модель баз данных.
Программно-аппаратный уровень процесса накопления данных (СУБД).
- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Информационный процесс накопления данных презентация
Содержание
- 1. Информационный процесс накопления данных
- 2. Информационная сущность накопления данных. Назначение процесса накопления
- 3. Информационный фонд систем управления должен формироваться на
- 4. Входные данные - это данные, получаемые из
- 5. Структурная схема жизненного цикла существования данных Процедуры
- 6. Процедура хранения состоит в том, чтобы сформировать
- 7. Процедура актуализации данных позволяет изменить значения данных,
- 8. 2. Выбор хранимых данных. Информационный фонд системы
- 9. Необходимо провести анализ информационных потоков в системе
- 10. От канонической структуры переходят к логической структуре
- 11. 3. Базы данных. База данных (БД)
- 12. Независимость данных и использующих их
- 13. Существуют три основных модели баз данных:
- 14. Например необходимо разработать логическую структуру БД для
- 15. Иерархическая модель представляется в виде древовидного
- 16. Сетевая модель БД Сетевая модель БД хороша
- 17. Реляционная модель баз данных реализует табличный способ.
- 18. Отношения обладают следующими свойствами: каждый элемент
- 19. Преимущества реляционной модели баз данных: Простота логической
- 20. При работе с реляционными моделями используется
- 21. Реляционная модель БД имеет дело с тремя
- 22. Структура базы данных определяет методы занесения данных
- 23. Реляционная алгебра Виды действий (манипуляций) над данными
- 24. Диаграммы традиционных теоретико-множественных операций
- 25. Операция пересечения. Пересечением двух отношений A
- 26. Операция объединение. Объединением двух отношений (таблиц)
- 27. Операция разность. Разностью между двумя отношениями A
- 28. Операция декартово произведение. Декартовым произведением двух
- 29. Вторая группа - специальные реляционные операции. Диаграммы специальных реляционных операций
- 30. Операция селекция. Операция селекции позволяет получать
- 31. Операция проекция Операция проекция позволяет получить
- 32. Из восьми рассмотренных реляционных операций пять являются
- 33. Операции реляционной модели данных представляют возможность произвольно
- 34. ПРОГРАММНО – АППАРАТНЫЙ УРОВЕНЬ ПРОЦЕССА НАКОПЛЕНИЯ ДАННЫХ
- 35. Состав моделей и программ процесса накопления
- 36. Каноническая структура БД создается с помощью модели
- 37. Переход к физической модели базы данных, реализуемой
- 38. Современная СУБД содержит в своем составе программные
- 39. С помощью средств создания БД проектировщик, используя
- 40. СУБД – программный комплекс поддержки интегрированной совокупности
- 42. Система управления базами данных - комплекс программных
- 43. ОСНОВНЫЕ ПОНЯТИЯ СУБД Если в
- 44. Обычно с БД работают две категории исполнителей:
- 45. ОБЪЕКТЫ БАЗЫ ДАННЫХ Таблицы – основные
- 46. ЗАПРОСЫ И ФОРМЫ Запросы – служат
- 48. Упрощенная схема работы с базой данных
- 49. Схема обработки данных с помощью СУБД.
- 50. ВИДЫ СУБД СУБД принципиально различаются по
- 51. По способу доступа к БД Файл-серверные В
- 52. Клиент-серверные Клиент-серверная СУБД располагается на сервере вместе
- 53. СУБД реализует следующие основные функции
- 54. СУБД реализует следующие основные функции низкого
- 55. Выделяют следующие основные функции СУБД. · Непосредственное
- 56. ·Управление транзакциями Транзакция - это последовательность операций
- 57. Журнализация Одним из основных требований к СУБД
- 58. ·Поддержка языков БД Для работы с базами
- 60. Компоненты типичной СУБД
- 61. Средства работы с данными предназначены для пользователя
- 62. СУБД принципиально различаются по моделям БД, с
- 63. В информационном процессе накопления данных наибольший вес
Слайд 1Информационный процесс накопления данных
Информационная сущность накопления данных.
Выбор хранимых данных.
Модели баз данных.
Реляционная

Слайд 2Информационная сущность накопления данных.
Назначение процесса накопления данных состоит в создании, хранении
и поддержании в актуальном состоянии информационного фонда, необходимого для выполнения функциональных задач системы управления, для которой применяется ИТ.
Состав процедур процесса накопления данных
Состав процедур процесса накопления данных
Накопление данных
Выбор хранимых данных
Хранение
Актуализация
Извлечение

Слайд 3Информационный фонд систем управления должен формироваться на основе принципов необходимой полноты
и минимальной избыточности хранимой информации.
Эти принципы реализуются процедурой выбора хранимых данных, в процессе выполнения которой производится анализ циркулирующих в системе данных и на основе их группировки на входные, промежуточные и выходные, определяется состав хранимых данных.
Эти принципы реализуются процедурой выбора хранимых данных, в процессе выполнения которой производится анализ циркулирующих в системе данных и на основе их группировки на входные, промежуточные и выходные, определяется состав хранимых данных.

