)
- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Интеграция баз данных на основе онтологий презентация
Содержание
- 1. Интеграция баз данных на основе онтологий
- 2. Интеграция баз данных на основе онтологий Тузовский
- 3. Постановка задачи интеграции Задача интеграции данных
- 4. Проблемы задачи интеграции данных Разнородность (гетерогенность) источники
- 5. Виды разнородности различие моделей данных – данные
- 7. Обобщенная архитектура систем интеграции информации
- 8. Общие компонентами являются Посредники Адаптеры Дополнительные подсистемы
- 9. Посредник (или посредники) интерфейс доступа, который
- 10. Процессор запросов центральный элемент посредника; выполняет следующие
- 11. Адаптеры (wrappers) компоненты, связанные с источниками данных
- 12. Постановка задачи Формально систему интеграции данных T
- 13. Формирование глобальной онтологии (предметной области) Моделирование онтологии
- 14. Эксперименты во многих прикладных проектах Semantic
- 15. Онтология предметной области наблюдения за солнцем
- 16. Отображение моделей Два основных подхода к
- 17. Формирование и описание отображений Формальное описание соответствий
- 18. Когда поступает запрос к целевой модели
- 19. Логическое отображение создается или вручную или
- 20. Двухэтапный подход к отображению/преобразованию
- 21. Прямой или одноэтапный подход к отображению/преобразованию
- 22. Логический вывод глобальных запросов Глобальные запросы формулируются
- 23. Походы к созданию систем интеграции на основе
- 24. СИИ на основе реляционных моделей данных
- 25. Архитектура системы интеграции Garlic
- 26. Архитектура и процессы в системе DISCO
- 27. Архитектура системы TSIMMIS.
- 28. СИИ на основе реляционных онтологий
- 29. Схема системы InfoSleuth, включающая агенты для интеграции информации
- 30. Архитектура виртуальной обсерватории (ИПИ РАН) АРХИТЕКТУРА ПРОМЕЖУТОЧНОГО
- 31. Общая архитектура посредника Yacob Mediator
- 32. Единое научное информационное пространство Предлагаемый алгоритм
- 33. Технологии Semantic Web Язык описания данных RDF
- 34. Интеграция данных на основе семантических технологий Различные
- 35. Преимущества использования RDF в качестве глобальной метамодели
- 36. RDF, RDF-Schema, OWL и другие стандарты
- 37. Для каждого правильной (valid) строки SPARQL
- 38. Пример алгебраического плана Для примера запроса показан его алгебраический план.
- 39. Текстовое описание плана запроса Slice((0; 10), Project((?name
- 40. Подходы к решению задачи формирования плана выполнения
- 41. Соотношение выразительности и парадигмы интеграции
- 42. СИИ на основе семантических технологий Semantic Web
- 43. Проект SemWIQ распределенные источники данных, отображенные (mapped
- 44. Основные понятия языка SPARQL Шаблоны триплетов –
- 45. Формы запросов запрос SELECT - для выбора
- 46. Алгебраические операторы и планы запроса
- 47. Базовый графовый шаблон можно сравнить с
- 48. БГШ может рассматриваться как конъюнктивный запрос,
- 49. Системы интеграции информации SemWIQ Цели разработки системы:
- 50. Системы интеграции информации SemWIQ Система SemWIQ способна
- 51. Основные идеи Преобразование схем БД в RDFS/OWL
- 52. Описание системы SemWIQ Глобальная метамодель (Global metamodel)
- 53. Архитектура системы SemWIQ
- 54. Архитектура системы SemWIQ Интерфейс (Interface) SPARQL
- 55. Архитектура системы SemWIQ (2) Компонент регистрации (Registry
- 56. Архитектура системы SemWIQ (3) Процессор запросов (Query
- 57. Посредники системы SemWIQ
- 58. Схема работы посредника и адаптера
- 59. Предварительные оптимизации Фильтры (Filters) Оператор Filter определяет
- 60. Шаг 1e) Любые последовательные (consecutive) коньюнкции
- 61. Правила проталкивания фильтров Для проталкивания фильтров, выражения
- 62. LeftJoin: при наличии предшествующего (preceding) фильтра
- 63. Федерирование запроса Задачей данного федератора (federator) является
- 64. Пост-оптимизации Оптимизация фильтров (шаги пред-оптимизации 1f
- 65. Выполнение запроса После того, как план
- 66. Итераторы выполнения запросов
- 67. Алгоритм замещения Система Jena ARQ основана
- 68. Основанный на триплетах федератор Федератор, основанный
- 69. Основанные на экземплярах федераторы Предполагается, что
- 70. Адаптеры системы SemWIQ Система SemWIQ в основном
- 71. Отображение нескольких моделей данных в общую RDF модель
- 72. (б) Прямой или одно-этапный подход к отображению/преобразованию
- 73. Глобальная RDF модель включает (consists of)
- 74. Реализация адаптеров на основе Jena ARQ
- 75. Для реализации адаптера RDB-to-RDF может быть
- 76. Рабочая группа RDB2RDF W3C В сентябре 2009
- 77. Адаптеры для реляционных баз данных С
- 80. Отображения D2RQ Система D2RQ-Map является средством
- 81. Соответствия свойств (мосты свойств, property bridges))
- 82. Пример интеграции реляционной базы данных Используется система
- 84. Отображение D2RQ (mapping) позволяет выполнять одношаговое
- 85. SPARQL запрос и соответствующий ему план запроса
- 86. SQL запросы для OpD2RQ1 и OpD2RQ2
- 87. Возможности системы D2RQ-Map Система D2RQ-Map использует
- 88. Соответствия (correspondences) 1 : 1, 1
- 89. Спасибо за внимание!
Слайд 1Интеграция баз данных на основе онтологий
Тузовский А.Ф.
Томский политехнический университет
(институт Кибернетики
")
Слайд 2Интеграция баз данных на основе онтологий
Тузовский А.Ф.
Томский политехнический университет
(институт Кибернетики
)
Развитие систем интеграции информации
Развитие систем интеграции информации")
Слайд 3Постановка задачи интеграции
Задача интеграции данных заключается в соединении данных из
различных источников и предоставлении пользователю единого (унифицированного) представления этих данных, в том числе возможности извлечения интересующей пользователя информации по запросу.
Система интеграции данных позволяет освободить пользователя от необходимости самостоятельно отбирать источники, в которых находится интересующая пользователя информация, обращаться к каждому источнику по отдельности, и вручную сопоставлять и объединять данные из различных источников.
Система интеграции данных позволяет освободить пользователя от необходимости самостоятельно отбирать источники, в которых находится интересующая пользователя информация, обращаться к каждому источнику по отдельности, и вручную сопоставлять и объединять данные из различных источников.

Слайд 4Проблемы задачи интеграции данных
Разнородность (гетерогенность) источники данных используют разные модели (и
даже метамодели).
Автономность, то есть источники разработаны и эксплуатируются независимо друг от друга, независимо спроектированы под решение конкретных, различных задач, различными методами.
Распределенность источники физически или логически, доступными через только сетевые протоколы удаленного доступа, в частности, информационные источники могут быть распределены в сети Интернет.
Автономность, то есть источники разработаны и эксплуатируются независимо друг от друга, независимо спроектированы под решение конкретных, различных задач, различными методами.
Распределенность источники физически или логически, доступными через только сетевые протоколы удаленного доступа, в частности, информационные источники могут быть распределены в сети Интернет.
 источники данных используют разные модели (и даже метамодели).Автономность, то есть")
Слайд 5Виды разнородности
различие моделей данных – данные в различных источниках могут представляться
разными способами, в различных моделях данных (например, реляционная, объектно-ориентированная модели данных, XML, слабоструктурированные, неструктурированные данные, и т.д.);
синтаксическая неоднородность – данные могут по-разному представляться при передаче их в соответствии с протоколами взаимодействия (например, бинарные, текстовые, XML, и т.д.);
структурная неоднородность – данные в различных источниках могут по-разному представлены и организованы в структуру (например, ФИО может быть представлено одной строкой или тремя строками);
семантическая неоднородность – данные могут быть представлены в различных системах понятий, схожие понятия могут по-разному интерпретироваться в разных источниках данных.
техническая неоднородность – интегрируемые информационные системы – источники данных работают под управлением различных операционных систем, на различном техническом обеспечении, предоставляют различные способы коммуникации для доступа к системе, различные интерфейсы и протоколы взаимодействия, и т.д.;
неоднородность методов доступа к данным - в частности, различное назначение и выразительность языков запросов для извлечения данных, различные ограничения на форму запросов;
синтаксическая неоднородность – данные могут по-разному представляться при передаче их в соответствии с протоколами взаимодействия (например, бинарные, текстовые, XML, и т.д.);
структурная неоднородность – данные в различных источниках могут по-разному представлены и организованы в структуру (например, ФИО может быть представлено одной строкой или тремя строками);
семантическая неоднородность – данные могут быть представлены в различных системах понятий, схожие понятия могут по-разному интерпретироваться в разных источниках данных.
техническая неоднородность – интегрируемые информационные системы – источники данных работают под управлением различных операционных систем, на различном техническом обеспечении, предоставляют различные способы коммуникации для доступа к системе, различные интерфейсы и протоколы взаимодействия, и т.д.;
неоднородность методов доступа к данным - в частности, различное назначение и выразительность языков запросов для извлечения данных, различные ограничения на форму запросов;



Слайд 8Общие компонентами являются
Посредники
Адаптеры
Дополнительные подсистемы
Обычно система, основанная на посредниках не поддерживает работу
с данными (добавление, изменение, удаление данных).

Слайд 9Посредник
(или посредники)
интерфейс доступа, который используется приложениями интегрированной системы, либо с
помощью промежуточного ПО (Web Service, SPARQL и т.п.) или с помощью прикладного интерфейса API.
процессор запросов (query processor), которые отвечает за разделение, оптимизацию и выполнение запросов поступающих в систему.
каталог метаданных (metadata catalog) (или база знаний в случае систем, основанных на онтологиях), который хранит
глобальную модель данных, которая может описываться (defined) и поддерживаться явно (defined) или неявно, как объединение всех локальных моделей данных.
статистические данные, такие, как селективности (selectivities) или гистограммы (histograms).
Компонент регистрации (registry) используемый для регистрации и де-регистрации источников данных (обычно регистрация требует предоставления метаданных о источнике и отображения модели (model mapping)).
процессор запросов (query processor), которые отвечает за разделение, оптимизацию и выполнение запросов поступающих в систему.
каталог метаданных (metadata catalog) (или база знаний в случае систем, основанных на онтологиях), который хранит
глобальную модель данных, которая может описываться (defined) и поддерживаться явно (defined) или неявно, как объединение всех локальных моделей данных.
статистические данные, такие, как селективности (selectivities) или гистограммы (histograms).
Компонент регистрации (registry) используемый для регистрации и де-регистрации источников данных (обычно регистрация требует предоставления метаданных о источнике и отображения модели (model mapping)).
интерфейс доступа, который используется приложениями интегрированной системы, либо с помощью промежуточного ПО (Web")
Слайд 10Процессор запросов
центральный элемент посредника;
выполняет следующие действия:
получения запроса пользователя
разбор запроса;
формирование общего плана
выполнения.
формирование под-планов к адаптерам источников;
оптимизация по времени обработки (стоимости);
отправка под-планов адаптерам источников;
получение результатов;
формирование ответа пользователю.
формирование под-планов к адаптерам источников;
оптимизация по времени обработки (стоимости);
отправка под-планов адаптерам источников;
получение результатов;
формирование ответа пользователю.

