- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Извлечение информации из полуструктурированных веб-источников презентация
Содержание
- 1. Извлечение информации из полуструктурированных веб-источников
- 2. План Мотивация; Направления Web Mining; Отбор источников
- 3. План Мотивация; Направления Web Mining; Отбор источников
- 4. Структурированная информация в веб-источниках, как правило, содержит
- 5. Мотивация: пример
- 6. Мотивация: способ решения Извлечение структурированных данных из
- 7. Знаешь, что такое Web Mining?
- 8. План Мотивация; Направления Web Mining; Отбор источников
- 9. Направления Web Mining 1996 Web
- 10. Направления Web Mining 1996 1997 Web
- 11. Направления Web Mining 1996 1997 1999 Web
- 12. Направления Web Mining: Характеристика Web
- 13. Задачи Web Content Mining Извлечение структурированной информации;
- 14. «Георгий Иванович, он же Жора, он же
- 15. Задачи Web Content Mining Извлечение структуриро- ванных данных Извлечение фактов и отношений
- 16. Задачи Web Content Mining Свободный текст
- 17. План Мотивация; Направления Web Mining; Отбор источников
- 18. Конференции Computer Science Conference Ranking
- 19. Критерии отбора статей Престижность конференции; Год публикации; Индекс цитируемости; «Серийные» авторы.
- 20. «Серийные» авторы Bing, Liu Professor University
- 21. Исследовательские центры на карте мира
- 22. План Мотивация; Направления Web Mining; Отбор источников
- 23. Данные в Веб Виды данных: текст, графика, аудио, видео.
- 24. Данные в Веб Виды данных: текст, графика,
- 25. Данные в Веб Виды данных: текст, графика,
- 26. План Мотивация; Направления Web Mining; Отбор источников
- 27. Основные этапы процесса Crawling Построение wrapper-ов Извлечение данных Анализ данных
- 28. Основные этапы процесса Crawling Построение wrapper-ов Извлечение данных Анализ данных
- 29. «Георгий Иванович, он же Жора, он же
- 30. «Георгий Иванович, он же Жора, он же
- 31. План Мотивация; Направления Web Mining; Отбор источников
- 32. Wrapper Induction System Классификация методов [Chang2006]
- 33. Manual | Supervised | Semi-supervised | Un-supervised
- 34. Manual | Supervised | Semi-supervised | Un-supervised
- 35. Manual | Supervised | Semi-supervised | Un-supervised
- 36. Manual | Supervised | Semi-supervised | Un-supervised
- 37. План Мотивация; Направления Web Mining; Отбор источников
- 38. Существующие подходы
- 39. Примеры существующих подходов и систем Группа «Manual»; Группы «Supervised» и «Semi-supervised»; Группа «Unsupervised»;
- 40. Примеры существующих подходов и систем Группа «Manual»; Группы «Supervised» и «Semi-supervised»; Группа «Unsupervised»;
- 41. Группа «Manual» Особенности: Wrapperы пишутся вручную; Для разбора используют Xpath; RegExp.
- 42. Flashback: Существующие подходы
- 43. Группа «Manual»: Инструменты http://web-harvest.sourceforge.net/
- 44. WebHarvest: Easy Web Scraping from Java
- 45. Manual. Инструменты http://web-harvest.sourceforge.net/ http://scrapy.org/
- 46. Таких инструментов много 30 Digits Web
- 47. Примеры существующих подходов и систем Группа «Manual»; Группы «Supervised» и «Semi-supervised»; Группа «Unsupervised».
- 48. Группы «Supervised» и «Semi-supervised» Особенность: Правила извлечения генерируются автоматически или под контролем пользователя.
- 49. Flashback: Существующие подходы
- 50. Группы «Supervised» и «Semi-supervised»: Инструменты http://www.visualwebripper.com/
- 52. Группы «Supervised» и «Semi-supervised» Инструменты http://www.visualwebripper.com/ http://www.lixto.com/ http://www.denodo.com
- 53. Примеры существующих подходов и систем Группа «Manual»; Группы «Supervised» и «Semi-supervised»; Группа «Unsupervised»
- 54. Группа «Unsupervised» Особенности: Полностью автоматические. не требуют контроля со стороны пользователя.
- 55. Flashback: Существующие подходы
- 56. Flashback: Исследовательские центры на карте мира
- 57. Flashback: Исследовательские центры на карте мира
- 58. Crescenzi et al. Организации: Università
- 59. Crescenzi et al: RoadRunner Дано множество «хороших»
- 64. Crescenzi et al: RoadRunner. Пример
- 65. Flashback: Исследовательские центры на карте мира
- 66. Flashback: Исследовательские центры на карте мира
- 67. Liu et al. Организации: University of
- 68. Liu et al: Mining Data Records (MDR)
- 69. Liu et al: MDR. Пример
- 70. Liu et al: MDR. Пример
- 71. Liu et al: MDR. Пример
- 72. Flashback: Исследовательские центры на карте мира
- 73. Flashback: Исследовательские центры на карте мира
- 74. Microsoft Research Asia Направление исследования: Сегментация страницы;
- 75. Microsoft Research Asia: Vision-based Page Segmentation Algorithm (VIPS)
- 76. Microsoft Research Asia: Vision-based Page Segmentation Algorithm (VIPS)
- 77. План Мотивация; Направления Web Mining; Отбор источников
- 78. Заключение Сложности Manual -Свой на каждый сайт;
- 79. Заключение Автоматизация: От ручной обработки через полностью
- 80. Спасибо за внимание! Вопросы?
- 81. Евгения Яковлева ragvena@yandex-mail.ru Владимир Батыгин vbatygin@yandex-team.ru mining-research@yandex-team.ru
Слайд 1Извлечение информации из полуструктурированных
веб-источников
Евгения Яковлева
ragvena@yandex-mail.ru
Владимир Батыгин
vbatygin@yandex-team.ru