Слайд 4Входные данные - это данные, получаемые из первичной информации и создающие
информационный образ предметной области.
Промежуточные данные - это данные, формирующиеся из других данных при алгоритмических преобразованиях. Как правило, они не хранятся, но накладывают ограничения на емкость оперативной памяти компьютера.
Выходные данные являются результатом обработки первичных (входных) данных по соответствующей модели, входят в состав управляющего информационного потока своего уровня и подлежат хранению в определенном временном интервале.
Промежуточные данные - это данные, формирующиеся из других данных при алгоритмических преобразованиях. Как правило, они не хранятся, но накладывают ограничения на емкость оперативной памяти компьютера.
Выходные данные являются результатом обработки первичных (входных) данных по соответствующей модели, входят в состав управляющего информационного потока своего уровня и подлежат хранению в определенном временном интервале.

Слайд 5Структурная схема жизненного цикла существования данных
Процедуры хранения, актуализации и извлечения данных
должны периодически сопровождаться оценкой необходимости их хранения, так как данные подвержены старению. Устаревшие данные должны быть удалены.

Слайд 6Процедура хранения состоит в том, чтобы сформировать и поддерживать структуру хранения
данных в памяти ЭВМ.
Современные структуры хранения данных должны быть независимы от программ, использующих эти данные и реализовывать вышеуказанные принципы (полнота и минимальная избыточность). Такие структуры получили название баз данных (БД).
Осуществление процедур создания структуры хранения (базы данных), актуализация, извлечение и удаление данных производится с помощью специальных программ, называемых системами управления базами данных (СУБД).
Современные структуры хранения данных должны быть независимы от программ, использующих эти данные и реализовывать вышеуказанные принципы (полнота и минимальная избыточность). Такие структуры получили название баз данных (БД).
Осуществление процедур создания структуры хранения (базы данных), актуализация, извлечение и удаление данных производится с помощью специальных программ, называемых системами управления базами данных (СУБД).

Слайд 7Процедура актуализации данных позволяет изменить значения данных, записанных в базе, либо
дополнить определенный раздел, группу данных. Устаревшие данные могут быть удалены с помощью соответствующей операции.
Процедура извлечения данных необходима для пересылки из базы данных требующихся данных либо для преобразования, либо для отображения, либо для передачи по вычислительной сети.
При выполнении процедур актуализации и извлечения обязательно выполняются операции поиска данных по заданным признакам и их сортировки, состоящие в изменении порядка расположения данных при хранении или извлечении.
Процедура извлечения данных необходима для пересылки из базы данных требующихся данных либо для преобразования, либо для отображения, либо для передачи по вычислительной сети.
При выполнении процедур актуализации и извлечения обязательно выполняются операции поиска данных по заданным признакам и их сортировки, состоящие в изменении порядка расположения данных при хранении или извлечении.

Слайд 82. Выбор хранимых данных.
Информационный фонд системы управления должен обеспечивать получение выходных
данных из входных с помощью алгоритмов обработки и корректировки данных.
Сначала создается инфологическая (концептуальная) модель предметной области - описание предметной области без ориентации на используемые в дальнейшем программные и технические средства.
Однако, для построения информационной базы инфологической модели не достаточно.
Сначала создается инфологическая (концептуальная) модель предметной области - описание предметной области без ориентации на используемые в дальнейшем программные и технические средства.
Однако, для построения информационной базы инфологической модели не достаточно.

Слайд 9Необходимо провести анализ информационных потоков в системе с целью установления связи
между элементами данных, их группировки в наборы входных, промежуточных и выходных элементов данных, исключения избыточных связей и элементов данных.
Получаемая в результате такого анализа безызбыточная структура носит название канонической структуры информационной базы.
Выделение наборов элементов данных по уровням позволяет объединить множество значений конечных элементов в логические записи и тем самым упорядочить их в памяти ЭВМ.
Получаемая в результате такого анализа безызбыточная структура носит название канонической структуры информационной базы.
Выделение наборов элементов данных по уровням позволяет объединить множество значений конечных элементов в логические записи и тем самым упорядочить их в памяти ЭВМ.