Слайд 11Адаптеры (wrappers)
компоненты, связанные с источниками данных для решения проблем технической разнородности
и разнородностей метамоделей.
Регистрация в посреднике.
принимают запросы к источнику на некотором языке.
преобразует запрос в язык источника;
Выполняет запрос.
Отправляет результаты посреднику.
Регистрация в посреднике.
принимают запросы к источнику на некотором языке.
преобразует запрос в язык источника;
Выполняет запрос.
Отправляет результаты посреднику.
компоненты, связанные с источниками данных для решения проблем технической разнородности и разнородностей метамоделей. Регистрация")
Слайд 12Постановка задачи
Формально систему интеграции данных T можно описать в виде триплета
G – глобальная модель (схема) описанная на языке LG с использованием алфавита AG, который состоит из символов для описания элементов схемы в G;
S – исходная модель (схема) описанная на языке LS с использованием алфавита AS, который включает символы для элементов всех источников;
M – отображение (mapping) между G и S, описанное в форме утверждений (assertions): qS ⤳ qG и qG ⤳ qS
Такое определение не ограничивается только реляционной моделью, т.е., система интеграции, основанная на RDF будет использовать такие понятия языка RDF, как классы, свойства и типы данных в качестве элементов схемы.

Слайд 13Формирование глобальной онтологии (предметной области)
Моделирование онтологии конкретных предметных областей, (domain ontologies)
является дорогой и трудоемкой задачей, требующей участия экспертов
Однако данная работа должна быть выполнена только один раз основным сообществом, которое умеет разрабатывать и поддерживать словари с помощью средств совместной работы разработанных сообщество Semantic Web.
Даже не эксперты могут добавлять и отображать (map) новые источники данных с помощью широко признанных вспомогательных онтологий, например,Dublin Core, FOAF, SOAP, DOAP и т.д.).
Для конкретной прикладной области разумным считается следующий подход:
вначале выполнить поиск существующих онтологий,
затем заполнить разрывы между ними на основе подхода снизу-вверх (bottom-up, от частных понятий к более общим).
Однако данная работа должна быть выполнена только один раз основным сообществом, которое умеет разрабатывать и поддерживать словари с помощью средств совместной работы разработанных сообщество Semantic Web.
Даже не эксперты могут добавлять и отображать (map) новые источники данных с помощью широко признанных вспомогательных онтологий, например,Dublin Core, FOAF, SOAP, DOAP и т.д.).
Для конкретной прикладной области разумным считается следующий подход:
вначале выполнить поиск существующих онтологий,
затем заполнить разрывы между ними на основе подхода снизу-вверх (bottom-up, от частных понятий к более общим).
Моделирование онтологии конкретных предметных областей, (domain ontologies) является дорогой и трудоемкой")
Слайд 14
Эксперименты во многих прикладных проектах Semantic Web показали, что специальный подход
сверху-вниз часто является не очень многообещающим, приводящим к долгим философским спорам между участниками.
Обычно не практичным является попытка описать сразу всю предметную область, хотя начальные источники данных описывают только небольшую часть данной предметной области.
Вместо этого, обычно лучше использовать подход снизу-вверх (bottom-up) и моделировать необходимые понятия (concepts) на основе существующих онтологий, в тоже время сохраняя некоторую степень обобщенности и планируя возможные будущие точки расширения.
Обычно не практичным является попытка описать сразу всю предметную область, хотя начальные источники данных описывают только небольшую часть данной предметной области.
Вместо этого, обычно лучше использовать подход снизу-вверх (bottom-up) и моделировать необходимые понятия (concepts) на основе существующих онтологий, в тоже время сохраняя некоторую степень обобщенности и планируя возможные будущие точки расширения.


Слайд 16Отображение моделей
Два основных подхода к спецификации семантического отображения терминов в
системах интеграции данных:
Global-as-view - отдельные глобальные понятия специфицируются в терминах локальной системы понятий:
qS ⤳ qG
подходит для статичных систем интеграции данных, проектируемых «снизу вверх»,
Local-as-view - отдельные локальные понятия специфицируются в терминах глобальной системы понятий:
qG ⤳ qS
подходит для динамичных систем интеграции данных, проектируемых «сверху вниз».
Некоторым компромиссом является гибридный подход GLAV.
Global-as-view - отдельные глобальные понятия специфицируются в терминах локальной системы понятий:
qS ⤳ qG
подходит для статичных систем интеграции данных, проектируемых «снизу вверх»,
Local-as-view - отдельные локальные понятия специфицируются в терминах глобальной системы понятий:
qG ⤳ qS
подходит для динамичных систем интеграции данных, проектируемых «сверху вниз».
Некоторым компромиссом является гибридный подход GLAV.

Слайд 17Формирование и описание отображений
Формальное описание соответствий или логическое отображение (logical mapping),
соответственно, в действительности зависит от метамоделей и возможностей системы интеграции в целом.
Например:
При работе с реляционными базами данных, в качестве языка отображения может использоваться SQL, так как отображения могут быть описаны в виде SQL представлений (views).
Язык описания онтологий OWL.
Язык правил SWRL или RIF.
Язык D2RQ-Map, используемый сервером D2R-Server для формирования отображений реляционной модели на язык RDF.
Например:
При работе с реляционными базами данных, в качестве языка отображения может использоваться SQL, так как отображения могут быть описаны в виде SQL представлений (views).
Язык описания онтологий OWL.
Язык правил SWRL или RIF.
Язык D2RQ-Map, используемый сервером D2R-Server для формирования отображений реляционной модели на язык RDF.
, соответственно, в действительности зависит")
Слайд 18
Когда поступает запрос к целевой модели (например, к виртуальной глобальной модели),
то система использует логическое отображение для формирования локальных запросов и для соответствующего преобразования всех исходных данных.
, то система использует логическое")
Слайд 19
Логическое отображение создается или вручную или полуавтоматически с помощью алгоритмов формирования
соответствия схем или онтологий.
Такие алгоритмы также могут использоваться для облегчения создания интегрированной глобальной модели. Они основываются на определении соответствия на основе:
сопоставления лексического сходства (например, с использованием
расстояния (метрики) Левенштейна,
n-gram моделей,
фонетических алгоритмов),
сопоставления на основе сравнения графов, как, например,
алгоритм распространения сходства (similarity flooding) предложенный в работе,
на основе использования таксономии и тезаурусы конкретных предметных областей.
Так как эти алгоритмы основываются на эвристиках, то полностью автоматические подходы работают не достаточно точно.
Такие алгоритмы также могут использоваться для облегчения создания интегрированной глобальной модели. Они основываются на определении соответствия на основе:
сопоставления лексического сходства (например, с использованием
расстояния (метрики) Левенштейна,
n-gram моделей,
фонетических алгоритмов),
сопоставления на основе сравнения графов, как, например,
алгоритм распространения сходства (similarity flooding) предложенный в работе,
на основе использования таксономии и тезаурусы конкретных предметных областей.
Так как эти алгоритмы основываются на эвристиках, то полностью автоматические подходы работают не достаточно точно.



Слайд 22Логический вывод глобальных запросов
Глобальные запросы формулируются (записываются) на языке описания глобальных
запросов LQ с использованием алфавита глобальной схемы AG.
Помимо такого общего определения, природа конкретной системы интеграции зависит от выразительности и характеристик языков описания отображения, схем и запросов.
C логической точки зрения, ответ на глобальный запрос фактически является задачей логического вывода.
Система должна создать результирующие кортежи, которые удовлетворяют глобальному запросу путем логического объединения промежуточных кортежей из набора источников на основе заданных отображений.
Особое внимание требуется в том случае, если информационная система накладывает дополнительные глобальные ограничения. Если информационная система интегрирует данные из автономных источников, то глобальные ограничения могут приводить к запросам, на которые нет ответов.
Помимо такого общего определения, природа конкретной системы интеграции зависит от выразительности и характеристик языков описания отображения, схем и запросов.
C логической точки зрения, ответ на глобальный запрос фактически является задачей логического вывода.
Система должна создать результирующие кортежи, которые удовлетворяют глобальному запросу путем логического объединения промежуточных кортежей из набора источников на основе заданных отображений.
Особое внимание требуется в том случае, если информационная система накладывает дополнительные глобальные ограничения. Если информационная система интегрирует данные из автономных источников, то глобальные ограничения могут приводить к запросам, на которые нет ответов.
 на языке описания глобальных запросов LQ с использованием")
Слайд 23Походы к созданию систем интеграции на основе посредников
На основе реляционных
моделей данных (1990 г.г.):
Основная метамодель: ODMG-93
На основе онтологий (конец 1990-х начало 2005г.):
Основная метамодель: языки описания онтологий
На основе технологий Semantic Web (с 2004 г.):
Основная метамодель: RDF
Основная метамодель: ODMG-93
На основе онтологий (конец 1990-х начало 2005г.):
Основная метамодель: языки описания онтологий
На основе технологий Semantic Web (с 2004 г.):
Основная метамодель: RDF
:Основная")






Слайд 30Архитектура виртуальной обсерватории (ИПИ РАН)
АРХИТЕКТУРА ПРОМЕЖУТОЧНОГО СЛОЯ ПРЕДМЕТНЫХ ПОСРЕДНИКОВ ДЛЯ РЕШЕНИЯ
ЗАДАЧ НАДМНОЖЕСТВОМ ИНТЕГРИРУЕМЫХ НЕОДНОРОДНЫХ РАСПРЕДЕЛЕННЫХ ИНФОРМАЦИОННЫХ РЕСУРСОВ В ГИБРИДНОЙ ГРИД-ИНФРАСТРУКТУРЕ ВИРТУАЛЬНЫХ ОБСЕРВАТОРИЙ Д.О. Брюхов, А. Е. Вовченко, В.Н. Захаров, О.П. Желенкова, Л.А. Калиниченко, Д.О.Мартынов, Н.А. Скворцов, С.А. Ступников
АРХИТЕКТУРА ПРОМЕЖУТОЧНОГО СЛОЯ ПРЕДМЕТНЫХ ПОСРЕДНИКОВ ДЛЯ РЕШЕНИЯ ЗАДАЧ НАДМНОЖЕСТВОМ ИНТЕГРИРУЕМЫХ НЕОДНОРОДНЫХ")

Слайд 32Единое научное информационное пространство
Предлагаемый алгоритм включает следующие основные этапы:
Переформулировка относительно
аксиом глобальной онтологии;
Переформулировка относительно отображений онтологии;
Переформулировка относительно аксиом онтологии источников;
Минимизация полученного запроса.
Переформулировка относительно отображений онтологии;
Переформулировка относительно аксиом онтологии источников;
Минимизация полученного запроса.
Бездушный Алексей А. (ВЦ РАН) Математическая модель интеграции данных на основе дескриптивной логики, 2008

Слайд 33Технологии Semantic Web
Язык описания данных RDF в виде триплетов (граф).
Языки описания
моделей данных на основе языков RDFS и OWL (которые сами описываются в виде наборов триплетов и графов).
Язык запросов SPARQL к наборам триплетов (графам).
Язык запросов SPARQL к наборам триплетов (графам).
.Языки описания моделей данных на основе")
Слайд 34Интеграция данных на основе семантических технологий
Различные источники данных могут быть объединены
в общую модель с помощью RDF.
Путем добавления других технологий Semantic Web, они могут быть интегрированы в общую модель знаний.
Путем добавления других технологий Semantic Web, они могут быть интегрированы в общую модель знаний.

