость выполнения и набор инструкций.
Использование внутренней памяти, регистров.
Качество конвейеризации.
Качество предсказания переходов.
Качество упреждающей выборки.
Суперскалярность.
Наличие векторных инструкций.
Многоядерность.

Слайд 9Тактовая частота
Процессор состоит из компонент, срабатывающих в разное время и
в нём существует таймер, который обеспечивает синхронизацию, посылая периодические импульсы. Его частота и называется тактовой частотой процессора.
Объем адресуемой памяти
8086 – 1МБ.
80286 – 16МБ (новые системные регистры и новый режим работы с памятью).
80386 – 4ГБ (первый 32-битный процессор
технология EM64T – ~264Б)
Объем адресуемой памяти
8086 – 1МБ.
80286 – 16МБ (новые системные регистры и новый режим работы с памятью).
80386 – 4ГБ (первый 32-битный процессор
технология EM64T – ~264Б)

Слайд 10Скорость выполнения и набор инструкций
Производительность зависит от того, насколько качественно реализованы
инструкции, насколько полно базовый набор инструкций покрывает все возможные задачи.
CISC,RISC (complex, reduced instruction set computing)
Современные процессоры Intel® представляют собой гибрид CISC и RISC процессоров, перед исполнением преобразуют CISC инструкции в более простой набор RISC инструкций.
CISC,RISC (complex, reduced instruction set computing)
Современные процессоры Intel® представляют собой гибрид CISC и RISC процессоров, перед исполнением преобразуют CISC инструкции в более простой набор RISC инструкций.

Слайд 11Использование регистров и оперативной памяти
Время доступа к регистрам наименьшее, поэтому
кол-во доступных регистров влияет на производительность микропроцессора.
Вытеснение регистров (register spilling) – из-за недостаточного кол-ва регистров велик обмен между регистрами и стеком приложения.
Ia32
Технология EM64T – добавлены дополнительные системные регистры
С ростом производительности процессоров возникла проблема, связанная с тем, что скорость доступа к внешней памяти стала ниже скорости вычислений.
Существуют две характеристики для описания свойств памяти:
Время отклика (latency) – число циклов процессора необходимых для передачи единицы данных из памяти.
Пропускная способность (bandwidth) – количество элементов данных которые могут быть отправлены процессору из памяти за один цикл.
Две возможные стратегии для ускорения быстродействия– уменьшение времени отклика или упреждающий запрос нужной памяти.
Вытеснение регистров (register spilling) – из-за недостаточного кол-ва регистров велик обмен между регистрами и стеком приложения.
Ia32
Технология EM64T – добавлены дополнительные системные регистры
С ростом производительности процессоров возникла проблема, связанная с тем, что скорость доступа к внешней памяти стала ниже скорости вычислений.
Существуют две характеристики для описания свойств памяти:
Время отклика (latency) – число циклов процессора необходимых для передачи единицы данных из памяти.
Пропускная способность (bandwidth) – количество элементов данных которые могут быть отправлены процессору из памяти за один цикл.
Две возможные стратегии для ускорения быстродействия– уменьшение времени отклика или упреждающий запрос нужной памяти.

Слайд 12Кэширование
Кэш-память служит для уменьшения времени доступа к данным.
Для этого блоки оперативной
памяти отображаются в более быструю кэш-память.
Если адрес памяти находится в кэше – происходит «попадание» и скорость получения данных значительно увеличивается.
В противном случае – «промах» (cash miss)
В этом случае блок оперативной памяти считывается в кэш-память за один или несколько циклов шины, называемых заполнением строки кэш-памяти.
Можно выделить следующие виды кэш-памяти:
полностью ассоциативная кэш-память (каждый блок может отображаться в любое место кэша)
память с прямым отображением (каждый блок может отображаться в одно место)
гибридные варианты (секторная память, память с множественно-ассоциативным доступом)
Множественно-ассоциативный доступ – по младшим разрядам определяется строка кэша, куда может отображаться данная память, но в этой строке может находиться только несколько слов основной памяти, выбор из которых проводится на ассоциативной основе.
Качество использования кэша – ключевое условие быстродействия.
Если адрес памяти находится в кэше – происходит «попадание» и скорость получения данных значительно увеличивается.
В противном случае – «промах» (cash miss)
В этом случае блок оперативной памяти считывается в кэш-память за один или несколько циклов шины, называемых заполнением строки кэш-памяти.
Можно выделить следующие виды кэш-памяти:
полностью ассоциативная кэш-память (каждый блок может отображаться в любое место кэша)
память с прямым отображением (каждый блок может отображаться в одно место)
гибридные варианты (секторная память, память с множественно-ассоциативным доступом)
Множественно-ассоциативный доступ – по младшим разрядам определяется строка кэша, куда может отображаться данная память, но в этой строке может находиться только несколько слов основной памяти, выбор из которых проводится на ассоциативной основе.
Качество использования кэша – ключевое условие быстродействия.

