- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Поисковая система и машинное обучение презентация
Содержание
- 1. Поисковая система и машинное обучение
- 2. Цели и вопросы Мои цели Переход из
- 3. Чего не будет Я не могу за
- 4. Как устроен поиск?
- 8. Ранжирование Ранжирование - процесс упорядочивания документов
- 9. Ранжирующие признаки Запросо-независимые или статические признаки
- 10. Как происходит поиск Запрос токенизируется, к словам
- 11. Общая функция релевантности Функция релевантности документа d
- 12. Качество поиска Ассесоры нужны не для ручного
- 13. Выводы Среднее по топу не всегда покажет
- 14. Ссылочный антиспам Вероятность что текст анкора коммерческий
- 15. Текстовый антиспам ПФ на странице с текстом
- 16. Поведенческие факторы и антиспам Поведение в топе
- 17. Тематические фичи Количество и частота новыйх объявлений
- 18. Про поиск и МО Антиспам построены на
- 19. Типы задач Классификация Кластеризация Регрессия Понижение
- 20. Класическая задача: Кредитный скоринг Объект - человек
- 21. Алгоритмы. Деревья решений
- 22. Random Forest
- 23. k-means
- 24. Коллаборативная фильтрация
- 25. МО для текстов Катеригоризация Кластеризация Таксономия Классификация
- 26. AlchemyLanguage API http://www.alchemyapi.com/products/demo/alchemylanguage
- 27. Классификация текстов http://docs.aylien.com/docs/addon-introduction
- 28. Пример. Как найти похожие документы Пацаны сказали
- 29. LSA? Как работает: удаление стоп-слов, стемминг или
- 30. LSA
- 31. Пример. Как найти похожие документы LSA:
- 32. Как найти схожие документы. Обучение. LDA Пример обучения: http://pastebin.com/PMrCAQpz
- 33. Мера схожести Косинусная мера Коэффициент корреляции
- 34. Пример работы
- 35. Gensim
- 36. Сложность фраз. Задача и ограничения Ограничения: Нужно
- 37. Сложность фразы. Параметры. SEO-score = вхождение
- 38. Сложность фраз Поиск признаков Разметили обучающую выборку
- 39. Сложность фразы
- 40. Полином fr(q,d)=a1h1(q,d)+a2h2(q,d)+...+an
- 41. Нормировка линейная
- 42. Апроксимация
- 43. Виды апроксимации
- 44. Итоговая формула score=af(тиц)+bf(pr)+cf(ВС)+d
- 45. Как найти коэффициенты a,b,c
- 46. Таблица для поиска коэффициентов
- 47. Поиск решения
- 48. Поиск решения
- 49. Конец)
- 50. Усовершенствованный алгоритм Выбираем параметры Нормируем Находим корреляцию
- 51. Реальный пример https://docs.google.com/spreadsheets/d/1KSXignNr7SvNGhUU0W_uWCaxp5Ka3ea1jHRiWQKOFrM/edit#gid=573531330
- 52. Рекомендации kime, rapidminer - комбайны Gensim -
- 53. Вопросы? CEO of Prodvigator Олег Саламаха Facebook www.prodvigator.ru

Слайд 2Цели и вопросы
Мои цели
Переход из мира магии в мир науки
Станет понятней
как работает алгоритмы поиска, мо и в какую сторону смотреть
Наконец-то узнать что LSA - это не частотный словарь)))
Накопление опыта
Наконец-то узнать что LSA - это не частотный словарь)))
Накопление опыта

Слайд 3Чего не будет
Я не могу за 2 часа сделать вас Data
Science спецами
Четких рецептов из мира магии
Ответов на вопросы: "Какое нужно количество вхождений", "Сколько нужно купить ссылок..." и т.д.
Мы сделали какую-то фигню, смотрите какой красивый график
Четких рецептов из мира магии
Ответов на вопросы: "Какое нужно количество вхождений", "Сколько нужно купить ссылок..." и т.д.
Мы сделали какую-то фигню, смотрите какой красивый график