Слайд 35Преимущества использования RDF в качестве глобальной метамодели
RDF по определению ориентирован
на работу в web-сети (Web-centric) и является хорошо масштабируемым, так как взаимосвязанные RDF онтологии могут быть распределены по сети World Wide Web;
RDF онтологии могут быть опубликованы любым пользователем в web сети для того, чтобы расширить существующие понятия (concepts) (взаимосвязями) с новыми понятиями, если это требуется (например, при добавлении нового источника данных к системе SemWIQ, информация которого не описывается текущей глобальной моделью, которая по существу является суммой всех опубликованных онтологий, использованных для описания источников данных).
Идентификаторы URI используются в качестве глобальных идентификаторов для всех понятий (concepts), что облегчает управление глобальным пространством имен URI (global URI namespace), путем использования Системы Доменных Имен (Domain Name System, DNS).
RDF онтологии могут быть опубликованы любым пользователем в web сети для того, чтобы расширить существующие понятия (concepts) (взаимосвязями) с новыми понятиями, если это требуется (например, при добавлении нового источника данных к системе SemWIQ, информация которого не описывается текущей глобальной моделью, которая по существу является суммой всех опубликованных онтологий, использованных для описания источников данных).
Идентификаторы URI используются в качестве глобальных идентификаторов для всех понятий (concepts), что облегчает управление глобальным пространством имен URI (global URI namespace), путем использования Системы Доменных Имен (Domain Name System, DNS).

Слайд 36
RDF, RDF-Schema, OWL и другие стандарты W3C разрабатываемые на их основе
являются стандартизированными и широко используемыми языка представления знаний.
RDF граф может быть описан простым способом в виде набора триплетов , что облегчают слияние не полных, фрагментированных графов из распределенных источников.
RDF-Schema, OWL и другие словари построенные над RDF Core предоставляют все типичные средства (mechanisms) описания понятий, известные из других сред (например, Entity Relationship Model и UML), которые требуются для моделирующих онтологий.
RDF-Schema и OWL поддерживают терминологические dscrfpsdfybz(t-box) и утверждающие высказывания (assertional statements) (a-box), также, как и многие возможности дескриптивные логики, которые могут использоваться для выполнения логического вывода над данными и наложения ограничений.
RDF граф может быть описан простым способом в виде набора триплетов , что облегчают слияние не полных, фрагментированных графов из распределенных источников.
RDF-Schema, OWL и другие словари построенные над RDF Core предоставляют все типичные средства (mechanisms) описания понятий, известные из других сред (например, Entity Relationship Model и UML), которые требуются для моделирующих онтологий.
RDF-Schema и OWL поддерживают терминологические dscrfpsdfybz(t-box) и утверждающие высказывания (assertional statements) (a-box), также, как и многие возможности дескриптивные логики, которые могут использоваться для выполнения логического вывода над данными и наложения ограничений.

Слайд 37
Для каждого правильной (valid) строки SPARQL запроса qlex, существует формально определенный
план запроса (query plan) q, который рекурсивно описывается объединением отдельных алгебраических операторов p.
Алгебраический план часто используется вместо термина план запроса.
Алгебраический план часто используется вместо термина план запроса.
 строки SPARQL запроса qlex, существует формально определенный план запроса (query plan)")

Слайд 39Текстовое описание плана запроса
Slice((0; 10),
Project((?name ?mbox ?i),
Order((?name),
LeftJoin(
BGP((?s rdf:type foaf:Person), (?s foaf:name
?name),
(?s foaf:interest ?i)),
BGP((?s foaf:mboxsha1_sum ?mbox))
)
)
)
)
(?s foaf:interest ?i)),
BGP((?s foaf:mboxsha1_sum ?mbox))
)
)
)
)
,Project((?name ?mbox ?i),Order((?name),LeftJoin( BGP((?s rdf:type foaf:Person), (?s foaf:name ?name), (?s foaf:interest ?i)), BGP((?s")
Слайд 40Подходы к решению задачи формирования плана выполнения запросов
Решение задачи математической (дескриптивной)
логики.
Структурный подход на основе графов.
Структурный подход на основе графов.
 логики.Структурный подход на основе графов.")


Слайд 43Проект SemWIQ
распределенные источники данных, отображенные (mapped to) на распределенные онтологии.
масштабируемость относительно
количества источников данных и количества и размера онтологий.
полное использование технологий SW.
полное использование технологий SW.
Andreas Langegger "A Flexible Architecture for Virtual Information Integration based on Semantic Web Concepts", 2010
 на распределенные онтологии.масштабируемость относительно количества источников данных и")
Слайд 44Основные понятия языка SPARQL
Шаблоны триплетов – триплет с переменной (?).
Базовый графовый
шаблон (basic graph pattern, BGP) это набор шаблонов триплетов (triple patterns) bgp = (tp1, tp2, . . . , tpn), в котором tpi ∈ TP.
Объединение шаблонов триплетов
семантика связывания (join semantics), если не задана операция между БГШ;
семантика левого соединения (left join semantics), если задано ключевое слово OPTIONAL;
семантика объединения (union semantics), если задано ключевое слово UNION.
Объединение шаблонов триплетов
семантика связывания (join semantics), если не задана операция между БГШ;
семантика левого соединения (left join semantics), если задано ключевое слово OPTIONAL;
семантика объединения (union semantics), если задано ключевое слово UNION.
.Базовый графовый шаблон (basic graph pattern,")
Слайд 45Формы запросов
запрос SELECT - для выбора конкретных элементов (значения вершин или
ребер RDF графа), в результате выполнения получается набор (bag) решающих соответствий (solution mappings).
запрос DESCRIBE - получения любой информации о ресурсах, которые были отобраны с помощью шаблона графа в форме другого RDF графа.
запрос CONSTRUCT может быть использован для построения другого (alternative) графа на основе использования шаблона конструкции (construct template), который заполняется решениями из шаблона графа.
запросы ASK - используются для проверки логического вывода параметризованных подграфов и возвращают true, если существуют возможные решения и false, в противном случае.
запрос DESCRIBE - получения любой информации о ресурсах, которые были отобраны с помощью шаблона графа в форме другого RDF графа.
запрос CONSTRUCT может быть использован для построения другого (alternative) графа на основе использования шаблона конструкции (construct template), который заполняется решениями из шаблона графа.
запросы ASK - используются для проверки логического вывода параметризованных подграфов и возвращают true, если существуют возможные решения и false, в противном случае.
, в")
Слайд 46Алгебраические операторы и
планы запроса
Алгебра языка SPARQL определена в виде
части стандарта (рекомендаций) языка.
Алгебраический оператор p определяется, как кортеж вида (A, P, s)
A - набор аргументов (|A| ≥ 0),
P - набором под-операторов P = (p1, p2, . . . , pn), 0 ≤ |P| ≤ 2,
s - специальный алгоритм, описывающий семантику оператора (например, фильтровать (filter) решения созданные под-оператором p1 в соответствии с выражением a1).
Операторы:
БГШ (самый простой оператор)
Filter (Фильтр),
Join (Соединение),
Optional (Необязательное, левое связывание),
Union (Объединение) и
Graph (Граф).
Модификаторы решений:
Order-by (Упорядочить-по),
Project (Проецировать),
Distinct (Различные),
Reduced (Сокращенный) и
Slice (Нарезать).
Алгебраический оператор p определяется, как кортеж вида (A, P, s)
A - набор аргументов (|A| ≥ 0),
P - набором под-операторов P = (p1, p2, . . . , pn), 0 ≤ |P| ≤ 2,
s - специальный алгоритм, описывающий семантику оператора (например, фильтровать (filter) решения созданные под-оператором p1 в соответствии с выражением a1).
Операторы:
БГШ (самый простой оператор)
Filter (Фильтр),
Join (Соединение),
Optional (Необязательное, левое связывание),
Union (Объединение) и
Graph (Граф).
Модификаторы решений:
Order-by (Упорядочить-по),
Project (Проецировать),
Distinct (Различные),
Reduced (Сокращенный) и
Slice (Нарезать).
 языка.Алгебраический")
Слайд 47
Базовый графовый шаблон можно сравнить с низкоуровневыми операторами выборки, используемыми в
обработке запросов реляционной СУБД. Они являются основой потока работ по обработке запросов, так как все промежуточные решения проходящие через конвейеры обработки запросов создаются на основе Базовых Графовых Шаблонов.
Операторы более высокого уровня объединяют и фильтруют промежуточные решения до тех пор, пока они не будут возвращены подсистемой обработки запросов (query engine) в качестве конечных результатов обработки запроса.
В большинстве реализаций SPARQL, в действительности базовый графовый шаблон связывает промежуточные решения, полученные шаблонами триплетов.
В вычислениях конвейер (канал, pipeline) это набор обрабатывающих данные элементов, которые связаны последовательно, таким образом, чтобы выход одного элемента являлся входом для следующего элемента. Элементы конвейера часто выполняются параллельно или в выделенные интервалы времени в этом случае между элементами часто вставляются некоторые буферы памяти.
Операторы более высокого уровня объединяют и фильтруют промежуточные решения до тех пор, пока они не будут возвращены подсистемой обработки запросов (query engine) в качестве конечных результатов обработки запроса.
В большинстве реализаций SPARQL, в действительности базовый графовый шаблон связывает промежуточные решения, полученные шаблонами триплетов.
В вычислениях конвейер (канал, pipeline) это набор обрабатывающих данные элементов, которые связаны последовательно, таким образом, чтобы выход одного элемента являлся входом для следующего элемента. Элементы конвейера часто выполняются параллельно или в выделенные интервалы времени в этом случае между элементами часто вставляются некоторые буферы памяти.

Слайд 48
БГШ может рассматриваться как конъюнктивный запрос, в котором все шаблоны триплетов
должны быть сопоставлены (соответствовать, match) активному графу.
Он может рассматриваться в качестве эффективного эквивалента связыванию решающих соответствий полученных в результате сопоставления шаблонов триплетов, входящих в БГШ.
При связывании двух решающих последовательностей, все их решающие соответствия попарно сравниваются и совместимые отображения сливаются (объединяются) в единые отображения, в виде результата, который аналогичен семантике SQL связывания .
Он может рассматриваться в качестве эффективного эквивалента связыванию решающих соответствий полученных в результате сопоставления шаблонов триплетов, входящих в БГШ.
При связывании двух решающих последовательностей, все их решающие соответствия попарно сравниваются и совместимые отображения сливаются (объединяются) в единые отображения, в виде результата, который аналогичен семантике SQL связывания .

Слайд 49Системы интеграции информации SemWIQ
Цели разработки системы:
виртуальная интеграция распределенных и разнородных
информационных систем,
использование концепций Semantic Web,
применение подхода, использующего обработку целостного запроса для того, чтобы гарантировать высокую производительность и масштабируемость,
гибкость и низкая начальная стоимость (low entry cost).
использование концепций Semantic Web,
применение подхода, использующего обработку целостного запроса для того, чтобы гарантировать высокую производительность и масштабируемость,
гибкость и низкая начальная стоимость (low entry cost).

Слайд 50Системы интеграции информации SemWIQ
Система SemWIQ способна справится со всеми уровнями разнородности,
включая разнородность метамоделей. В связи с этим, SemWIQ основывается на классическом подходе, использующим посредники-адаптеры:
разнородные источники данных виртуально интегрируются посредством адаптеров и
центральный процессора обработки федеративных запросов (federated query processor) является ответственным за формирование ответов на запросы, путем делегирования (передачи) под-запросов адаптерам.
Процесс обработки запросов (query process) основывается на использовании каналов (pipelining), что позволяет уменьшить время ответа и гарантирует масштабируемость системы путем потоковой передачи результатов через конвейер (pipeline) от исходных информационных систем до отправившего запрос клиента (requesting client).
разнородные источники данных виртуально интегрируются посредством адаптеров и
центральный процессора обработки федеративных запросов (federated query processor) является ответственным за формирование ответов на запросы, путем делегирования (передачи) под-запросов адаптерам.
Процесс обработки запросов (query process) основывается на использовании каналов (pipelining), что позволяет уменьшить время ответа и гарантирует масштабируемость системы путем потоковой передачи результатов через конвейер (pipeline) от исходных информационных систем до отправившего запрос клиента (requesting client).

