- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Оптимизирующий компилятор.Автопараллелизация. презентация
Содержание
- 1. Оптимизирующий компилятор.Автопараллелизация.
- 2. Многоядерные/многопроцессорные Intel архитектуры Intel® Pentium®
- 3. Одной из главных особенностей многоядерной архитектуры
- 4. Классификация многопроцессорных систем по использованию памяти:
- 5. Intel QuickPath Architecture 10/17/10
- 6. 10/17/10 Нестабильность работы приложений на многопроцессорных машинах с неоднородным доступом к памяти.
- 7. Плюсы и минусы использования многопоточных приложений
- 8. Автоматическая параллелизация – это процесс автоматического
- 9. Выгодность автоматической параллелизации на простом примере
- 11. Хорошо и плохо масштабируемые алгоритмы. 10/17/10
- 12. Плохо масштабируемые алгоритмы: 10/17/10 void matrix_add(int
- 13. Допустимость автопараллелизации. Автопараллелизация – цикловая
- 14. Выгодность параллелизации /Qpar_report3 информирует, если
- 15. #pragma concurrent – игнорировать предполагаемые зависимости в
- 16. Автоматическая параллелизация осуществляется с использованием интерфейса
- 17. 10/17/10
- 18. Параллелизация цикла выглядит как создание функции
- 19. /Qpar-runtime-control[n] Control
- 20. Взаимодействие с другими цикловыми оптимизациями.
- 21. Предвыборка загрузка данных из относительно
- 22. DO I=1,N,SEC JJ=16 DO J=1,K
- 23. Софтварный префетч может быть полезен для
- 24. Использование ключей компилятора /Qopt-prefetch[:n]
- 25. CEAN (C/C++ Extensions for Array Notations
- 26. Декларация секций: section_operator :: =
- 27. Прототипы некоторых матричных функций: 10/17/10
- 28. #include #include #define N 2000
- 29. 10/17/10 Спасибо за внимание!

Слайд 2 Многоядерные/многопроцессорные Intel архитектуры
Intel® Pentium® Processor Extreme Edition (2005-2007)
Intel® Xeon® Processor 5100, 5300 Series
Intel® Core™2 Processor Family (2006-)
Появились двухпроцессорные архитектуры. Процессоры поддерхивают технологию четверного ядра (quad-core)
Intel® Xeon® Processor 5200, 5400, 7400 Series
Intel® Core™2 Processor Family (2007-)
Есть семейства в которых количество ядер на процессоре доведено до 6. 2-4 процессора.
Intel® Atom™ Processor Family (2008-)
Процессор с высокой энергоэффективностью.
Intel® Core™i7 Processor Family (2008-)
Hyperthreading технология. Cистема с неоднородным доступом в память.
10/17/10
 Представил технологию двойного ядра")
Слайд 3 Одной из главных особенностей многоядерной архитектуры является то, что ядра
10/17/10

Слайд 4 Классификация многопроцессорных систем по использованию памяти:
1.) Массивно-параллельные компьютеры или
Каждый процессор полностью автономен.
Существует некоторая коммуникационная среда.
Достоинства: хорошая масштабируемость
Недостатки: медленное межпроцедурное взаимодействие
2.) Системы с общей памятью (SMP системы)
Все процессоры равноудалены от памяти. Связь с памятью осуществляется через общую шину данных.
Достоинства: хорошее межпроцессорное взаимодействие
Недостатки: плохая масштабируемость
большие затраты на синхронизацию подсистем кэшей
3.) Системы с неоднородным доступом к памяти (NUMA)
Память физически распределена между процессорами. Единое адресное пространство поддерживается на аппаратном уровне.
Достоинства: хорошее межпроцессорное взаимодействие и масштабируемость
Недостатки: разное время доступа к разным сигментам памяти.
10/17/10
 Массивно-параллельные компьютеры или системы с распределенной памятью.")

Слайд 610/17/10
Нестабильность работы приложений на многопроцессорных машинах с неоднородным доступом к памяти.