Слайд 2План
Мотивация;
Направления Web Mining;
Отбор источников информации;
Извлечение структурированной информации
Основные этапы процесса,
Классификация методов,
Примеры существующих
Заключение.

Слайд 3План
Мотивация;
Направления Web Mining;
Отбор источников информации;
Извлечение структурированной информации
Основные этапы процесса,
Классификация методов,
Примеры существующих
Заключение.

Слайд 4Структурированная информация в веб-источниках, как правило, содержит полезную информацию.
Анализ контента
Мотивация


Слайд 6Мотивация: способ решения
Извлечение структурированных данных из веб-источников является задачей Web Content
Web Content Mining – направление Web Mining, занимающееся извлечением полезной информации из веб-страниц.
. Web Content Mining –")

Слайд 8План
Мотивация;
Направления Web Mining;
Отбор источников информации;
Извлечение структурированной информации
Основные этапы процесса,
Классификация методов,
Примеры существующих
Заключение.

Слайд 9Направления Web Mining
1996
Web Mining
«The World-Wide Web: quagmire or gold mine?»
Professor
Oren
Director of the Turing Center


Слайд 11Направления Web Mining
1996
1997
1999
Web Mining
Web Content Mining
Web Content Mining
Web Structure Mining
Web Usage
Web Usage Mining

Слайд 12Направления Web Mining: Характеристика
Web Usage Mining
Логи веб-серверов;
Предпочтений посетителей.
Web Structure
Ссылки
Взаимосвязь между страницами
Web Content Mining
HTML-страницы;
Информация и знания.