Слайд 10От канонической структуры переходят к логической структуре информационной базы, а затем
- к физической организации информационных массивов.
Процедуры хранения, актуализации и извлечения данных непосредственно связаны с базами данных, поэтому логический уровень этих процедур определяется моделями баз данных.
Процедуры хранения, актуализации и извлечения данных непосредственно связаны с базами данных, поэтому логический уровень этих процедур определяется моделями баз данных.

Слайд 113. Базы данных.
База данных (БД) определяется как совокупность взаимосвязанных данных,
характеризующихся:
возможностью использования для большого количества приложений;
возможностью быстрого получения и модификации необходимой информации;
минимальной избыточностью информации;
независимостью от прикладных программ; общим управляемым способом поиска.
возможностью использования для большого количества приложений;
возможностью быстрого получения и модификации необходимой информации;
минимальной избыточностью информации;
независимостью от прикладных программ; общим управляемым способом поиска.
 определяется как совокупность взаимосвязанных данных, характеризующихся: возможностью использования для")
Слайд 12
Независимость данных и использующих их программ является основным свойством баз
данных.
Независимость данных подразумевает, что изменение данных не приводит к изменению прикладных программ и наоборот.
Модели баз данных базируются на современном подходе к обработке информации, состоящем в том, что структуры данных обладают относительной устойчивостью.
Независимость данных подразумевает, что изменение данных не приводит к изменению прикладных программ и наоборот.
Модели баз данных базируются на современном подходе к обработке информации, состоящем в том, что структуры данных обладают относительной устойчивостью.

Слайд 13Существуют три основных модели баз данных:
иерархическая,
сетевая
реляционная.
Например, необходимо разработать
логическую структуру БД для хранения данных о трёх поставщиках - П1, П2, П3, которые могут поставлять товары - Т1, Т2, Т3 в следующих комбинациях:
Поставщик П1 все три вида товара (Т1,Т2,Т3).
Поставщик П2 – товары Т1 и Т3.
Поставщик П3 – товары Т2 и Т3.
Поставщик П1 все три вида товара (Т1,Т2,Т3).
Поставщик П2 – товары Т1 и Т3.
Поставщик П3 – товары Т2 и Т3.

Слайд 14Например необходимо разработать логическую структуру БД для хранения данных о трёх
поставщиках - П1, П2, П3, которые могут поставлять товары - Т1, Т2, Т3 в следующих комбинациях:
Поставщик П1 все три вида товара (Т1,Т2,Т3).
Поставщик П2 – товары Т1 и Т3.
Поставщик П3 – товары Т2 и Т3.
Поставщик П1 все три вида товара (Т1,Т2,Т3).
Поставщик П2 – товары Т1 и Т3.
Поставщик П3 – товары Т2 и Т3.

Слайд 15 Иерархическая модель представляется в виде древовидного графа, в котором объекты
выделяются по уровням соподчиненности (иерархии) объектов.
Для поиска необходимой записи нужно двигаться от корня к листьям, т.е. сверху вниз, что значительно упрощает доступ. Недостатки: длительный поиск от корня, после каждого поиска нужно снова возвращаться в корень, по горизонтали нет связей.

Слайд 16Сетевая модель БД
Сетевая модель БД хороша для небольших баз, в больших
можно запутаться. Трудности заключаются также в отладке таких баз данных.

Слайд 17Реляционная модель баз данных реализует табличный способ.
В реляционной модели базы
данных взаимосвязи между элементами данных представляются в виде двумерных таблиц, называемых отношениями.

Слайд 18Отношения обладают следующими свойствами:
каждый элемент таблицы представляет собой один элемент
данных (повторяющиеся группы отсутствуют);
элементы столбца имеют одинаковую природу, и столбцам однозначно присвоены имена;
в таблице нет двух одинаковых строк;
строки и столбцы могут просматриваться в любом порядке вне зависимости от их информационного содержания.
элементы столбца имеют одинаковую природу, и столбцам однозначно присвоены имена;
в таблице нет двух одинаковых строк;
строки и столбцы могут просматриваться в любом порядке вне зависимости от их информационного содержания.
;")
Слайд 19Преимущества реляционной модели баз данных:
Простота логической модели;
Гибкость системы защиты (для каждого
отношения может быть задана правомерность доступа) ;
Независимость данных;
Возможность построения простого языка манипулирования данными с помощью математически строгой теории реляционной алгебры (алгебры отношений).
Независимость данных;
Возможность построения простого языка манипулирования данными с помощью математически строгой теории реляционной алгебры (алгебры отношений).