Слайд 51Основные идеи
Преобразование схем БД в RDFS/OWL - Oi
Объединение локальных онтологий Oi
в глобальную онтологию OG (онтология предметной области).
Формирование отображений Mi
SPARQL точки доступа к БД (адаптеры)
Посредник принимает запросы на языке SPARQL и распределяет их по адаптерам.
Результаты объединяются.
Формирование отображений Mi
SPARQL точки доступа к БД (адаптеры)
Посредник принимает запросы на языке SPARQL и распределяет их по адаптерам.
Результаты объединяются.

Слайд 52Описание системы SemWIQ
Глобальная метамодель (Global metamodel) – в системе SemWIQ в
качестве глобальной метамодели используется RDF.
Глобальный язык запросов (Global query language) – язык SPARQL, может содержать любые понятия онтологий, но однако, запрос будет возвращать результаты только в том случае, если они могут быть получены с помощью глобального виртуального набора данных, т.е. путем объединения предоставляемых виртуальных RDF графов.
Интерфейс и протокол адаптера (Wrapper interface and protocol) – Интерфейсом взаимодействия между адаптерами и посредником является SPARQL.
Каждый адаптер может обрабатывать под-запросы SPARQL и организовывать поток передачи (stream) отображений промежуточных решающих соответствий посреднику (потоковая передача (streaming) результатов обработки SPARQL запросов в XML формате по протоколу HTTP хорошо работает с использованием «Streaming API for XML» (StAX), который используется компонентом Jena ARQ.).
Глобальный язык запросов (Global query language) – язык SPARQL, может содержать любые понятия онтологий, но однако, запрос будет возвращать результаты только в том случае, если они могут быть получены с помощью глобального виртуального набора данных, т.е. путем объединения предоставляемых виртуальных RDF графов.
Интерфейс и протокол адаптера (Wrapper interface and protocol) – Интерфейсом взаимодействия между адаптерами и посредником является SPARQL.
Каждый адаптер может обрабатывать под-запросы SPARQL и организовывать поток передачи (stream) отображений промежуточных решающих соответствий посреднику (потоковая передача (streaming) результатов обработки SPARQL запросов в XML формате по протоколу HTTP хорошо работает с использованием «Streaming API for XML» (StAX), который используется компонентом Jena ARQ.).
 – в системе SemWIQ в качестве глобальной метамодели используется")

Слайд 54Архитектура системы SemWIQ
Интерфейс (Interface)
SPARQL Protocol и RDF Query Language (SPARQL)
.
API для Java приложений (mediator API).
Каталог метаданных (Metadata catalog) – RDF хранилище, которое содержит информацию о зарегистрированных источниках данных (описанную с использованием voiD), их текущее состояние возможности их использования и статистические данные RDFStats (RDFStats statistics).
Такие статистические данные используются для интеграции (federate) и оптимизации глобальных SPARQL запросов.
Данные каталога метаданных могут быть сохранены в любом, основанном на Jena RDF хранилище, но лучше Jena TDB
Система SemWIQ включает много-поточный монитор источников данных, который наблюдает в фоновом режиме за зарегистрированными источниками данных, основываясь на конфигурируемых профайлах и обновляет текущее состояние их доступности (availability state), а также статистические данные RDFStats.
API для Java приложений (mediator API).
Каталог метаданных (Metadata catalog) – RDF хранилище, которое содержит информацию о зарегистрированных источниках данных (описанную с использованием voiD), их текущее состояние возможности их использования и статистические данные RDFStats (RDFStats statistics).
Такие статистические данные используются для интеграции (federate) и оптимизации глобальных SPARQL запросов.
Данные каталога метаданных могут быть сохранены в любом, основанном на Jena RDF хранилище, но лучше Jena TDB
Система SemWIQ включает много-поточный монитор источников данных, который наблюдает в фоновом режиме за зарегистрированными источниками данных, основываясь на конфигурируемых профайлах и обновляет текущее состояние их доступности (availability state), а также статистические данные RDFStats.
 SPARQL Protocol и RDF Query Language (SPARQL) . API для Java")
Слайд 55Архитектура системы SemWIQ (2)
Компонент регистрации (Registry component) – новые источники данных
могут быть зарегистрированы и вычеркнуты (de-registered) в посреднике SemWIQ с помощью registry API и через REST-вида Web-сервис.
Источник данных регистрируется в виде соответствующего URI идентификатора конечной точкой SPARQL предоставляемого соответствующим адаптером.
В ходе регистрации монитор источников данных пытается найти метаданные в формате voiD в web сети, которые могут включать описание системы, которая поддерживает набор данных, лицензионную информацию, и предметные термины, связанные с этим набором данных.
Кроме этого данный монитор собирает статистические данные (RDFStats), если она предоставляются системой (natively provided), а в противном случае он будет использовать встроенный RDFStats компонент (RDFStats component) и генерировать статистические данные удаленно.
Источник данных регистрируется в виде соответствующего URI идентификатора конечной точкой SPARQL предоставляемого соответствующим адаптером.
В ходе регистрации монитор источников данных пытается найти метаданные в формате voiD в web сети, которые могут включать описание системы, которая поддерживает набор данных, лицензионную информацию, и предметные термины, связанные с этим набором данных.
Кроме этого данный монитор собирает статистические данные (RDFStats), если она предоставляются системой (natively provided), а в противном случае он будет использовать встроенный RDFStats компонент (RDFStats component) и генерировать статистические данные удаленно.
Компонент регистрации (Registry component) – новые источники данных могут быть зарегистрированы и")
Слайд 56Архитектура системы SemWIQ (3)
Процессор запросов (Query processor) – процессор обработки запросов
системы SemWIQ получает глобальный SPARQL запрос и
Формирует разделение на под-планы запроса на основе состояния каталога метаданных.
Оптимизация
Выполнение
Адаптеры (Wrappers) – для каждой системы информации источника и соответствующей модели исходных данных используется специфический адаптер для определения отображения и преобразования данных в RDF формат за один шаг.
Формирует разделение на под-планы запроса на основе состояния каталога метаданных.
Оптимизация
Выполнение
Адаптеры (Wrappers) – для каждой системы информации источника и соответствующей модели исходных данных используется специфический адаптер для определения отображения и преобразования данных в RDF формат за один шаг.
Процессор запросов (Query processor) – процессор обработки запросов системы SemWIQ получает глобальный")


Слайд 59Предварительные оптимизации
Фильтры (Filters)
Оператор Filter определяет один аргумент, который является списком выражений
E = (e1, e2, . . . , en), в котором должно быть выполнено каждое отдельное выражение ei (коньюнкция, conjunction).
Шаг 1a) В начале, последовательные операторы Filter в данном плане объединяются путем слияния их списков выражений, т.е. Filter(E1, Filter(E2; q)) -> Filter(E1 ⋃ E2, q).
Шаг 1b) Затем, для каждого оператора Filter, его фильтрующие выражения E сливаются (merged) в единое (single) коньюнктивное фильтрующее выражение (conjunctive filter expression) e’ = e1 ˄ e2 ˄ . . . ˄ en, таким образом, что в конченом результате E’ содержит только одно выражение: E’ = (e’), где |E’| = 1.
Шаг 1c) Закон De Morgan рекурсивно применяется к единому коньюнктивному выражению e’ для расширения выражений !(a ˅ b) в (!a ˄ !b), где a и b являются прямыми или опосредованными подвыражениями (sub-expressions) e’.
Шаг 1d) Аналогично, закон распределения (distributive law) рекурсивно применяется для расширения выражения [a ˅ (b ˄ c)] в [(a ˅ b) ˄ (a ˄ c)], где a и b являются прямыми или опосредованными подвыражениями (sub-expressions) единого выражения e’.
Шаг 1a) В начале, последовательные операторы Filter в данном плане объединяются путем слияния их списков выражений, т.е. Filter(E1, Filter(E2; q)) -> Filter(E1 ⋃ E2, q).
Шаг 1b) Затем, для каждого оператора Filter, его фильтрующие выражения E сливаются (merged) в единое (single) коньюнктивное фильтрующее выражение (conjunctive filter expression) e’ = e1 ˄ e2 ˄ . . . ˄ en, таким образом, что в конченом результате E’ содержит только одно выражение: E’ = (e’), где |E’| = 1.
Шаг 1c) Закон De Morgan рекурсивно применяется к единому коньюнктивному выражению e’ для расширения выражений !(a ˅ b) в (!a ˄ !b), где a и b являются прямыми или опосредованными подвыражениями (sub-expressions) e’.
Шаг 1d) Аналогично, закон распределения (distributive law) рекурсивно применяется для расширения выражения [a ˅ (b ˄ c)] в [(a ˅ b) ˄ (a ˄ c)], где a и b являются прямыми или опосредованными подвыражениями (sub-expressions) единого выражения e’.
Оператор Filter определяет один аргумент, который является списком выражений E = (e1, e2,")
Слайд 60
Шаг 1e) Любые последовательные (consecutive) коньюнкции e1 ˄ e2 ˄ .
. . ˄ en в результирующем выражении разделяются опять на список выражений E = (e1, e2, . . . , en).
Шаг 1f) Теперь когда это возможно, под-выражения ei вставляются (pushed down) в план запроса, как можно ближе к операторам БГШ (BGP operators) в соответствии с правилами описанными ниже (below).
Шаг 1g) При возможности, под-выражения фильтра в формате ei := (v == c), где v это переменная, c – это константный RDF терм (term) ∈ (I ⋃ B ⋃ L), т.е. IRI ссылка (reference), пустая вершина или литерал, вставляются (merged) в базовые графовые шаблоны. Кроме этого, соответствующий БГШ обертывается (wrapped) в оператор Assign, который постоянно вставляется заново (re-inserts) в противном случае отсутствующие связывания v <– c в последовательность решений, которое формируется данным БГШ.
В формальной логике законы De Morgan являются правилами, связывающими логические операции "and" и "or" с помощью операции отрицания, а именно: NOT (P OR Q) = (NOT P) AND (NOT Q) и NOT (P AND Q) = (NOT P) OR (NOT Q).
Фильтрующие Базовые Графовые Шаблоны (Filtered BGPs)
Любой БГШ, который имеет предшествующий Filter окончательно преобразуется в специальный оператор FilteredBGP, который сохраняет ссылку на предшествующий Filter, который требуется для федерирования основанного на RDFStats и последующей оптимизации.
Шаг 1f) Теперь когда это возможно, под-выражения ei вставляются (pushed down) в план запроса, как можно ближе к операторам БГШ (BGP operators) в соответствии с правилами описанными ниже (below).
Шаг 1g) При возможности, под-выражения фильтра в формате ei := (v == c), где v это переменная, c – это константный RDF терм (term) ∈ (I ⋃ B ⋃ L), т.е. IRI ссылка (reference), пустая вершина или литерал, вставляются (merged) в базовые графовые шаблоны. Кроме этого, соответствующий БГШ обертывается (wrapped) в оператор Assign, который постоянно вставляется заново (re-inserts) в противном случае отсутствующие связывания v <– c в последовательность решений, которое формируется данным БГШ.
В формальной логике законы De Morgan являются правилами, связывающими логические операции "and" и "or" с помощью операции отрицания, а именно: NOT (P OR Q) = (NOT P) AND (NOT Q) и NOT (P AND Q) = (NOT P) OR (NOT Q).
Фильтрующие Базовые Графовые Шаблоны (Filtered BGPs)
Любой БГШ, который имеет предшествующий Filter окончательно преобразуется в специальный оператор FilteredBGP, который сохраняет ссылку на предшествующий Filter, который требуется для федерирования основанного на RDFStats и последующей оптимизации.
 Любые последовательные (consecutive) коньюнкции e1 ˄ e2 ˄ . . . ˄ en")
Слайд 61Правила проталкивания фильтров
Для проталкивания фильтров, выражения фильтров подготавливаются, как было описано
выше (например, путем применения законов De Morgan и распределительного закона). Прежде, чем выполнить шаг 1f, для всех операторов Filter имеется список выражений в форме E = (e1, e2, . . . , en) exists.
Для заданного списка выражений, все отдельные выражения ei должны удовлетворяться (satisfied) при оценивании E во время выполнения запроса (execution time). Так как куммутативное свойство (независимость от порядка исполнения, commutativity property) применяется к E, то E может быть разделено на два списка выражений: E = E1 ⋃ E2, то и фильтры могут разделяться, чтобы применять некоторые выражения фильтров пораньше (earlier) в плане запроса.
Проталкивание фильтров было реализовано для операторов Union, Join, LeftJoin и Service. Кроме этого, любые встречающиеся последующие (subsequent) фильтры объединяются (merged) опять, как описано на шаге 1a. В зависимости от вида оператора проталкивание фильтров возможно в соответствии со следующими правилами:
Join: при наличии предшествующего (preceding) фильтра Filter со списком выражений E = (e1, e2, . . . , en), пусть VL = (l1, l2, . . . , ls) это набор переменных возможно связанных в левом под-плане (bound in the left sub-plan), пусть VR = (r1, r2, . . . , rt) это набор переменных возможно связанных в правом под-плане (bound in thr right sub-plan) и пусть L = R = K = ∅.
Для каждого под-выражения ei, решается, может ли оно передано (pushed down) в левый подплан (множество L) и/или правый подплан (множество R), или оно должно быть сохранено в данном месте (множество K). Пусть Ve это множество переменных встречающихся в ei:
L = L ⋃ {ei} если Ve ⊆ VL
R = R ⋃ {ei} если Ve ⊆ VR
K = K ⋃ {ei} если (Ve ⊈ VL) ˄ (Ve ⊈ VR)
Для заданного списка выражений, все отдельные выражения ei должны удовлетворяться (satisfied) при оценивании E во время выполнения запроса (execution time). Так как куммутативное свойство (независимость от порядка исполнения, commutativity property) применяется к E, то E может быть разделено на два списка выражений: E = E1 ⋃ E2, то и фильтры могут разделяться, чтобы применять некоторые выражения фильтров пораньше (earlier) в плане запроса.
Проталкивание фильтров было реализовано для операторов Union, Join, LeftJoin и Service. Кроме этого, любые встречающиеся последующие (subsequent) фильтры объединяются (merged) опять, как описано на шаге 1a. В зависимости от вида оператора проталкивание фильтров возможно в соответствии со следующими правилами:
Join: при наличии предшествующего (preceding) фильтра Filter со списком выражений E = (e1, e2, . . . , en), пусть VL = (l1, l2, . . . , ls) это набор переменных возможно связанных в левом под-плане (bound in the left sub-plan), пусть VR = (r1, r2, . . . , rt) это набор переменных возможно связанных в правом под-плане (bound in thr right sub-plan) и пусть L = R = K = ∅.
Для каждого под-выражения ei, решается, может ли оно передано (pushed down) в левый подплан (множество L) и/или правый подплан (множество R), или оно должно быть сохранено в данном месте (множество K). Пусть Ve это множество переменных встречающихся в ei:
L = L ⋃ {ei} если Ve ⊆ VL
R = R ⋃ {ei} если Ve ⊆ VR
K = K ⋃ {ei} если (Ve ⊈ VL) ˄ (Ve ⊈ VR)