Слайд 13 Характерные времена отклика при обращении к кэш памяти для Nehalem
i7:
L1 - latency 4
L2 - latency 11
L3 - latency 38
Время отклика для оперативной памяти > 100
Упреждающий механизм доступа к памяти реализован при помощи механизма упреждающей выборки (hardware prefetching).
Есть специальный набор инструкций, позволяющий побудить процессор загрузить в кэш память расположенную по определенному адресу (software prefetching).
L1 - latency 4
L2 - latency 11
L3 - latency 38
Время отклика для оперативной памяти > 100
Упреждающий механизм доступа к памяти реализован при помощи механизма упреждающей выборки (hardware prefetching).
Есть специальный набор инструкций, позволяющий побудить процессор загрузить в кэш память расположенную по определенному адресу (software prefetching).

Слайд 14Принцип локальности. Качество упреждающей выборки.
Локальность ссылки (locality of reference) – повторное
использование переменных или взаимосвязанных данных. Различают временную локальность (temporal locality) – когда речь идёт об одних и тех же данных и пространственную локальность (spatial locality) – использование различных данных, имеющих относительно близкие области хранения.
Механизм кэширования использует принцип временной локальности. (Стремится сохранять в кэше наиболее часто используемые данные).
Механизм упреждающей выборки использует принцип пространственной локальности. (Стремится определить закономерность в доступе к памяти, чтобы заранее подгружать в кэш необходимую память). При этом, чем выше пространственная локальность (элементы расположены ближе в памяти), тем меньше данных требуется загружать в кэш и меньше нагрузка на системную шину.
Кэш aliasing – из-за неудачного расположения в памяти различных объектов, участвующих в вычислении, происходит вытеснению из кэш памяти одних адресов другими.
Механизм кэширования использует принцип временной локальности. (Стремится сохранять в кэше наиболее часто используемые данные).
Механизм упреждающей выборки использует принцип пространственной локальности. (Стремится определить закономерность в доступе к памяти, чтобы заранее подгружать в кэш необходимую память). При этом, чем выше пространственная локальность (элементы расположены ближе в памяти), тем меньше данных требуется загружать в кэш и меньше нагрузка на системную шину.
Кэш aliasing – из-за неудачного расположения в памяти различных объектов, участвующих в вычислении, происходит вытеснению из кэш памяти одних адресов другими.
 – повторное использование переменных или взаимосвязанных")
Слайд 15Конвейер
Instruction
fetch
Register
fetch
Instruction
decode
Execution
Data
fetch
Write
back
instr. 1
-
-
-
-
-
instr. 2
instr. 1
-
-
-
-
instr. 3
instr. 1
-
-
-
instr. 4
instr. 1
-
-
instr. 5
instr.
1
-
instr. 1
instr. 2
instr. 2
instr. 2
instr. 2
instr. 2
instr. 3
instr. 3
instr. 3
instr. 3
instr. 4
instr. 4
instr. 4
instr. 5
instr. 5
instr. 6
instr. 6
instr. 7
tick
0
1
2
3
4
5
6

Слайд 16Качество конвейеризации, уровень параллелизма инструкций
Конвейеризация предполагает, что последовательные инструкции будут перекрываться
при выполнении.
Выполнение типичной команды можно разделить на следующие этапы:
выборка команды – IF;
декодирование команды / выборка операндов из регистров - ID;
выполнение операции / вычисление эффективного адреса памяти - EX;
обращение к памяти - MEM;
запоминание результата - WB.
Конвейеризация улучшает пропускную способность процессора, но если инструкции зависят от результатов выполнения предыдущих инструкций, то возникают задержки. Таким образом, польза от конвейеризации определяется уровнем инструкционного параллелизма.
Выполнение типичной команды можно разделить на следующие этапы:
выборка команды – IF;
декодирование команды / выборка операндов из регистров - ID;
выполнение операции / вычисление эффективного адреса памяти - EX;
обращение к памяти - MEM;
запоминание результата - WB.
Конвейеризация улучшает пропускную способность процессора, но если инструкции зависят от результатов выполнения предыдущих инструкций, то возникают задержки. Таким образом, польза от конвейеризации определяется уровнем инструкционного параллелизма.