Слайд 20
При работе с реляционными моделями используется как математическая терминология, так и
терминология исторически принятая в сфере обработки данных. При работе с реляционными моделями используется как математическая терминология, так и терминология исторически принятая в сфере обработки данных.

Слайд 21Реляционная модель БД имеет дело с тремя аспектами данных: со структурой
данных, с целостностью данных и с манипулированием данными. Под структурой понимается логическая организация данных в БД, под целостностью данных понимают безошибочность и точность информации, хранящейся в БД, под манипулированием данными - действия, совершаемые над данными в БД. Эти три аспекта отражают и основные процедуры процесса накопления данных (хранение, актуализацию и извлечение).

Слайд 22Структура базы данных определяет методы занесения данных и хранения их в
базе.
Манипулирование реляционными данными
Виды действий (манипуляций) над данными в реляционной модели представляют собой множество операций, получивших в совокупности название реляционной алгебры.
Эдгар Ф. Тэд Кодд, математик из фирмы IBM, выпускник Оксфордского университета, занимаясь исследования в области ЭВМ, в 1970-м разработал понятие реляционной базы данных и определил 8 операций. Объединённых в две группы, по 4 операции в каждой.
Манипулирование реляционными данными
Виды действий (манипуляций) над данными в реляционной модели представляют собой множество операций, получивших в совокупности название реляционной алгебры.
Эдгар Ф. Тэд Кодд, математик из фирмы IBM, выпускник Оксфордского университета, занимаясь исследования в области ЭВМ, в 1970-м разработал понятие реляционной базы данных и определил 8 операций. Объединённых в две группы, по 4 операции в каждой.

Слайд 23Реляционная алгебра
Виды действий (манипуляций) над данными в реляционной модели представляют собой
множество операций, получивших в совокупности название реляционной алгебры.
Первая группа - традиционные теоретико-множественные операции.
В каждой из этих операций используется два операнда (отношения-таблицы).
Для всех операций, кроме декартова произведения, эти два операнда должны быть одной степени (иметь одинаковое количество столбцов), и их атрибуты должны быть связаны с одним и тем же доменом. Доменом называют множество подобных значений одного и того же типа.
Первая группа - традиционные теоретико-множественные операции.
В каждой из этих операций используется два операнда (отношения-таблицы).
Для всех операций, кроме декартова произведения, эти два операнда должны быть одной степени (иметь одинаковое количество столбцов), и их атрибуты должны быть связаны с одним и тем же доменом. Доменом называют множество подобных значений одного и того же типа.
 над данными в реляционной модели представляют собой множество операций, получивших в")

Слайд 25Операция пересечения.
Пересечением двух отношений A и B называется множество всех
кортежей t, каждый из которых принадлежит как A, так и B:
где ∩ - символ пересечения.
где ∩ - символ пересечения.

Слайд 26Операция объединение.
Объединением двух отношений (таблиц) A и B называется множество
всех кортежей (строк) t, принадлежащих либо A, либо B, либо им обоим. Математически эта операция записывается так:
где U-символ объединения, - знак принадлежности к определенному отношению (множеству).
где U-символ объединения, - знак принадлежности к определенному отношению (множеству).
 A и B называется множество всех кортежей (строк) t,")
Слайд 27Операция разность. Разностью между двумя отношениями A и B называется множество
всех кортежей t, каждый из которых принадлежит A и не принадлежит B:
где \ - символ разности,
- символ отсутствия принадлежности отношению (множеству).
где \ - символ разности,
- символ отсутствия принадлежности отношению (множеству).
Операция разность.

Слайд 28Операция декартово произведение.
Декартовым произведением двух отношений A и B называется
множество всех кортежей t, таких, что t является конкатенацией некоторого кортежа а, принадлежащего A, и какого-либо кортежа b, принадлежащего B. (конкатенация - это соединение в цепочки).

Слайд 29Вторая группа - специальные реляционные операции.
Диаграммы специальных реляционных операций

Слайд 30Операция селекция.
Операция селекции позволяет получать „горизонтальные“ подмножества заданного отношения, для
которых выполняется некоторое поставленное условие (выбор строк).