Слайд 62
LeftJoin: при наличии предшествующего (preceding) фильтра Filter со списком выражений E
= (e1, e2, . . . , en), пусть VL = (l1, l2, . . . , ls) это набор переменных возможно связанных в левом под-плане (bound in the left sub-plan), пусть VR = (r1, r2, . . . , rt) это набор переменных возможно связанных в правом под-плане (bound in thr right sub-plan) и пусть L = K = ∅.
Для каждого под-выражения ei, решается, может ли оно передано (pushed down) в левый подплан (множество L) или оно должно быть сохранено в данном месте (множество K). Пусть Ve это множество переменных встречающихся в ei:
L = L ⋃ {ei} если Ve ⊆ VL
K = K ⋃ {ei} если Ve ⊈ VL ˄ (Ve ⊈ VR)
Отметим, что не возможно передать (протолкнуть, push-down) фильтр в правый под-план операции LeftJoin. В противном случае данный фильтр будет применяться к необязательным (optional) связываниям, а не к полному (complete) связанному объединению (joined binding).
Union: при наличии предшествующего (preceding) фильтра Filter со списком выражений E, весь список выражения может копироваться и передаваться (pushed down) в оба под-плана (левый и правый): Filter(E, Union(∅, qL, qR)) становится Union(∅, Filter(E, qL), Filter(E, qR)).
Service: при наличии Filter(E, Service((u), q)), всегда можно передать (push-down) Filter внутрь оператора Service: Service((u), Filter(E, q)).
Для каждого под-выражения ei, решается, может ли оно передано (pushed down) в левый подплан (множество L) или оно должно быть сохранено в данном месте (множество K). Пусть Ve это множество переменных встречающихся в ei:
L = L ⋃ {ei} если Ve ⊆ VL
K = K ⋃ {ei} если Ve ⊈ VL ˄ (Ve ⊈ VR)
Отметим, что не возможно передать (протолкнуть, push-down) фильтр в правый под-план операции LeftJoin. В противном случае данный фильтр будет применяться к необязательным (optional) связываниям, а не к полному (complete) связанному объединению (joined binding).
Union: при наличии предшествующего (preceding) фильтра Filter со списком выражений E, весь список выражения может копироваться и передаваться (pushed down) в оба под-плана (левый и правый): Filter(E, Union(∅, qL, qR)) становится Union(∅, Filter(E, qL), Filter(E, qR)).
Service: при наличии Filter(E, Service((u), q)), всегда можно передать (push-down) Filter внутрь оператора Service: Service((u), Filter(E, q)).
 фильтра Filter со списком выражений E = (e1, e2, .")
Слайд 63Федерирование запроса
Задачей данного федератора (federator) является преобразование плана запроса таким образом,
чтобы ПОЗ могла создать правильные результаты, имея такой виртуальный глобальный граф, как
GG = GS1 ⋃ GS2 ⋃ . . . ⋃ GSn.
Он также может быть представлен в виде большого набора триплетов, которые были виртуально объединены (merged) из всех графов источников:
GG = ( ts1,1, ts1,2, . . . , ts1,k1,
ts2,1, ts2,2, . . . , ts2,k1,
. . .
tsn,1, tsn,2, . . . , tsn,k1,)
Имея шаблон триплета tp (см. Определение 4), федератор должен определить, какой из виртуальных триплетов tsi,kj будет ему соответствовать. Источник данных является релевантным, если граф источника GSi (который является виртуальным в случае источника данных, использующего адаптер ) содержит триплеты, которые соответствуют (match) шаблону триплетов (triple pattern) tp.
Необходимая для этого информация поддерживается компонентом RDFStats в форме сводок статистических данных (statistical data summaries).
Для каждого БГШ федератор создает модифицированный под-план, который содержит операторы Service, чтобы передать локальные планы интерфейсам обработки запросов зарегистрированным источникам данных.
GG = GS1 ⋃ GS2 ⋃ . . . ⋃ GSn.
Он также может быть представлен в виде большого набора триплетов, которые были виртуально объединены (merged) из всех графов источников:
GG = ( ts1,1, ts1,2, . . . , ts1,k1,
ts2,1, ts2,2, . . . , ts2,k1,
. . .
tsn,1, tsn,2, . . . , tsn,k1,)
Имея шаблон триплета tp (см. Определение 4), федератор должен определить, какой из виртуальных триплетов tsi,kj будет ему соответствовать. Источник данных является релевантным, если граф источника GSi (который является виртуальным в случае источника данных, использующего адаптер ) содержит триплеты, которые соответствуют (match) шаблону триплетов (triple pattern) tp.
Необходимая для этого информация поддерживается компонентом RDFStats в форме сводок статистических данных (statistical data summaries).
Для каждого БГШ федератор создает модифицированный под-план, который содержит операторы Service, чтобы передать локальные планы интерфейсам обработки запросов зарегистрированным источникам данных.
 является преобразование плана запроса таким образом, чтобы ПОЗ могла создать")
Слайд 64Пост-оптимизации
Оптимизация фильтров (шаги пред-оптимизации 1f и 1g выполняются заново).
Оптимизация связываний:
Основанный
на ARQ оператор Sequence является специализированным оператором «связывания последовательности» (join sequence), который будет рассматриваться далее. На данном шаге, последовательные (consecutive) операторы Join объединяются в единую последовательность Sequence, которая может иметь n под-операторов, как показано на рис. 9.3.
Операторы Filter, которые предшествуют Join или LeftJoin, опускаются (dropped), а их выражения переносятся (moved) в Join или LeftJoin, создавая theta-joins.
Все операторы Sequence, реализующие left-deep n-way joins теперь оптимизируются путем переупорядочения под-планов на основе стоимостей (cost-based re-ordering of sub-plans).
И, наконец, повторно выполняется шаг 2 из этапа пред-оптимизации (pre-optimization phase).
Наиболее важной частью процессора запросов (query processor) обычно является оптимизация n-направленных связываний (n-way joins), так как они являются наиболее важным фактором, определяющим вычислительную сложность запроса. В связи с коммутативностью (и ассоциативностью (associativity) n-направленных (n-way) связываний (joins), то их можно произвольно переупорядочивать и перебирать альтернативные планы . Самый дешевый для выполнения план может быть определен на оснвое стоимостной модели, которая учитывает много видов элементарных стоимостей (elementary cost), таких, как загрузка страниц в память, выполнение алгоритмов (например, быстрой сортировки) и передачи данных по сетевым соединениям.
Однако, n-направленное связывание уже дает n! возможных перестановок, что делает полный перебор не возможным в общем случае. В связи с этим, многие системы рассматривают только глубокие левые связывания (left-deep joins) которые все равно имеют O(2n) сложность, и используют методы отсечения (pruning techniques) или эволюционные алгоритмы для поиска хороших компромиссов (good compromise) между временем оптимизации и получаемым результатом. Деревья глубоких левых связываний имеют другое важное свойство: они позволяют выполнять конвеерную обработку (pipelining). Кустистые деревья связывания будут позволять выполнять параллельную распределенную обработку запросов. Так как параллельная распределенная обработка запросов потребует дополнительные предусловия для участвующих компонент, а также потому, что система SemWIQ должна быть гибкой и основываться на стандартах Semantic Web, то был использован другой подход, который рассмотрен далее.
Алгоритм, как правило эвристический, относящийся к классу эволюционных методов вычислений. Подмножеством эволюционных алгоритмов являются генетические алгоритмы (genetic algorithm).
Операторы Filter, которые предшествуют Join или LeftJoin, опускаются (dropped), а их выражения переносятся (moved) в Join или LeftJoin, создавая theta-joins.
Все операторы Sequence, реализующие left-deep n-way joins теперь оптимизируются путем переупорядочения под-планов на основе стоимостей (cost-based re-ordering of sub-plans).
И, наконец, повторно выполняется шаг 2 из этапа пред-оптимизации (pre-optimization phase).
Наиболее важной частью процессора запросов (query processor) обычно является оптимизация n-направленных связываний (n-way joins), так как они являются наиболее важным фактором, определяющим вычислительную сложность запроса. В связи с коммутативностью (и ассоциативностью (associativity) n-направленных (n-way) связываний (joins), то их можно произвольно переупорядочивать и перебирать альтернативные планы . Самый дешевый для выполнения план может быть определен на оснвое стоимостной модели, которая учитывает много видов элементарных стоимостей (elementary cost), таких, как загрузка страниц в память, выполнение алгоритмов (например, быстрой сортировки) и передачи данных по сетевым соединениям.
Однако, n-направленное связывание уже дает n! возможных перестановок, что делает полный перебор не возможным в общем случае. В связи с этим, многие системы рассматривают только глубокие левые связывания (left-deep joins) которые все равно имеют O(2n) сложность, и используют методы отсечения (pruning techniques) или эволюционные алгоритмы для поиска хороших компромиссов (good compromise) между временем оптимизации и получаемым результатом. Деревья глубоких левых связываний имеют другое важное свойство: они позволяют выполнять конвеерную обработку (pipelining). Кустистые деревья связывания будут позволять выполнять параллельную распределенную обработку запросов. Так как параллельная распределенная обработка запросов потребует дополнительные предусловия для участвующих компонент, а также потому, что система SemWIQ должна быть гибкой и основываться на стандартах Semantic Web, то был использован другой подход, который рассмотрен далее.
Алгоритм, как правило эвристический, относящийся к классу эволюционных методов вычислений. Подмножеством эволюционных алгоритмов являются генетические алгоритмы (genetic algorithm).
.Оптимизация связываний:Основанный на ARQ оператор Sequence")
Слайд 65Выполнение запроса
После того, как план запроса будет составлен, он может быть
выполнен.
ПОЗ запускает конвейер (канал, pipeline) итераторов , которые далее называются планом выполнения .
Система Jena ARQ уже предоставляет базовую функциональность для потокового выполнения SPARQL запросов и реализует набор итераторов для выполнения потоковых и материализованных (materialized) связываний (joins), левых связываний (left joins), объединений (unions), фильтров (filter) и т.п.
Начальная реализация была расширена поддержкой блокировки записей, распределенными полу-связываниями, отслеживанием происхождения.
ПОЗ запускает конвейер (канал, pipeline) итераторов , которые далее называются планом выполнения .
Система Jena ARQ уже предоставляет базовую функциональность для потокового выполнения SPARQL запросов и реализует набор итераторов для выполнения потоковых и материализованных (materialized) связываний (joins), левых связываний (left joins), объединений (unions), фильтров (filter) и т.п.
Начальная реализация была расширена поддержкой блокировки записей, распределенными полу-связываниями, отслеживанием происхождения.