Слайд 7 Плюсы и минусы использования многопоточных приложений
++:
Вычислительные ресурсы
--:
Усложнение разработки
Необходимость синхронизировать потоки
Потоки конкурируют за ресурсы
Создание потоков имеет свою цену
Вывод: В случае разработки бизнес-приложений четко осознавайте цели и цену распараллеливания вашей программы.
10/17/10

Слайд 8
Автоматическая параллелизация – это процесс автоматического преобразования последовательного программного кода в
/Qparallel
enable the auto-parallelizer to generate multi-threaded code for
loops that can be safely executed in parallel
 код для")
Слайд 9 Выгодность автоматической параллелизации на простом примере
REAL :: a(1000,1000),b(1000,1000),c(1000,1000)
integer i,j,rep_factor
DO I=1,1000
DO J=1,1000
A(J,I) = I
B(J,I) = I+J
C(J,I) = 0
END DO
END DO
DO rep_factor=1,1000
C=B/A+rep_factor
END DO
END
10/17/10
,b(1000,1000),c(1000,1000)integer i,j,rep_factor")
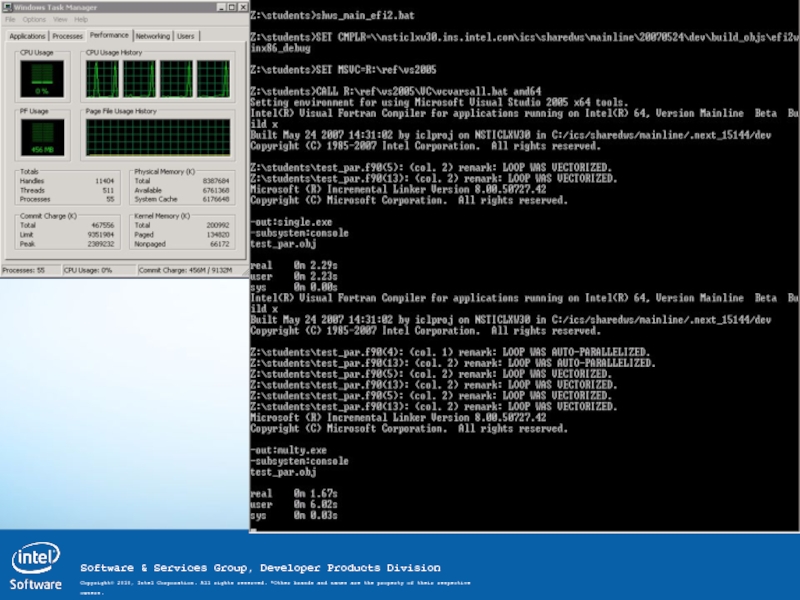
Слайд 11 Хорошо и плохо масштабируемые алгоритмы.
10/17/10
void matrix_mul_matrix(int n,
float C[n][n], float A[n][n],
float
int i,j,k;
for (i=0; i
for(k=0;k
}
}
 { int i,j,k; for (i=0; i")
Слайд 12 Плохо масштабируемые алгоритмы:
10/17/10
void matrix_add(int n, float Res[n][n],float A1[n][n], float A2[n][n],
float
float A7[n][n], float A8[n][n]) {
int i,j;
for (i=0; i
A5[i][j]+A6[i][j]+A7[i][j]+A8[i][j]+
A1[i][j+1]+A2[i][j+1]+A3[i][j+1]+A4[i][j+1]+
A5[i][j+1]+A6[i][j+1]+A7[i][j+1]+A8[i][j+1];
}

Слайд 13 Допустимость автопараллелизации.
Автопараллелизация – цикловая перестановочная оптимизация.
Упорядоченное выполнение итераций
Необходимое условие – отсутствие любых зависимостей внутри цикла.
/Qpar-report{0|1|2|3}
control the auto-parallelizer diagnostic level
/Qpar-report3 сообщает причины по которым компилятор не параллелизует тот или иной цикл, в том числе сообщает какие зависимости препятствуют автопараллелизации.
10/17/10

Слайд 14 Выгодность параллелизации
/Qpar_report3 информирует, если параллелизация невыгодна
C:\test_par.c(27) (col. 1):
Точное определение выгодности автопараллелизации во время компиляции достаточно тяжелая задача.
Существуют эффекты производительности, которые сложно оценить, например «эффект первого прикосновения».
В большинстве случаев компилятор может не иметь представления о количестве итераций в цикле.
Используйте директивы параллелизации при экспериментах с производительностью.
10/17/10
 (col. 1): remark: loop was not")
Слайд 15#pragma concurrent – игнорировать предполагаемые зависимости в следующем цикле
#pragma concurrent
#pragma concurrentize – параллелизовать следующий цикл
#pragma no concurrentize - не параллелизовать следующий цикл
#pragma prefer concurrent параллелизовать следующий цикл, если это безопасно
#pragma prefer serial – предложить компилятору не параллелизовать следующий цикл
#pragma serial – заставить компилятор параллелизовать следующий цикл

Слайд 16 Автоматическая параллелизация осуществляется с использованием интерфейса OpenMP.
OpenMP (Open Multi-Processing) –
Количество потоков, используемых вашим приложением, может изменяться с помощью установки переменной окружения OMP_NUM_THREADS
(по умолчанию будут использоваться все доступные ядра)
8 Threads
16 Threads
 – это программный интерфейс, который")

Слайд 18 Параллелизация цикла выглядит как создание функции в которую в качестве
Запускаются несколько экземпляров данной функции в разных потоках с различными значениями границ цикла.
Т.е. итерационное пространство цикла разбивается на несколько частей и каждый поток обрабатывает свою часть итерационного пространства.