Слайд 31Операция проекция
Операция проекция позволяет получить „вертикальное“ подмножество заданного отношения выбором
определенных атрибутов (выбор столбцов).
.")
Слайд 32Из восьми рассмотренных реляционных операций пять являются базовыми. Это - селекция,
проекция, декартово произведение, объединение и разность. Остальные три операции могут быть определены через базовые.

Слайд 33Операции реляционной модели данных представляют возможность произвольно манипулировать отношениями, позволяя обновлять
БД, а также выбирать подмножества хранимых данных и представлять их в нужном виде.
Особенности, определившие преимущества реляционной модели:
а) множество объектов реляционной модели БД однородно - структура БД определяется только в терминах отношений;
б) основная единица обработки в операциях реляционной модели не запись (как в сетевых и иерархических моделях), а множество записей - отношение.
Особенности, определившие преимущества реляционной модели:
а) множество объектов реляционной модели БД однородно - структура БД определяется только в терминах отношений;
б) основная единица обработки в операциях реляционной модели не запись (как в сетевых и иерархических моделях), а множество записей - отношение.

Слайд 34ПРОГРАММНО – АППАРАТНЫЙ УРОВЕНЬ ПРОЦЕССА НАКОПЛЕНИЯ ДАННЫХ
Логический (модельный) уровень процесса
накопления связан с физическим через программы, осуществляющие создание канонической структуры БД, схемы её хранения и работу с данными.
 уровень процесса накопления связан с физическим")

Слайд 36Каноническая структура БД создается с помощью модели выбора хранимых данных.
Формализованное
описание БД производится с помощью трех моделей:
модели хранения данных (структура БД),
модели актуализации данных
модели извлечения данных.
На основе этих моделей разрабатываются соответствующие программы:
создания канонической структуры БД (ПКС),
создания структуры хранения БД (ПС),
актуализации (ПА),
извлечения данных (ПИ).
модели хранения данных (структура БД),
модели актуализации данных
модели извлечения данных.
На основе этих моделей разрабатываются соответствующие программы:
создания канонической структуры БД (ПКС),
создания структуры хранения БД (ПС),
актуализации (ПА),
извлечения данных (ПИ).

Слайд 37Переход к физической модели базы данных, реализуемой и используемой на компьютере,
производится с помощью системы программ, позволяющих создать во внешней памяти ЭВМ базу хранимых данных и работать с этими данными, т.е. извлекать, изменять, дополнять, уничтожать.
Эти программы называются СУБД (системы управления базами данных).
Современная СУБД содержит в своем составе программные средства создания баз данных, средства работы с данными и дополнительные, сервисные средства.
Эти программы называются СУБД (системы управления базами данных).
Современная СУБД содержит в своем составе программные средства создания баз данных, средства работы с данными и дополнительные, сервисные средства.

Слайд 38Современная СУБД содержит в своем составе программные средства
создания баз данных,
средства работы с данными
и дополнительные, сервисные средства.
и дополнительные, сервисные средства.

Слайд 39С помощью средств создания БД проектировщик, используя язык описания данных (ЯОД),
переводит логическую модель БД в физическую структуру, а на языке манипуляции данными (ЯМД) разрабатывает программы, реализующие основные операции с данными. При проектировании привлекаются визуальные средства, т.е. объекты, и программа-отладчик, с помощью которой соединяются и тестируются отдельные блоки разработанной программы управления конкретной БД.
, переводит логическую модель БД")
Слайд 40СУБД – программный комплекс поддержки интегрированной совокупности данных, предназначенный для создания,
ведения и использования базы данных многими пользователями (прикладными программами).
СУБД обеспечивают как физическую (независимость от способа хранения и метода доступа), так и логическую независимость данных (возможность изменения одного приложения без изменения остальных приложений, работающих с этими же данными).