Слайд 13Задачи Web Content Mining
Извлечение структурированной информации;
Извлечение фактов и связей.
Построение баз знаний,
PROSPERA.
Послать
Извлечение структурированной информации
Извлечение фактов и отношений

Слайд 14«Георгий Иванович, он же Жора, он же Гоша, он же Гога…»
Web
Web Scraping
Web Data Extraction
Information Extraction
Web Content Mining
Wrapper Induction


Слайд 16Задачи Web Content Mining
Свободный текст
Gerhard Weikum
Max Planck Institute for Informatics
«Scalable knowledge
PROSPERA
Oren Etzioni
University of Washington
KnowItAll [2004]

Слайд 17План
Мотивация;
Направления Web Mining;
Отбор источников информации;
Извлечение структурированной информации
Основные этапы процесса,
Классификация методов,
Примеры существующих
Заключение.


Слайд 19Критерии отбора статей
Престижность конференции;
Год публикации;
Индекс цитируемости;
«Серийные» авторы.

Слайд 20«Серийные» авторы
Bing, Liu
Professor
University of Illinois at Chicago (UIC)
WONG, Tak-Lam
PhD,Lecturer
The Hong Kong
Chang, Chia-Hui
Professor
National Central University
 WONG, Tak-LamPhD,Lecturer The Hong Kong Institute of")

Слайд 22План
Мотивация;
Направления Web Mining;
Отбор источников информации;
Извлечение структурированной информации
Основные этапы процесса,
Классификация методов,
Примеры существующих
Заключение.


Слайд 24Данные в Веб
Виды данных: текст, графика, аудио, видео.
Текстовая информация:
Неструктурированная
свободный текст;
Полуструктурированная
HTML-страницы;
Структурированная
документы, генерирующиеся

Слайд 25Данные в Веб
Виды данных: текст, графика, аудио, видео.
Текстовая информация:
Неструктурированная
свободный текст;
Полуструктурированная
HTML-страницы;
Структурированная
документы, генерирующиеся

Слайд 26План
Мотивация;
Направления Web Mining;
Отбор источников информации;
Извлечение структурированной информации
Основные этапы процесса,
Классификация методов,
Примеры существующих
Заключение.



Слайд 29«Георгий Иванович, он же Жора, он же Гоша, он же Гога…»-2
«То,
Wrapper
Правила извлечения
Parser
Pattern
Спец. робот
Экстрактор
Посредник между исходными и извлеченными данными

Слайд 30«Георгий Иванович, он же Жора, он же Гоша, он же Гога…»-2
«То,
Wrapper
Правила извлечения
Parser
Pattern
Спец. робот
Экстрактор
Посредник между исходными и извлеченными данными
Строится заново для каждой страницы и не использует знаний о структуре ранее обработанных страниц
Строится на этапе обучения и использует знания о строе предыдущих страниц

Слайд 31План
Мотивация;
Направления Web Mining;
Отбор источников информации;
Извлечение структурированной информации
Основные этапы процесса,
Классификация методов,
Примеры существующих
Заключение.

Слайд 32
Wrapper Induction System
Классификация методов [Chang2006]
Wrapper
Extracted Data
Test Page
Un-labeled Training Web Pages

Слайд 33Manual | Supervised | Semi-supervised | Un-supervised
Wrapper Induction System
Классификация методов [Chang2006]
Wrapper
Extracted
Test Page
Un-labeled Training Web Pages
Manual

Слайд 34Manual | Supervised | Semi-supervised | Un-supervised
Wrapper Induction System
Классификация методов [Chang2006]
Wrapper
Extracted
Test Page
Un-labeled Training Web Pages
Supervised
Labeled Web Pages

Слайд 35Manual | Supervised | Semi-supervised | Un-supervised
Wrapper Induction System
Классификация методов [Chang2006]
Wrapper
Extracted
Test Page
Un-labeled Training Web Pages
Semi-supervised

Слайд 36Manual | Supervised | Semi-supervised | Un-supervised
Wrapper Induction System
Классификация методов [Chang2006]
Wrapper
Extracted
Test Page
Un-labeled Training Web Pages
Unsupervised

Слайд 37План
Мотивация;
Направления Web Mining;
Отбор источников информации;
Извлечение структурированной информации
Основные этапы процесса,
Классификация методов,
Примеры существующих
Заключение.