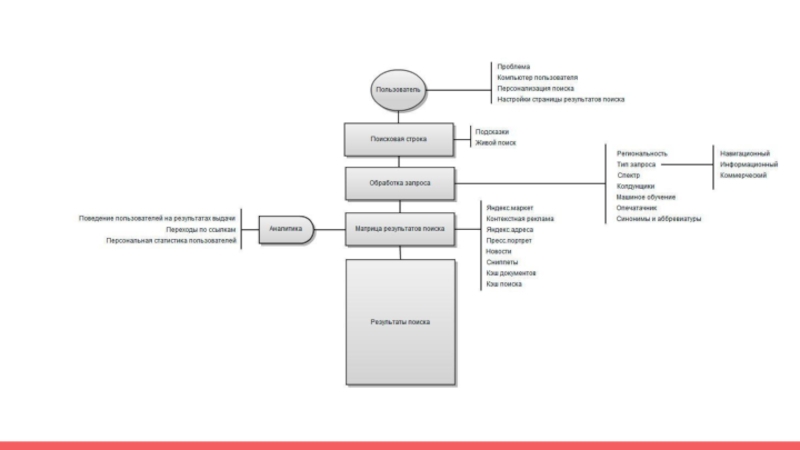
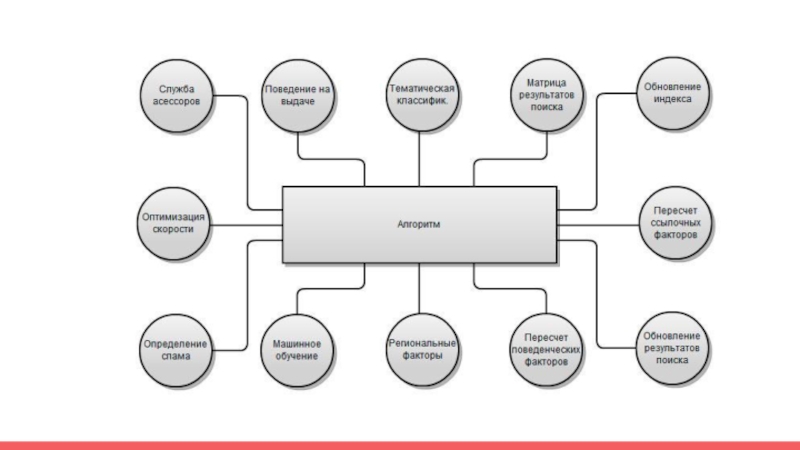
Слайд 8Ранжирование
Ранжирование - процесс упорядочивания документов в соответствии со степенью их
соответствия поисковому запросу.

Слайд 9Ранжирующие признаки
Запросо-независимые или статические признаки — зависящие только от документа, но
не от запроса. Например, PageRank или длина документа.
Признаки, зависящие только от запроса. Например, «запрос про порно или нет».
Запросо-зависимые или динамические признаки — зависящие и от документа, и от запроса. Например, TF-IDF.
Признаки, зависящие только от запроса. Например, «запрос про порно или нет».
Запросо-зависимые или динамические признаки — зависящие и от документа, и от запроса. Например, TF-IDF.

Слайд 10Как происходит поиск
Запрос токенизируется, к словам запроса применяется морфологический анализ, ищутся
синонимы
Из документов индекса отбираются те, которые с большой вероятностью отвечают на запрос
Для отфильтрованных документов рассчитываются признаки (фичи)
К признакам применяется формула, дающая конечную оценку релевантности
Из документов индекса отбираются те, которые с большой вероятностью отвечают на запрос
Для отфильтрованных документов рассчитываются признаки (фичи)
К признакам применяется формула, дающая конечную оценку релевантности

Слайд 11Общая функция релевантности
Функция релевантности документа d относительно запроса q
fr(q,d)=a1h1(q,d)+a2h2(q,d)+...+anhn(q,d)
количество функций hk(q,d)
достаточно большое, десятки тысяч. Коэффициенты ak – малые величины.
hk(q,d) - мономы факторов
hk(q,d) - мономы факторов
=a1h1(q,d)+a2h2(q,d)+...+anhn(q,d)количество функций hk(q,d) достаточно большое, десятки тысяч.")
Слайд 12Качество поиска
Ассесоры нужны не для ручного управления, а для оценки качества
алгоритма
Определяют фичи
Постоянное переобучение
Типы запросов и регионы
Определяют фичи
Постоянное переобучение
Типы запросов и регионы

Слайд 13Выводы
Среднее по топу не всегда покажет порог релевантности
Никто не знает
какие факторы как влияю на конкретный топ
Все факторы важны, один может помочь вытянуть другой
Нет смысла считать все факторы, если релевантных документов мало
Факторы дают + или - в ранжирование
Все факторы важны, один может помочь вытянуть другой
Нет смысла считать все факторы, если релевантных документов мало
Факторы дают + или - в ранжирование

Слайд 14Ссылочный антиспам
Вероятность что текст анкора коммерческий
Вероятность что сайт продает ссылки
Вероятность что
сайт покупает ссылки
Тематика дорона-акцептора
Длинна текста в блоке
и т.д.
Тематика дорона-акцептора
Длинна текста в блоке
и т.д.

Слайд 15Текстовый антиспам
ПФ на странице с текстом
Вероятность встретить слово в тексте
Тематический вектор
текста документа и сайта
Статические признаки спама(сжимаемость текста, количество знаков препинания и т.д)
Перечисление запросов и пр. фичи.
Статические признаки спама(сжимаемость текста, количество знаков препинания и т.д)
Перечисление запросов и пр. фичи.