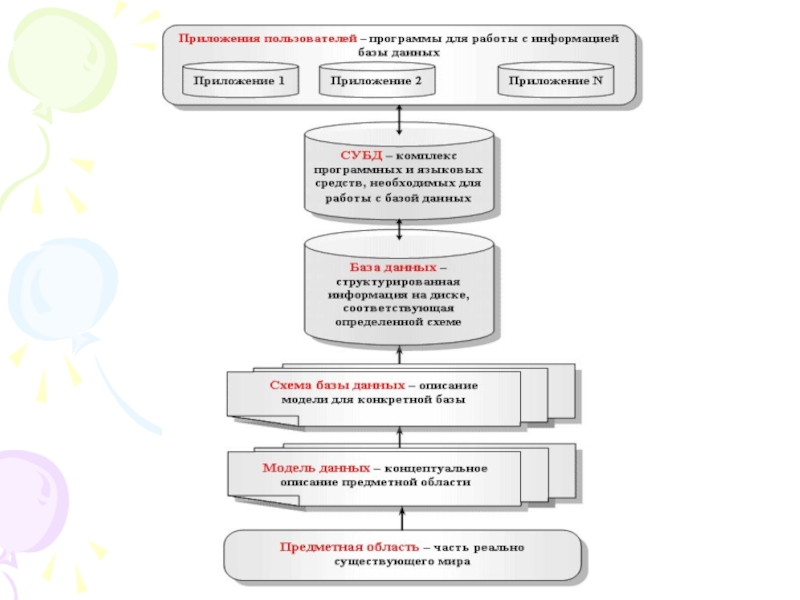
Слайд 42Система управления базами данных - комплекс программных и лингвистических средств общего
или специального назначения, реализующий поддержку создания баз данных, централизованного управления и организации доступа к ним различных пользователей в условиях принятой технологии обработки данных.
СУБД характеризуется используемой моделью, средствами администрирования и разработки прикладных процессов.
СУБД обеспечивает: - описание и сжатие данных; - манипулирование данными; - физическое размещение и сортировку записей; - защиту от сбоев, поддержку целостности данных и их восстановление; - работу с транзакциями и файлами; - безопасность данных.
СУБД характеризуется используемой моделью, средствами администрирования и разработки прикладных процессов.
СУБД обеспечивает: - описание и сжатие данных; - манипулирование данными; - физическое размещение и сортировку записей; - защиту от сбоев, поддержку целостности данных и их восстановление; - работу с транзакциями и файлами; - безопасность данных.

Слайд 43
ОСНОВНЫЕ ПОНЯТИЯ СУБД
Если в БД нет никаких данных ( пустая база
), то это все равно полноценная БД, т.к. она содержит информацию о структуре базы.
Структура базы определяет методы занесения данных и хранения их в базе. БД могут содержать различные объекты. Основными объектами БД являются таблицы. Простейшая база данных имеет хотя бы одну таблицу. Структура простейшей базы данных тождественно равна структуре ее таблицы.
Структуру двумерной таблицы образуют столбцы и строки. Их аналогами в структуре простейшей базы данных являются поля и записи.
Если записей в таблице нет, то ее структура образована набором полей. Изменив состав полей базовой таблицы (или их свойства), тем самым изменяем структуру данных, и, соответственно, получаем новую базу данных.
Структура базы определяет методы занесения данных и хранения их в базе. БД могут содержать различные объекты. Основными объектами БД являются таблицы. Простейшая база данных имеет хотя бы одну таблицу. Структура простейшей базы данных тождественно равна структуре ее таблицы.
Структуру двумерной таблицы образуют столбцы и строки. Их аналогами в структуре простейшей базы данных являются поля и записи.
Если записей в таблице нет, то ее структура образована набором полей. Изменив состав полей базовой таблицы (или их свойства), тем самым изменяем структуру данных, и, соответственно, получаем новую базу данных.
, то это все")
Слайд 44Обычно с БД работают две категории исполнителей:
• Проектировщики – разрабатывают
структуру таблиц базы и согласовывают ее с заказчиком; разрабатывают объекты, предназначенные для автоматизации работы и ограничения функциональных возможностей работы с базой (из соображений безопасности);
• Пользователи – работают с базами данных, наполняют ее и обслуживают.
СУБД имеет два режима: проектировочный и пользовательский.
В проектировочном режиме создаются и изменяются структура базы и ее объекты. В пользовательском используются ранее подготовленные объекты для наполнения БД или получения данных из нее.
• Пользователи – работают с базами данных, наполняют ее и обслуживают.
СУБД имеет два режима: проектировочный и пользовательский.
В проектировочном режиме создаются и изменяются структура базы и ее объекты. В пользовательском используются ранее подготовленные объекты для наполнения БД или получения данных из нее.