Слайд 17Качество предсказания переходов
Инструкции могут быть зависимыми по данным и по управляющей
логике программы. (Data dependence and control flow dependence).
Эффективность суперскалярных и конвейерных механизмов во многом ограничивается различными условными переходами внутри программы.
Существует специальный механизм предсказания переходов (branch prediction).
МПП выбирает один из возможных путей и продолжает выбирать инструкции и нагружать конвейеры МП работой. В момент, когда условие перехода вычислено, определяется, не ошибся ли предсказатель.
Ошибка предсказателя (branch misprediction) - все уже выполненные или еще находящиеся в обработке инструкции удаляются, и МП заново заполняет конвейеры.
Можно выделить статический и динамический предсказатель.
Динамический предсказатель отличается тем, что собирает статистику на каждое ветвление и делает предсказание на основании собранной статистики.
Тривиальное предсказание – переход не будет выполнен в случае если осуществляется переход вперед и будет выполнен – если происходит переход назад.
Существует также механизм предсказания цели ветвления (branch target prediction), который предсказывает безусловные переходы.
Эффективность суперскалярных и конвейерных механизмов во многом ограничивается различными условными переходами внутри программы.
Существует специальный механизм предсказания переходов (branch prediction).
МПП выбирает один из возможных путей и продолжает выбирать инструкции и нагружать конвейеры МП работой. В момент, когда условие перехода вычислено, определяется, не ошибся ли предсказатель.
Ошибка предсказателя (branch misprediction) - все уже выполненные или еще находящиеся в обработке инструкции удаляются, и МП заново заполняет конвейеры.
Можно выделить статический и динамический предсказатель.
Динамический предсказатель отличается тем, что собирает статистику на каждое ветвление и делает предсказание на основании собранной статистики.
Тривиальное предсказание – переход не будет выполнен в случае если осуществляется переход вперед и будет выполнен – если происходит переход назад.
Существует также механизм предсказания цели ветвления (branch target prediction), который предсказывает безусловные переходы.

Слайд 18Суперскалярность
Суперскалярный процессор – процессор, способный выполнять несколько операций за один такт.
Как следствие, для такого типа процессора обязательно наличие нескольких исполнительных блоков (execution unit).
Основными компонентами суперскалярного процессора являются устройства для интерпретации команд, снабженные логикой, позволяющей определить, являются ли команды независимыми, и достаточное число исполняющих устройств.
Pentium - первый суперскалярный процессор архитектуры x86.
Выигрыш от суперскалярности определяется уровнем параллелизма инструкций.
«Разнообразие» поступающих на конвейер инструкций позволяет более полно нагружать исполняемые устройства.

Слайд 19Упрощенная модель процессора
Оперативная
память
(RAM)
Упреждающая выборка
Вычислительное
устройство
(ALU)
Управляющее
устройство
(CU)
Устройство
взаимодействия
с внешней
памятью
Внешняя
память
Шина
ввода-вывода
Суперскалярность
Конвейеризация, предсказание переходов
Регистры
Вычислительное
устройство
(ALU)
Регистры
Система
кэшей
Упреждающая выборкаВычислительное устройство(ALU)Управляющееустройство(CU)Устройство взаимодействияс внешней памятьюВнешняя памятьШинаввода-выводаСуперскалярностьКонвейеризация, предсказание переходовРегистрыВычислительное устройство(ALU)РегистрыСистема кэшей")
Слайд 20Использование векторных инструкций, векторизация
Типичная векторная инструкция выполняет элементарную операцию над двумя
векторными последовательностями в памяти или векторными регистрами фиксированной длины.
C(1:n) = A(1:n) +B(1:n)
Векторизация – процесс конвертации компьютерной программы из скалярного представления, в котором одна операция выполняется над парой операндов, в векторное представление, в котором одна операция выполняется над парой векторных операндов.
В Pentium III новая технология SSE (Streaming SIMD Extensions), которая добавила в МП 8 128 битных регистра (XMM0-XMM7) и 70 новых инструкций в том числе для работы с вещественными числами. SSE2,SSE3,SSEE3,SSE4,SSE4.2,AVX – последующие расширения этой идеи.
C(1:n) = A(1:n) +B(1:n)
Векторизация – процесс конвертации компьютерной программы из скалярного представления, в котором одна операция выполняется над парой операндов, в векторное представление, в котором одна операция выполняется над парой векторных операндов.
В Pentium III новая технология SSE (Streaming SIMD Extensions), которая добавила в МП 8 128 битных регистра (XMM0-XMM7) и 70 новых инструкций в том числе для работы с вещественными числами. SSE2,SSE3,SSEE3,SSE4,SSE4.2,AVX – последующие расширения этой идеи.