Слайд 39Примеры существующих подходов и систем
Группа «Manual»;
Группы «Supervised» и «Semi-supervised»;
Группа «Unsupervised»;

Слайд 40Примеры существующих подходов и систем
Группа «Manual»;
Группы «Supervised» и «Semi-supervised»;
Группа «Unsupervised»;






Слайд 46Таких инструментов много
30 Digits Web Extractor Software
Djuggler
Happy Harvester
Irobot Soft
ListGrabber
http://www.theeasybee.com/

Слайд 47Примеры существующих подходов и систем
Группа «Manual»;
Группы «Supervised» и «Semi-supervised»;
Группа «Unsupervised».

Слайд 48Группы «Supervised» и «Semi-supervised»
Особенность:
Правила извлечения генерируются автоматически или под контролем пользователя.



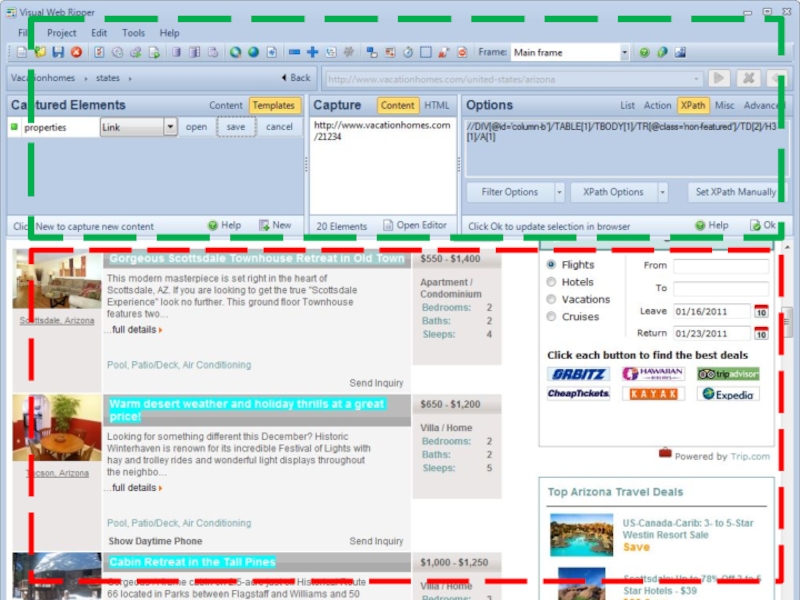
Слайд 52Группы «Supervised» и «Semi-supervised» Инструменты
http://www.visualwebripper.com/
http://www.lixto.com/
http://www.denodo.com

Слайд 53Примеры существующих подходов и систем
Группа «Manual»;
Группы «Supervised» и «Semi-supervised»;
Группа «Unsupervised»

Слайд 54Группа «Unsupervised»
Особенности:
Полностью автоматические.
не требуют контроля со
стороны пользователя.




Слайд 58Crescenzi et al.
Организации:
Università di Roma Tre,
Università della Basilicata;
Направление исследования:
Автоматическая экстракция .
Работы:
RoadRunner[2001];
Flint[2008];
Automatically

Слайд 59Crescenzi et al: RoadRunner
Дано множество «хороших» страниц;
Строится wrapper в форме RegExp.
Подход
Wrapper