Слайд 67Алгоритм замещения
Система Jena ARQ основана на подходе динамической оптимизации запросов,
аналогичном исходного оптимизатора СУБД INGRES. В системе ARQ данный подход называется алгоритмом замещения (substitute algorithm), так как в ходе обработки запросов последовательности связываний (join sequences) обрабатывается путем замещения (substituting) переменных в под-планах уже связанными значениями из последующих этапов.
Любое последовательное связывание (consecutive join) заменяется оператором Sequence в ходе выполнения шага 2a пост-оптимизации. Оператор Sequence поддерживает упорядоченный список под-планов и напоминает дерево углубленного левого связывания (left-deep join tree).
Исходный оператор Join был замещен (replaced) оператором Sequence, который имеет два подплана для связывания (join) (в действительности оператор sequence связывает >= 2 под-планов). В примере есть три оператора Service и следовательно три локальных под-планов переданы (delegated) интерфейсу запросов (query interfaces) прикрепленных источнков данных (attached data sources).
План выполнения запроса создается путем перехода (traversing) по плану запроса снизу-вверх (bottom-up) используя визитера (visitor) после выполнения упорядочения (post-order). Визитер (visitor) создает и инициализирует конвейер итераторов (iterator pipeline). Корневым входом (root input) для первого итератора является экземпляр класса QueryIterRoot, который только одно пустое отображение промежуточных решающих соответствий (empty intermediate solution mapping) без связывания переменных: µ0 = { }. Это называется связыванием-идентичностью (join-identity), так как merge(µ0, µk) = µk (см. Определение 8 для слияния (merge)).
В отличие от корневого итератора, первый итератор в данном примере является объектом класса QueryIterBlockedUnion, который расширяет класс QueryIterBlockedRepeatApply, как это показано в диаграмме классов на рис. 9.4. Такой вид итераторов многократно (repeatedly) выполняет полные подпланы для заданного связывания (binding) переданного на входа (input).
Следующий итератор, показанный на рис. 9.6 также имеет поведение повтори-выполни (repeat-apply behavior). Хотя он многократно передает (delegates) Service под-план, повтори-выполни (repeat-apply) оператора Union многократно выполняет множество под-планов и связывает итераторы результирующих планов выполнения.
Любое последовательное связывание (consecutive join) заменяется оператором Sequence в ходе выполнения шага 2a пост-оптимизации. Оператор Sequence поддерживает упорядоченный список под-планов и напоминает дерево углубленного левого связывания (left-deep join tree).
Исходный оператор Join был замещен (replaced) оператором Sequence, который имеет два подплана для связывания (join) (в действительности оператор sequence связывает >= 2 под-планов). В примере есть три оператора Service и следовательно три локальных под-планов переданы (delegated) интерфейсу запросов (query interfaces) прикрепленных источнков данных (attached data sources).
План выполнения запроса создается путем перехода (traversing) по плану запроса снизу-вверх (bottom-up) используя визитера (visitor) после выполнения упорядочения (post-order). Визитер (visitor) создает и инициализирует конвейер итераторов (iterator pipeline). Корневым входом (root input) для первого итератора является экземпляр класса QueryIterRoot, который только одно пустое отображение промежуточных решающих соответствий (empty intermediate solution mapping) без связывания переменных: µ0 = { }. Это называется связыванием-идентичностью (join-identity), так как merge(µ0, µk) = µk (см. Определение 8 для слияния (merge)).
В отличие от корневого итератора, первый итератор в данном примере является объектом класса QueryIterBlockedUnion, который расширяет класс QueryIterBlockedRepeatApply, как это показано в диаграмме классов на рис. 9.4. Такой вид итераторов многократно (repeatedly) выполняет полные подпланы для заданного связывания (binding) переданного на входа (input).
Следующий итератор, показанный на рис. 9.6 также имеет поведение повтори-выполни (repeat-apply behavior). Хотя он многократно передает (delegates) Service под-план, повтори-выполни (repeat-apply) оператора Union многократно выполняет множество под-планов и связывает итераторы результирующих планов выполнения.

Слайд 68Основанный на триплетах федератор
Федератор, основанный на триплетах (triple-based federator) (TF)
может работать с полным разделением экземпляров по набору распределенных источников данных (местоположений, multiple distributed locations) и не типизированных ресурсов (untyped resources). В режиме TF возможно интегрировать полностью распределенные RDF под-графы без ограничений на форму под-графов. Но данный подход требует более распределенных связываний (distributed joins).
Логический пред-оптимизатор уже подготовил план запроса. Все фильтры протолкнуты (pushed down), как можно ближе к базовому графовому шаблону (БГШ). Функция Federate-BGP(b) вызывается из Алгоритма 1 для каждого базового графового шаблона b. Вначале данная функция, выбирается набор (set) предшествующих (preceding) выражений фильтров (filter expressions) E (если b имеет предшествующий Filter, в противном случае E = ∅), и инициализируется отображение (map) PD, которое будет хранить специфические (specific) для источников данных БГ Шаблоны (BGPs).
Для каждого шаблона триплетов t федератор выбирает релевантные (relevant) источники данных D на основе сводок статистических данных. Источник данных является релевантным, если он может добавлять триплеты для данного шаблона t. Соответствующие функции оценивания предоставляются компонентом RDFStats.
Логический пред-оптимизатор уже подготовил план запроса. Все фильтры протолкнуты (pushed down), как можно ближе к базовому графовому шаблону (БГШ). Функция Federate-BGP(b) вызывается из Алгоритма 1 для каждого базового графового шаблона b. Вначале данная функция, выбирается набор (set) предшествующих (preceding) выражений фильтров (filter expressions) E (если b имеет предшествующий Filter, в противном случае E = ∅), и инициализируется отображение (map) PD, которое будет хранить специфические (specific) для источников данных БГ Шаблоны (BGPs).
Для каждого шаблона триплетов t федератор выбирает релевантные (relevant) источники данных D на основе сводок статистических данных. Источник данных является релевантным, если он может добавлять триплеты для данного шаблона t. Соответствующие функции оценивания предоставляются компонентом RDFStats.
 (TF) может работать с полным")
Слайд 69Основанные на экземплярах федераторы
Предполагается, что вся интегрируемая информация организована в
виде множеств экземпляров . Предполагается, что каждый субъект (subject) в глобальном графе GG имеет, по крайней мере, один связанный с ним (associated) тип t (который является классом RDF Schema).
Ограничение 1. GG = (s, p, o), ∀s ∃(s, rdf:type, t)
При установке системе SemWIQ, это условие может быть удовлетворено при отображении источников данных. Если имеется возможность логического вывода включений, то данный подход в основном работает только с нетипизированными ресурсами (задано только rdf:Description)), так как СЛВ будет выводить, что данный ресурс по крайней мере является экземпляром (instance) RDF класса rdfs:Resource. В результате этого, федератор (federator) может рассматривать (consider) большое количество или даже все источники данных, так как rdfs:Resource является наименьшим специфицированным типом (least specific type) для которого все или потенциально все расширения подклассов (sub-class extensions) являются релевантными .
В качестве второго ограничения предполагается, что эти экземпляры описываются только (exclusively) одним источником данных.
Ограничение 2. GSi = (s, p, o), ∀s ∄ GSi = (s, p’, o’)
На основе таких ограничений, глобальный запрос может быть федерирован (federated) на основе набора (sets) экземпляров SPARQL запросов. Вершины с одним и тем же субъектом (equal subject nodes) базового графового шаблона всегда ссылаются на одно и то же множество экземпляры .
Ограничение 1. GG = (s, p, o), ∀s ∃(s, rdf:type, t)
При установке системе SemWIQ, это условие может быть удовлетворено при отображении источников данных. Если имеется возможность логического вывода включений, то данный подход в основном работает только с нетипизированными ресурсами (задано только rdf:Description)), так как СЛВ будет выводить, что данный ресурс по крайней мере является экземпляром (instance) RDF класса rdfs:Resource. В результате этого, федератор (federator) может рассматривать (consider) большое количество или даже все источники данных, так как rdfs:Resource является наименьшим специфицированным типом (least specific type) для которого все или потенциально все расширения подклассов (sub-class extensions) являются релевантными .
В качестве второго ограничения предполагается, что эти экземпляры описываются только (exclusively) одним источником данных.
Ограничение 2. GSi = (s, p, o), ∀s ∄ GSi = (s, p’, o’)
На основе таких ограничений, глобальный запрос может быть федерирован (federated) на основе набора (sets) экземпляров SPARQL запросов. Вершины с одним и тем же субъектом (equal subject nodes) базового графового шаблона всегда ссылаются на одно и то же множество экземпляры .