Слайд 21Опережающий просмотр потока инструкций
Для того, чтобы эффективно использовать несколько АЛУ и
конвейер, современные микропроцессоры используют опережающий просмотр потока инструкций. Это позволяет определить те инструкции, которые могут вычисляться параллельно.
Также возможно исполнение с изменением последовательности операций (out-of-order execution).
Но технологии опережающего просмотра инструкций (lookahead) не могут решить проблему простоя АЛУ и конвейера в случае низкого уровня инструкционного параллелизма.
Также возможно исполнение с изменением последовательности операций (out-of-order execution).
Но технологии опережающего просмотра инструкций (lookahead) не могут решить проблему простоя АЛУ и конвейера в случае низкого уровня инструкционного параллелизма.

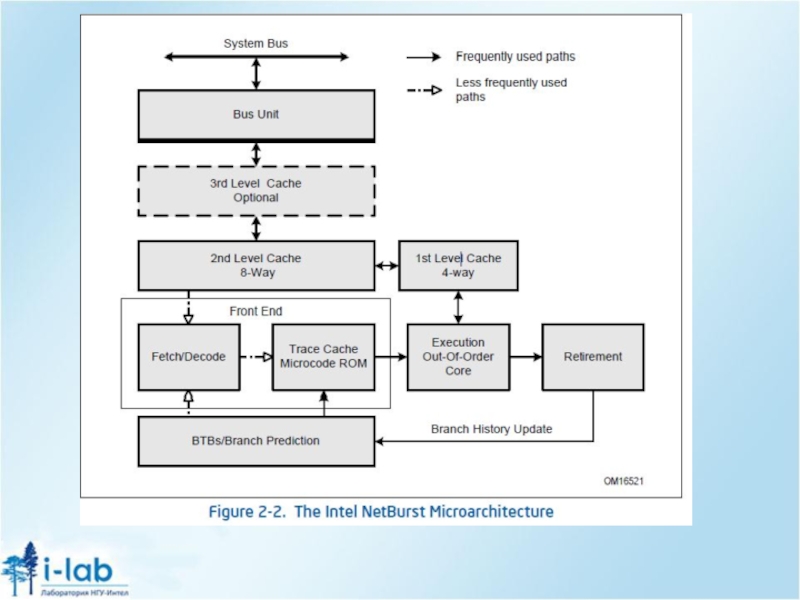
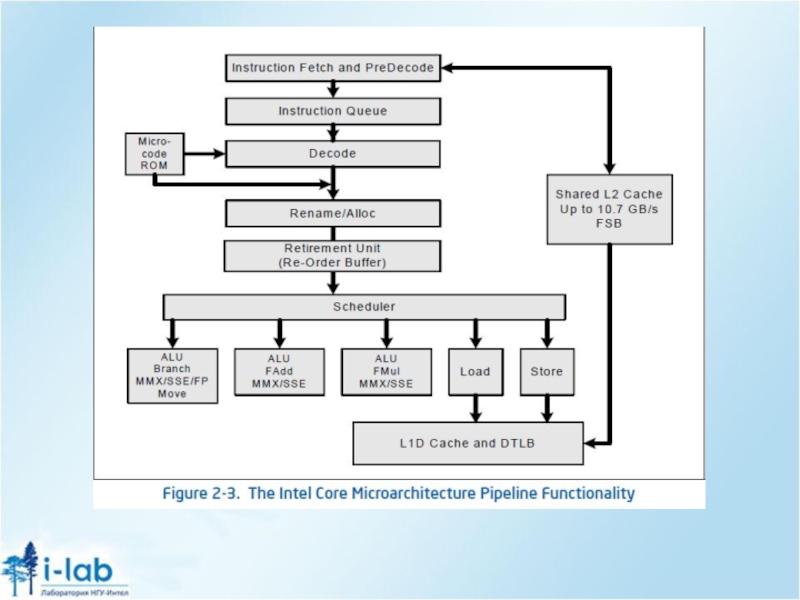
Слайд 24Параллельные вычисления
Многозадачность.
Многопоточность.
Гиперпоточность (Hyper-threading Pentium 4 – Core i7)
Многоядерность
Многопроцессорные решения
Наличие
нескольких вычислительных ядер дает возможность достижения высокой производительности приложения распределением вычислений между этими вычислительными ядрами.
МногоядерностьМногопроцессорные решения Наличие нескольких вычислительных ядер дает возможность")
Слайд 25Основные характеристики приложения, влияющие на его производительность
Эффективность вычислений
Эффективность работы с памятью
Правильное
предсказание переходов
Эффективность использования векторных инструкций
Эффективность параллелизации
Уровень инструкционного параллелилизма
Эффективность использования векторных инструкций
Эффективность параллелизации
Уровень инструкционного параллелилизма