Слайд 19/Qpar-runtime-control[n]
Control parallelizer to generate runtime check
automatic parallelization.
n=0 no runtime check based auto-parallelization
n=1 generate runtime check code under conservative mode
(DEFAULT when enabled)
n=2 generate runtime check code under heuristic mode
n=3 generate runtime check code under aggressive mode
10/17/10

Слайд 20 Взаимодействие с другими цикловыми оптимизациями.
Объединение циклов и создание больших
Автопараллелизация.
Оптимизация цикла в поточной функции в соответствии с обычными соображениями. (развертка, векторизация, разбиение на несколько циклов и т.п.)
Эти соображения можно использовать при написании программы. Стремитесь создавать большие циклы без зависимостей, т.е. такие чтобы итерации могли выполняться в произвольном порядке.
10/17/10

Слайд 21 Предвыборка
загрузка данных из относительно медленной памяти в кэш до
Существуют несколько методов использования этой техники для оптимизации приложения:
Использование интринсиков
Использование компиляторной опции
Интринсик предвыборки определен в xmmintrin.h и имеет форму
#include
enum _mm_hint { _MM_HINT_T0 = 3, (L1)
_MM_HINT_T1 = 2, (L2)
_MM_HINT_T2 = 1, (L3)
_MM_HINT_NTA = 0 };
void _mm_prefetch(void *p, enum _mm_hint h);
Он подгружает в кэш кэш-линию начиная с указанного адреса (размер кэш линии 64 байта)
В случае с Фортраном используется вызов CALL mm_prefetch(P,HINT)
10/17/10

Слайд 22DO I=1,N,SEC
JJ=16
DO J=1,K
A(J,I) = A(J,I)+B(J,I)+C(J,I)
#ifdef PERF
CALL mm_prefetch(A(J,I+SEC),1)
CALL mm_prefetch(B(J,I+SEC),1)
CALL mm_prefetch(C(J,I+SEC),1)
JJ = 0
ENDIF
#endif
JJ=JJ+1
END DO
END DO
10/17/10
Пример использования
 = A(J,I)+B(J,I)+C(J,I)#ifdef PERF IF(JJ==16) THEN CALL mm_prefetch(A(J,I+SEC),1)")
Слайд 23 Софтварный префетч может быть полезен для решения проблем типичного C++
10/17/10

Слайд 24 Использование ключей компилятора
/Qopt-prefetch[:n]
enable levels of
n may be 0 through 4 inclusive. Default is 2.
/Qopt-prefetch-
disable(DEFAULT) prefetch insertion. Equivalent to /Qopt-prefetch:0
10/17/10

 Декларация массивов:10/17/10")
Слайд 26 Декларация секций:
section_operator :: = [::
a[0:3][0:4]
b[0:2:3]
Вы
Пример декларации массива и использования секции:
typedef int (*p2d)[128];
p2d p = (p2d) malloc (sizeof(int)*rows*128);
p[0:rows][:]
Большинство C/C++ операторов доступны для работы с секциями.
a[:]*b[:] // поэлементное умножение
a[3:2][2:2] + b[5:2][5:2] // сложение матриц
a[0:4]+c // добавление скаляра к вектору
a[:][:] = b[:][1][:] + c // матричное присвоение
10/17/10


Слайд 28#include
#include
#define N 2000
typedef double (*p2d)[];
void matrix_mul(int n, double a[n][n],
double b[n][n],double c[n][n]) {
int i,j;
a[:][:] =1;
b[:][:] =-1;
for(i=0;i
__sec_reduce_add(a[i][:]*b[:][j]);
return;
}
10/17/10
int main() {
p2d a= (p2d)malloc(N*N*sizeof(double)) ;
p2d b= (p2d)malloc(N*N*sizeof(double)) ;
p2d c= (p2d)malloc(N*N*sizeof(double));
matrix_mul(N,a,a,a);
matrix_mul(N,a,b,c);
free(a);
free(b);
free(c);
}
[];void matrix_mul(int n, double a[n][n], double b[n][n],double")