Слайд 70Адаптеры системы SemWIQ
Система SemWIQ в основном способна интегрировать данные из всех
стандартных конечных точек SPARQL (endpoints). Однако существует несколько проблем с текущим стандартом SPARQL, что делает крупно-масштабную интеграцию на основе стандартys[ конечных точек SPARQL невозможной.
Во-первых, требуется RDF статистика (RDF statistics), чтобы разделять (federate) и оптимизировать запросы к системе SemWIQ queries. Генератор RDFStats статистических данных (statistics) также интегрирован в SemWIQ посредник (mediator), что позволяет создавать статистические данные (statistics) удаленно для наборов данных средних размеров.
Во-вторых, язык SPARQL не поддерживает начальные связывания (initial bindings). В связи с этим невозможна блокировка записей для распределенных связываний.
В связи с этим, несколько компонент Jena, таких, как базовая библиотека Jena (core library), ARQ и Joseki были доработаны (patched), чтобы предоставить требуемую функциональность для адаптеров (wrappers). Каждый SemWIQ адаптер может эффективно обрабатывать SPARQL под-запросы, чтобы добавлять (contribute) решающие соответствия (solution mappings) к результатам глобального запроса.
Во-первых, требуется RDF статистика (RDF statistics), чтобы разделять (federate) и оптимизировать запросы к системе SemWIQ queries. Генератор RDFStats статистических данных (statistics) также интегрирован в SemWIQ посредник (mediator), что позволяет создавать статистические данные (statistics) удаленно для наборов данных средних размеров.
Во-вторых, язык SPARQL не поддерживает начальные связывания (initial bindings). В связи с этим невозможна блокировка записей для распределенных связываний.
В связи с этим, несколько компонент Jena, таких, как базовая библиотека Jena (core library), ARQ и Joseki были доработаны (patched), чтобы предоставить требуемую функциональность для адаптеров (wrappers). Каждый SemWIQ адаптер может эффективно обрабатывать SPARQL под-запросы, чтобы добавлять (contribute) решающие соответствия (solution mappings) к результатам глобального запроса.


 Прямой или одно-этапный подход к отображению/преобразованию")
Слайд 73
Глобальная RDF модель включает (consists of) всю виртуально существующую информацию, которая
была связаны (в единое целое) (отображены, mapped) и онтологические понятия используются для ее описания. Обычно отображения (mappings) связано с так назваемыми словарями , которыми являютя онтологии, содержащие в основном терминологические высказывания (terminological statements) (так называемый T-Box). Обернутая информация обычно является экземпляром данных (instance data), т.е. утверждающие высказывания (assertional statements) (A-Box). Но также возможно связать (map) не терминологические ресурсы или сформировать (generate) TBox высказывания (statements) из экземпляров данных (instance data). Например, источник данных может предоставлять иерархию подклассов на основе реляционных кортежей (relational tuples).
Чтобы связать (map) произвольные модели данных в RDF в основном имеются два подхода, которые рассмотрены в разделе 3.5 (рис. 3.5):
Двухэтапный подход. В этом подходе разнородность метамоделей (metamodel heterogeneity) разрешается отдельно, а затем применяется обычная (traditional) схема соответствия и отображения.Основная проблема с данным подходом состоит в том, что преобразование данных во время выполнения (runtime) и оптимизация запросов является более трудной и вероятно, не всегда возможной.
Одноэтапный подход. В этом подходе используется специальная среда выполнения отображения (specific mapping framework) для каждого конкретного типа исходной метамодели, чтобы дать возможность прямого отображения (direct mapping) и трансляции данных (data translation). В системе SemWIQ все адаптеры основываются на пожходе прямого отображения (direct mapping approach).
Чтобы связать (map) произвольные модели данных в RDF в основном имеются два подхода, которые рассмотрены в разделе 3.5 (рис. 3.5):
Двухэтапный подход. В этом подходе разнородность метамоделей (metamodel heterogeneity) разрешается отдельно, а затем применяется обычная (traditional) схема соответствия и отображения.Основная проблема с данным подходом состоит в том, что преобразование данных во время выполнения (runtime) и оптимизация запросов является более трудной и вероятно, не всегда возможной.
Одноэтапный подход. В этом подходе используется специальная среда выполнения отображения (specific mapping framework) для каждого конкретного типа исходной метамодели, чтобы дать возможность прямого отображения (direct mapping) и трансляции данных (data translation). В системе SemWIQ все адаптеры основываются на пожходе прямого отображения (direct mapping approach).
 всю виртуально существующую информацию, которая была связаны (в единое")
Слайд 74Реализация адаптеров на основе Jena ARQ
Так как Jena ARQ [Jena
Community 2009a] реализована в очень хорошо расширяемым способом (highly extensible manner), то это хорошая способ начинать разработку любых видов виртуальный RDF адаптеров (wrapper).
Имеется много точек расширения (extension points), которые могут быть использованы для того, чтобы добавить требуемую функциональность (hook into) к системе обработки запросов (query engine).
Например, имеется возможность преобразовать сгенерированный алгебраический план (путем реализации интерфейса com.hp.hpl.jena.sparql.algebra.Transform) и заменить стандартные (default) операторы SPARQL собственными (custom) операторами (operators).
Более того, имеется воможность предоставить собственные (custom) реализации итераторов запроса (query iterators), как для стандартных (default), так и собственных (custom) алгебраических операторов (путем переопределения (overriding) метода com.hp.hpl.jena.sparql.engine.main.OpExecutor).
Имеется много точек расширения (extension points), которые могут быть использованы для того, чтобы добавить требуемую функциональность (hook into) к системе обработки запросов (query engine).
Например, имеется возможность преобразовать сгенерированный алгебраический план (путем реализации интерфейса com.hp.hpl.jena.sparql.algebra.Transform) и заменить стандартные (default) операторы SPARQL собственными (custom) операторами (operators).
Более того, имеется воможность предоставить собственные (custom) реализации итераторов запроса (query iterators), как для стандартных (default), так и собственных (custom) алгебраических операторов (путем переопределения (overriding) метода com.hp.hpl.jena.sparql.engine.main.OpExecutor).

Слайд 75
Для реализации адаптера RDB-to-RDF может быть реализован собственный генератор этапов, который
будет формировать решения на основе описания отображений и данных, поучаемых из базы данных путем выполнения SQL запросов.
При наличии шаблона триплетов tpi основной трудностью остается составление правильных и эффективных SQL запросов на основе tpi и отображения (mapping) M, а также преобразование полученных SQL результатов в соответствующие RDF триплеты для tpi.
Сгенерированный SQL запрос, который является комбинацией существующих утверждений об отображении
g ↝ qS,
может рассматриваться, как RDF представление (view) схемы источника S относительно M.
При наличии шаблона триплетов tpi основной трудностью остается составление правильных и эффективных SQL запросов на основе tpi и отображения (mapping) M, а также преобразование полученных SQL результатов в соответствующие RDF триплеты для tpi.
Сгенерированный SQL запрос, который является комбинацией существующих утверждений об отображении
g ↝ qS,
может рассматриваться, как RDF представление (view) схемы источника S относительно M.

Слайд 76Рабочая группа RDB2RDF W3C
В сентябре 2009 года была создана рабочая группа
RDB2RDF W3C Working Group, целью работы которой было “стандартизировать язык для отображения реляционных данных и схем реляционных баз данных в RDF и OWL”.
Такая рабочая группа была сформирована достаточно поздно, так как сервер D2RServer был разработан уже в 2002 году, т.е. семь лет назад.
Увеличение важности масштабируемой технологии отображения RDB-to-RDF привело к созданию в данной области большого количества разных программных средств (инструментов) и разных языков описания отображения (mapping languages).
Для обеспечения взаимодействия между инструментами выполнения отображения, консорциум W3C решил организовать новую рабочую группу для разработки стандартного языка описания отображений (mapping language).
Такая рабочая группа была сформирована достаточно поздно, так как сервер D2RServer был разработан уже в 2002 году, т.е. семь лет назад.
Увеличение важности масштабируемой технологии отображения RDB-to-RDF привело к созданию в данной области большого количества разных программных средств (инструментов) и разных языков описания отображения (mapping languages).
Для обеспечения взаимодействия между инструментами выполнения отображения, консорциум W3C решил организовать новую рабочую группу для разработки стандартного языка описания отображений (mapping language).

Слайд 77Адаптеры для реляционных баз данных
С момента появления концепции Semantic Web
все больше внимания уделяется отображению реляционных БД в RDF и возможности оперативного выполнения запросов и преобразования данных. С уверенностью можно предполагать, что в настоящее время большинство информации хранится в реляционных базах данных.
К современным технологиям разработки адаптеров относятся:
D2RQ-Map [Chris Bizer and Richard Cyganiak 2006],
R2O [Rodrнguez et al. 2004],
OpenLink Virtuoso RDF Views [Erling and Mikhailov 2007],
подходы предложенные в [Chen et al. (2005)] и [de Laborda and Conrad (2006)],
SquirrelRDF [Steer n.d.].
К современным технологиям разработки адаптеров относятся:
D2RQ-Map [Chris Bizer and Richard Cyganiak 2006],
R2O [Rodrнguez et al. 2004],
OpenLink Virtuoso RDF Views [Erling and Mikhailov 2007],
подходы предложенные в [Chen et al. (2005)] и [de Laborda and Conrad (2006)],
SquirrelRDF [Steer n.d.].


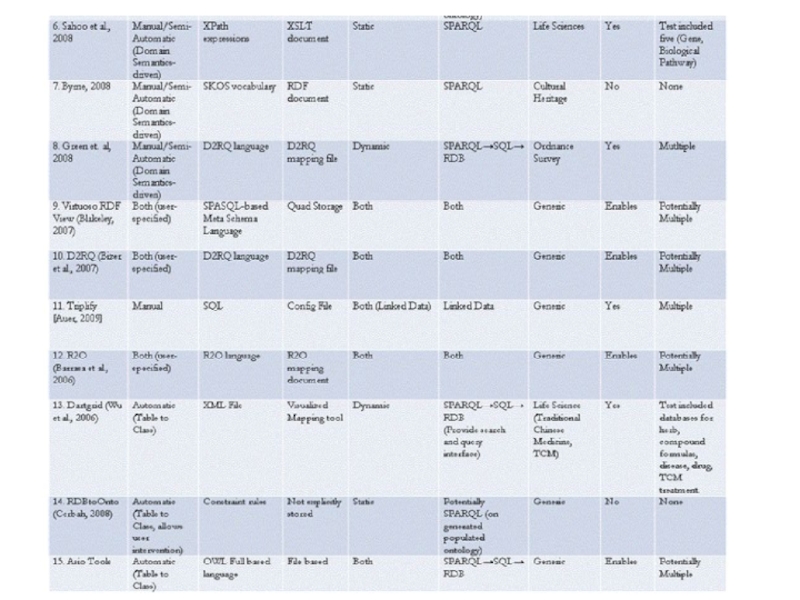
Слайд 80Отображения D2RQ
Система D2RQ-Map является средством отображения и преобразования, которое использует
сервер D2R-Server. Хотя средства отображения могут использоваться в виде библиотеки для приложений Semantic Web, сервер D2R-Server добавляет конечную точку SPARQL (endpoint), которую могут использовать Web приложения и интерфейс пользователя, называемый Snorql. Так как система D2RQ-Map основана на Jena, а также в связи с тем, что имеются хорошие отношения с ее разработчиками, то D2RQ-Map использовалась в качестве реляционного адаптера для системы SemWIQ.
Технология D2RQ-Map основана на Global-as-View подходе к отображению (mapping approach). Однако, составление (writing) отображения D2R является в основном процессом создания утверждений (assertions) в форме: g ↝ qS, как это было описано в разделе 3.5.4. Для отдельного глобального понятия g, которое может быть RDF классом или свойством, описывается (formulated) запрос к qS к схеме базы данных источника (database source schema) S. D2RQ-Map не поддерживает непосредственно SQL запросы, однако, она поддерживает все, что требуется для создания 1 : 1, 1 : n и n : n соответствий, включая функциональные соответствия (основанные на SQL выражениях и функциях), таблицы преобразования значений (value translation tables), и условия (conditions) (с использованием SQL выражений).
Технология D2RQ-Map основана на Global-as-View подходе к отображению (mapping approach). Однако, составление (writing) отображения D2R является в основном процессом создания утверждений (assertions) в форме: g ↝ qS, как это было описано в разделе 3.5.4. Для отдельного глобального понятия g, которое может быть RDF классом или свойством, описывается (formulated) запрос к qS к схеме базы данных источника (database source schema) S. D2RQ-Map не поддерживает непосредственно SQL запросы, однако, она поддерживает все, что требуется для создания 1 : 1, 1 : n и n : n соответствий, включая функциональные соответствия (основанные на SQL выражениях и функциях), таблицы преобразования значений (value translation tables), и условия (conditions) (с использованием SQL выражений).