Слайд 26Измерение производительности
От каких факторов зависит производительность конкретной программы?
качество работы оптимизирующего
компилятора
работа МП
Потребителям необходимы критерии определения производительности вычислительной системы
Репрезентативная выборка типичных задач
Универсальная схема тестирования
Независимость от производителей МП
Spec.org (Standart Performance Evaluated Corporation) – некоммерческая организация для подготовки, поддержки и сопровождения стандартного набора тестов для сравнения производительности различных вычислительных систем. Эта организация разрабатывает стандартные пакеты и публикует результаты измерений.
CPU2006 – разработана для измерения производительности. Может быть использована для сравнения работы программ, выполняемых на различных вычислительных системах. CINT2006 для целочисленных вычислений.
CFP2006 для сравнения производительности работы с вещественными числами.
OMP2001 – измеряет производительность на тестах с использованием OpenMP (это библиотека для параллельных вычислений с общей памятью (shared-memory parallel processing)).
работа МП
Потребителям необходимы критерии определения производительности вычислительной системы
Репрезентативная выборка типичных задач
Универсальная схема тестирования
Независимость от производителей МП
Spec.org (Standart Performance Evaluated Corporation) – некоммерческая организация для подготовки, поддержки и сопровождения стандартного набора тестов для сравнения производительности различных вычислительных систем. Эта организация разрабатывает стандартные пакеты и публикует результаты измерений.
CPU2006 – разработана для измерения производительности. Может быть использована для сравнения работы программ, выполняемых на различных вычислительных системах. CINT2006 для целочисленных вычислений.
CFP2006 для сравнения производительности работы с вещественными числами.
OMP2001 – измеряет производительность на тестах с использованием OpenMP (это библиотека для параллельных вычислений с общей памятью (shared-memory parallel processing)).

Слайд 27Место и роль компилятора.
Компилятор — транслятор, который осуществляет перевод всей исходной
программы в эквивалентную ей результирующую программу на языке машинных команд или на языке ассемблера.
Играет ли компилятор какую-либо роль в борьбе за производительность МП?
Компилятор используется во время тестирования и отладки функциональности новых МП.
Только с помощью компилятора можно показать рост производительности МП связанный с новыми командами, увеличением количества регистров и т.п.
Компилятор способен скрыть неудачи архитекторов.
Играет ли компилятор какую-либо роль в борьбе за производительность МП?
Компилятор используется во время тестирования и отладки функциональности новых МП.
Только с помощью компилятора можно показать рост производительности МП связанный с новыми командами, увеличением количества регистров и т.п.
Компилятор способен скрыть неудачи архитекторов.

Слайд 28Литература
Randy Allen & Ken Kennedy “Optimizing compilers for modern architectures”
David F.
Bacon, Susan L. Graham and Oliver J.Sharp “Compiler transformations for High-Performance Computing”
Aart J.C. Bik “The Software Vectorization Handbook”
Richard Gerber, Aart J.C. Bik, Kevin B.Smith, Xinmin Tian “The Software Optimization Cookbook”
Intel® 64 and IA-32 Intel Architecture Software Developer's Manual
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Agner Fog “Optimizing software in C++: An optimization guide for Windows, Linux and Mac platforms” http://www.agner.org/optimize/
Aart J.C. Bik “The Software Vectorization Handbook”
Richard Gerber, Aart J.C. Bik, Kevin B.Smith, Xinmin Tian “The Software Optimization Cookbook”
Intel® 64 and IA-32 Intel Architecture Software Developer's Manual
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Agner Fog “Optimizing software in C++: An optimization guide for Windows, Linux and Mac platforms” http://www.agner.org/optimize/