Слайд 17Тематические фичи
Количество и частота новыйх объявлений - для класифайдов
Наличие интентов на
странице(купить, скачать и т.д.)
Общая релевантность сайта запросу
Для авто-сайтов не нужна кнопка "купить"
Общая релевантность сайта запросу
Для авто-сайтов не нужна кнопка "купить"
Общая")
Слайд 18Про поиск и МО
Антиспам построены на МО
У яндекса алгоритм ранжированя работает
на МО
Все задачи по кластеризации и классификации текстов - МО
Все задачи по кластеризации и классификации текстов - МО

Слайд 19Типы задач
Классификация
Кластеризация
Регрессия
Понижение размерности данных
Восстановление плотности распределения вероятности по набору данных
Одноклассовая
классификация и выявление новизны
Построение ранговых зависимостей

Слайд 20Класическая задача: Кредитный скоринг
Объект - человек
доход, есть квартира, есть жена у
которой есть машина и т.д. - признаки
Задача: Найти вероятность того что клиент вернет кредит.
Задача: Найти вероятность того что клиент вернет кредит.








Слайд 28Пример. Как найти похожие документы
Пацаны сказали что LSA - это круто.
(на самом деле нет, Дирихле - рулит)

Слайд 29LSA?
Как работает:
удаление стоп-слов, стемминг или лемматизация слов в документах;
исключение слов, встречающихся
в единственном экземпляре;
построение матрицы слово-документ (бинарную есть/нет слова, число вхождений или tf-idf);
разложение матрицы методом SVD (A = U * V * WT);
выделение строк матрицы U и столбцов W, которые соответствуют наибольшим сингулярным числам (их может быть от 2-х до минимума из числа терминов и документов). Конкретное количество учитываемых собственных чисел определяется предполагаемым количеством семантических тем в задаче.
построение матрицы слово-документ (бинарную есть/нет слова, число вхождений или tf-idf);
разложение матрицы методом SVD (A = U * V * WT);
выделение строк матрицы U и столбцов W, которые соответствуют наибольшим сингулярным числам (их может быть от 2-х до минимума из числа терминов и документов). Конкретное количество учитываемых собственных чисел определяется предполагаемым количеством семантических тем в задаче.


Слайд 31Пример. Как найти похожие документы
LSA:
На выходе получаем координаты в тематическом пространстве
LDA:
На
выходе получаем вероятность принадлежности слова к тематике, и тематики пренадлежащие документам


Слайд 33Мера схожести
Косинусная мера
Коэффициент корреляции Пирсона
Евклидово расстояние
Коэффициент Танимото
Манхэттенское расстояние и т.д.



Слайд 36Сложность фраз. Задача и ограничения
Ограничения:
Нужно посчитать за вменяемое время "сложность" для
~ 100 млн фраз.
Нельзя заходить на страницы
Нет ссылочного профиля
Задача: Найти переменную которая выражает сложность продвижения фразы.
Нельзя заходить на страницы
Нет ссылочного профиля
Задача: Найти переменную которая выражает сложность продвижения фразы.

Слайд 37Сложность фразы. Параметры.
SEO-score = вхождение фразы в разные участки снипета.
Вспомагательные параметры:
число главных страниц
число результатов в выдаче
длина фразы + число подсказок и запросов в базе
сила домена
частота запроса
стоимость клика в контексте
конкуренция в контексте
и т.д.

Слайд 38Сложность фраз
Поиск признаков
Разметили обучающую выборку
Отдельно обучили SEO-score
Нормализовали другие параметры и
обучили
Проверили результат на 2 выборках НК и ВК
Обучали пока небыло заметной разницы между НК и ВК
Еще раз проверили на другой группе
Проверили результат на 2 выборках НК и ВК
Обучали пока небыло заметной разницы между НК и ВК
Еще раз проверили на другой группе


=a1h1(q,d)+a2h2(q,d)+...+an")



+bf(pr)+cf(ВС)+d")




")
Слайд 50Усовершенствованный алгоритм
Выбираем параметры
Нормируем
Находим корреляцию с правильными результатами
Строим формулу
Помним про эффект переобучения

Слайд 51Реальный пример
https://docs.google.com/spreadsheets/d/1KSXignNr7SvNGhUU0W_uWCaxp5Ka3ea1jHRiWQKOFrM/edit#gid=573531330

Слайд 52Рекомендации
kime, rapidminer - комбайны
Gensim - библиотека python
SciPy - библиотека python
Национальный корпус
русского языка - http://www.ruscorpora.ru/
Обработка текста http://www.alchemyapi.com/products/demo/alchemylanguage
http://www.wordfrequency.info/ - ENG корпус
https://github.com/buriy/python-readability - очистка текстов
Обработка текста http://www.alchemyapi.com/products/demo/alchemylanguage
http://www.wordfrequency.info/ - ENG корпус
https://github.com/buriy/python-readability - очистка текстов