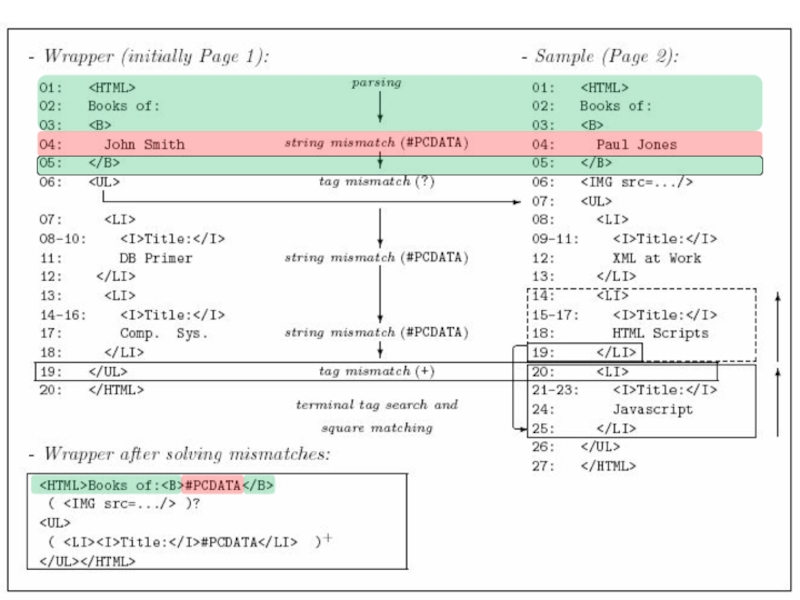
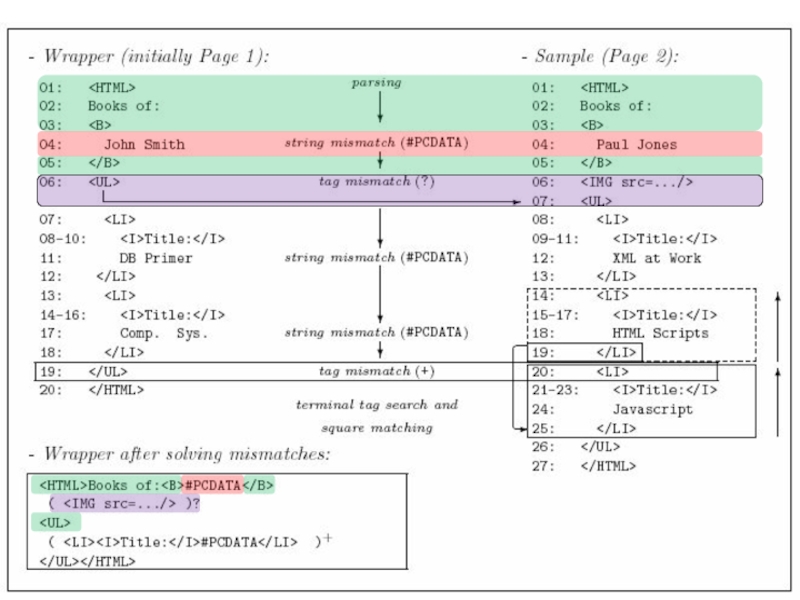




Слайд 67Liu et al.
Организации:
University of Illinois at Chicago.
Направление исследования:
Очистка страниц от
Автоматическая экстракция данных из каталожных страниц.
Работы:
Web Page Cleaning for Web Mining through Feature Weighting [2003];
MDR[2003] DEPTA[2005] NET[2005];

 Data RegionData Reсord")





Слайд 74Microsoft Research Asia
Направление исследования:
Сегментация страницы;
Извлечение информации;
Вероятностные модели для извлечения информации.
Работы:
VIPS: a
2d conditional random fields for web information extraction[2005];
Simultaneous record detection and attribute labeling in web data extraction [2006];

")
")
Слайд 77План
Мотивация;
Направления Web Mining;
Отбор источников информации;
Извлечение структурированной информации
Основные этапы процесса,
Классификация методов,
Примеры существующих
Заключение.

Слайд 78Заключение
Сложности
Manual
-Свой на каждый сайт;
Supervised, Semi-supervised
Дорого поддерживать;
Unsupervised
Проблема с полнотой;

Слайд 79Заключение
Автоматизация:
От ручной обработки через полностью автоматическую к гибридной.
Уровень решения задачи:
от страницы
Используемые параметры:
От тегов к использованию визуальных особенностей оформления и контекста.


Слайд 81Евгения Яковлева
ragvena@yandex-mail.ru
Владимир Батыгин
vbatygin@yandex-team.ru
mining-research@yandex-team.ru