Слайд 45ОБЪЕКТЫ БАЗЫ ДАННЫХ
Таблицы – основные объекты любой БД, в которых хранятся
все данные, имеющиеся в базе, и хранится сама структура базы (поля, их типы и свойства).
Отчеты – предназначены для вывода данных. В них приняты специальные меры для группирования выводимых данных и для вывода специальных элементов оформления, характерных для печатных документов (верхний и нижний колонтитулы, номера страниц, время создания отчета и другое).
Страницы доступа к данным – специальные объекты БД, интерфейс между клиентом, сервером и базой данных, размещенным на сервере.
Макросы и модули – предназначены для автоматизации повторяющихся операций при работе с системой управления БД, так и для создания новых функций путем программирования.
Отчеты – предназначены для вывода данных. В них приняты специальные меры для группирования выводимых данных и для вывода специальных элементов оформления, характерных для печатных документов (верхний и нижний колонтитулы, номера страниц, время создания отчета и другое).
Страницы доступа к данным – специальные объекты БД, интерфейс между клиентом, сервером и базой данных, размещенным на сервере.
Макросы и модули – предназначены для автоматизации повторяющихся операций при работе с системой управления БД, так и для создания новых функций путем программирования.

Слайд 46ЗАПРОСЫ И ФОРМЫ
Запросы – служат для извлечения данных из таблиц и
предоставления их пользователю в удобном виде. С их помощью выполняют отбор данных, их сортировку и фильтрацию. Можно выполнить преобразование данных по заданному алгоритму, создавать новые таблицы, выполнять автоматическое заполнение таблиц данными, импортированными из других источников, выполнять простейшие вычисления в таблицах и многое другое.
Обновление БД тоже можно осуществить посредством запроса.
Формы – средства для ввода данных, предоставляющие пользователю необходимые для заполнения поля. В них можно разместить специальные элементы управления (счетчики, раскрывающиеся списки, переключатели, флажки и прочее) для автоматизации ввода.
Обновление БД тоже можно осуществить посредством запроса.
Формы – средства для ввода данных, предоставляющие пользователю необходимые для заполнения поля. В них можно разместить специальные элементы управления (счетчики, раскрывающиеся списки, переключатели, флажки и прочее) для автоматизации ввода.

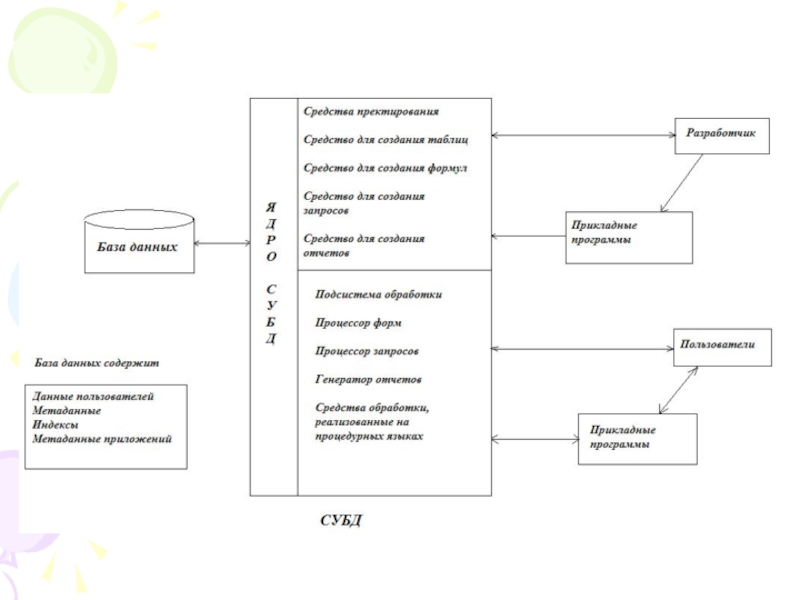


Слайд 50ВИДЫ СУБД
СУБД принципиально различаются по моделям БД, с которыми они
работают. Если модель БД реляционная, то нужно использовать реляционную СУБД, если сетевая - сетевую СУБД, и т.д.
По степени универсальности различают два класса СУБД:
системы общего назначения;
специализированные системы.
По степени распределённости
Локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
Распределённые СУБД (части СУБД могут размещаться на двух и более компьютерах).
По степени универсальности различают два класса СУБД:
системы общего назначения;
специализированные системы.
По степени распределённости
Локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
Распределённые СУБД (части СУБД могут размещаться на двух и более компьютерах).

Слайд 51По способу доступа к БД
Файл-серверные В файл-серверных СУБД файлы данных располагаются
централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть.
На данный момент файл-серверная технология считается устаревшей.Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
На данный момент файл-серверная технология считается устаревшей.Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.

Слайд 52Клиент-серверные Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет
доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Примеры: Oracle, Firebird, InterbaseOracle, Firebird, Interbase, IBM DB2, InformixOracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server EnterpriseOracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQLOracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQLOracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.
Встраиваемые Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети.
Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы. Примеры: OpenEdgeOpenEdge, SQLiteOpenEdge, SQLite, BerkeleyDBOpenEdge, SQLite, BerkeleyDB, FirebirdOpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server CompactOpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.
Встраиваемые Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети.
Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы. Примеры: OpenEdgeOpenEdge, SQLiteOpenEdge, SQLite, BerkeleyDBOpenEdge, SQLite, BerkeleyDB, FirebirdOpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server CompactOpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.


Слайд 54
СУБД реализует следующие основные функции низкого уровня:
* управление данными во внешней
памяти;
* управление буферами оперативной памяти;
* управление транзакциями;
* ведение журнала изменений в БД;
* обеспечение целостности и безопасности БД.
* управление буферами оперативной памяти;
* управление транзакциями;
* ведение журнала изменений в БД;
* обеспечение целостности и безопасности БД.

Слайд 55Выделяют следующие основные функции СУБД.
· Непосредственное управление данными во внешней памяти
Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы).
·Управление буферами оперативной памяти
СУБД обычно работают с БД значительного размера - этот размер обычно существенно больше доступного объема оперативной памяти. Если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти.

Слайд 56·Управление транзакциями
Транзакция - это последовательность операций над БД, рассматриваемых СУБД как
единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД.
·
·

Слайд 57Журнализация
Одним из основных требований к СУБД является надежность хранения данных во
внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя.
Обычно рассматриваются два возможных вида аппаратных сбоев: мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. В любом случае для восстановления БД нужно располагать некоторой дополнительной информацией.
Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД (журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью, в которую поступают записи обо всех изменениях основной части БД).
Обычно рассматриваются два возможных вида аппаратных сбоев: мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. В любом случае для восстановления БД нужно располагать некоторой дополнительной информацией.
Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД (журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью, в которую поступают записи обо всех изменениях основной части БД).

Слайд 58·Поддержка языков БД
Для работы с базами данных используются специальные языки, называемые
языками баз данных.
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language)
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language)


Слайд 61Средства работы с данными предназначены для пользователя БД. Они позволяют
установить
удобный интерфейс с пользователем,
создать необходимую функциональную конфигурацию экранного представления выводимой и вводимой информации (цвет, размер и количество окон, пиктограммы пользователя и т.д.),
производить операции с данными БД, манипулируя текстовыми и графическими экранными объектами.
Дополнительные (сервисные) средства позволяют при проектировании и использовании БД привлечь к работе с БД другие системы. Например, воспользоваться текстом из системы редактирования Word или таблицей из табличной системы Excel, или обратиться к сетевому серверу.
создать необходимую функциональную конфигурацию экранного представления выводимой и вводимой информации (цвет, размер и количество окон, пиктограммы пользователя и т.д.),
производить операции с данными БД, манипулируя текстовыми и графическими экранными объектами.
Дополнительные (сервисные) средства позволяют при проектировании и использовании БД привлечь к работе с БД другие системы. Например, воспользоваться текстом из системы редактирования Word или таблицей из табличной системы Excel, или обратиться к сетевому серверу.

Слайд 62СУБД принципиально различаются по моделям БД, с которыми они работают.
Если модель
БД реляционная, то нужно использовать реляционную СУБД, если сетевая - сетевую СУБД, и т.д.
По степени универсальности различают два класса СУБД:
системы общего назначения;
специализированные системы.
По степени универсальности различают два класса СУБД:
системы общего назначения;
специализированные системы.

Слайд 63В информационном процессе накопления данных наибольший вес имеют базы данных как
независимые от прикладных программ хранилища данных.
Однако, это не единственный способ накопления данных. Одной из форм хранения данных на дисках компьютеров, является файловая форма. Она поддерживается всеми современными операционными системами, которые представляют пользователю разнообразный набор графических, экранных средств манипуляции файлами.
Однако, это не единственный способ накопления данных. Одной из форм хранения данных на дисках компьютеров, является файловая форма. Она поддерживается всеми современными операционными системами, которые представляют пользователю разнообразный набор графических, экранных средств манипуляции файлами.