Слайд 81
Соответствия свойств (мосты свойств, property bridges)) группируются в карты классов (class
maps).
D2RQ-Map следует подходу, основанному на понятиях, в котором в общем случае предполагается, что все результирующие ресурсы (resulting resources) являются экземплярами некоторого RDF класса, хотя также возможно создать не типизированные ресурсы (untyped resources).
Карта классов (class map) может рассматриваться в качестве группы сходных целевых ресурсов, таких, как люди (persons) или документы (documents), которые имеют общие свойства и, в связи с этим, общие мосты свойств.
Сами отображения описываются на RDF, что облегчает обозначение ссылок на внешние RDF понятия онтологий (ontology concepts).
D2RQ-Map следует подходу, основанному на понятиях, в котором в общем случае предполагается, что все результирующие ресурсы (resulting resources) являются экземплярами некоторого RDF класса, хотя также возможно создать не типизированные ресурсы (untyped resources).
Карта классов (class map) может рассматриваться в качестве группы сходных целевых ресурсов, таких, как люди (persons) или документы (documents), которые имеют общие свойства и, в связи с этим, общие мосты свойств.
Сами отображения описываются на RDF, что облегчает обозначение ссылок на внешние RDF понятия онтологий (ontology concepts).
) группируются в карты классов (class maps). D2RQ-Map следует подходу,")
Слайд 82Пример интеграции реляционной базы данных
Используется система интеграции основанная на RDF, двухэтапный
подход.
На первом этапе модель БД (схема БД) преобразуется (translated) в RDF.
На втором этапе, переведенная 1:1 модель базы данных ODB отображается на целевую модель с помощью словаря FOAF.
На первом этапе модель БД (схема БД) преобразуется (translated) в RDF.
На втором этапе, переведенная 1:1 модель базы данных ODB отображается на целевую модель с помощью словаря FOAF.

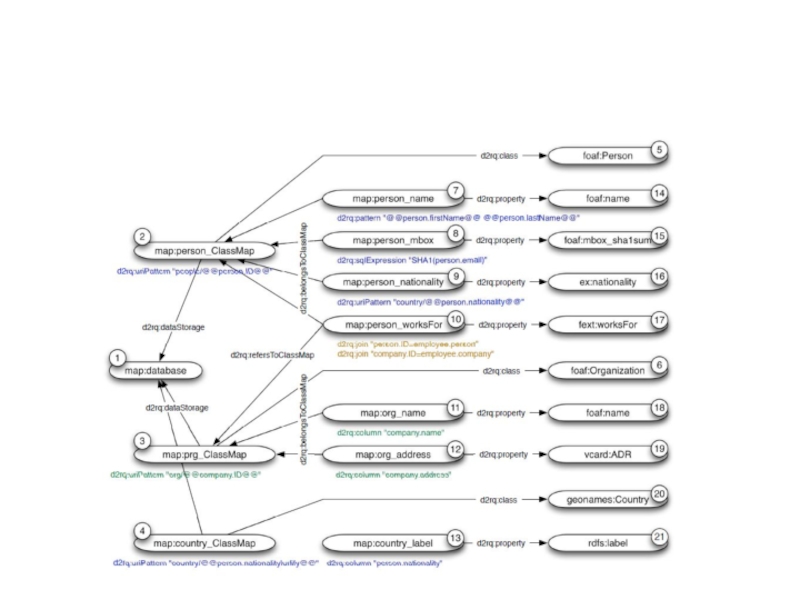
Слайд 84
Отображение D2RQ (mapping) позволяет выполнять одношаговое преобразование во время выполнения (at
runtime) и облегчает использование низкоуровневых индексов и других приемов оптимизации (optimizations) во время обработки запросов (at query time).
Пример отображения в основном состоит из одного ресурса, который является БД (database resource) (1) предоставляющий всю необходимую о соединении (JDBC URI, имя пользователя (username), пароль (password) и т.п.) и три карты классов (class maps) (2–4), ссылающиеся на эту БД (с помощью свойства d2rq:dataStorage).
Для каждого целевого класса (foaf:Person, foaf:Organization и geonames:Country) создана карта класса (class map). Обычно конкретный (concrete) RDF класс назначается (assigned) карте класса с помощью свойства d2rq:class, как показано на рисунке (5, 6, 20). Во время выполнения, D2RQ-Map будет автоматически добавлять соответствующее rdf:type свойство экземплярам карты класса (class map).
Мосты свойств (property bridges) (7–13) ссылаются на конкретные (specific) карты классов (class maps) (с помощью свойства d2rq:belongsToClassMap). Как уже упоминалось, a карта класса (class map) группирует мосты свойств (property bridges) и во время выполнения система (engine) применяет все мосты свойств (associated property bridges) связанные с экземплярами (instances) расширения источника с помощью карты класса (class map’s source extension (кортежи связанной таблицы базы данных). В зависимости от шаблона запроса, каждый описанный мост свойств (property bridge) может генерировать возможные (potential) RDF триплеты с ранее определенным RDF свойством, заданным с помощью d2rq:property, как показано с правой стороны рис. 10.2 (14–21).
Мост свойства может рассматриваться в качестве шаблона виртуального утверждения, который в системе D2RQ называется триплетным отношением. Он может быть определен в виде триплета (s’, pi, o’), в котором pi заранее описано (defined) данным мостом свойства, а s’, o’ задаются во время выполнения.
Пример отображения в основном состоит из одного ресурса, который является БД (database resource) (1) предоставляющий всю необходимую о соединении (JDBC URI, имя пользователя (username), пароль (password) и т.п.) и три карты классов (class maps) (2–4), ссылающиеся на эту БД (с помощью свойства d2rq:dataStorage).
Для каждого целевого класса (foaf:Person, foaf:Organization и geonames:Country) создана карта класса (class map). Обычно конкретный (concrete) RDF класс назначается (assigned) карте класса с помощью свойства d2rq:class, как показано на рисунке (5, 6, 20). Во время выполнения, D2RQ-Map будет автоматически добавлять соответствующее rdf:type свойство экземплярам карты класса (class map).
Мосты свойств (property bridges) (7–13) ссылаются на конкретные (specific) карты классов (class maps) (с помощью свойства d2rq:belongsToClassMap). Как уже упоминалось, a карта класса (class map) группирует мосты свойств (property bridges) и во время выполнения система (engine) применяет все мосты свойств (associated property bridges) связанные с экземплярами (instances) расширения источника с помощью карты класса (class map’s source extension (кортежи связанной таблицы базы данных). В зависимости от шаблона запроса, каждый описанный мост свойств (property bridge) может генерировать возможные (potential) RDF триплеты с ранее определенным RDF свойством, заданным с помощью d2rq:property, как показано с правой стороны рис. 10.2 (14–21).
Мост свойства может рассматриваться в качестве шаблона виртуального утверждения, который в системе D2RQ называется триплетным отношением. Он может быть определен в виде триплета (s’, pi, o’), в котором pi заранее описано (defined) данным мостом свойства, а s’, o’ задаются во время выполнения.
 позволяет выполнять одношаговое преобразование во время выполнения (at runtime) и облегчает использование")
Слайд 85SPARQL запрос и соответствующий ему план запроса D2RQ
Как видно из данного
примера, вместо OpBGP операторов, план запроса содержит OpD2RQ операторы, которые генерируют SQL подпланы и выполняют связывания решений (solution bindings) на основе описания отображений.


Слайд 87Возможности системы D2RQ-Map
Система D2RQ-Map использует достаточно мощные возможности (формирования) отображения,
которые могут справиться (cope) со следующими видами (aspects) разнородности .
Техническая разнородность неявно разрешается (совместно с другими видами) путем выполнения доступа к лежащей в основе базе данных через SQL и JDBC и путем предоставления интерфейса SPARQL interface to the user.
Синтаксическая разнородность может разрешаться путем использования SQL выражений (expressions) и таблиц перевода (translation tables).
Разрешение разнородности метамоделей между реляционной моделью и RDF является назначением самой системы D2RQ-Map.
Структурная разнородность может быть разрешена в большинстве случаев. Информация о схеме базы данных может быть представлена в RDF, если RDBMS предоставляет доступ каталогу метаданных посредство SQL запросов. И наоборот, может быть сгенерирована структура любого RDF графа, включая классы, свойства и частные типы данных RDF и т.п.
Техническая разнородность неявно разрешается (совместно с другими видами) путем выполнения доступа к лежащей в основе базе данных через SQL и JDBC и путем предоставления интерфейса SPARQL interface to the user.
Синтаксическая разнородность может разрешаться путем использования SQL выражений (expressions) и таблиц перевода (translation tables).
Разрешение разнородности метамоделей между реляционной моделью и RDF является назначением самой системы D2RQ-Map.
Структурная разнородность может быть разрешена в большинстве случаев. Информация о схеме базы данных может быть представлена в RDF, если RDBMS предоставляет доступ каталогу метаданных посредство SQL запросов. И наоборот, может быть сгенерирована структура любого RDF графа, включая классы, свойства и частные типы данных RDF и т.п.
 отображения, которые могут справиться (cope)")
Слайд 88
Соответствия (correspondences) 1 : 1, 1 : n, n : 1
и n : n:
соответствие 1 : n может быть достигнуто с помощью множественных соответствий вместе с условиями (d2rq:condition),
соответствие n : 1 может быть достигнуто с помощью SQL выражений (например, объединение имени (first) и фамилии (last name) людей (people)).
соответствие n : n может быть создано с помощью объединения этих двух подходов.
Семантическая разнородность неявно разрешается путем отображения (mapping) на хорошо структурированные и обще доступные RDF онтологии. Перевод на основе значений может быть выполнено с помощью таблиц перевода.
соответствие 1 : n может быть достигнуто с помощью множественных соответствий вместе с условиями (d2rq:condition),
соответствие n : 1 может быть достигнуто с помощью SQL выражений (например, объединение имени (first) и фамилии (last name) людей (people)).
соответствие n : n может быть создано с помощью объединения этих двух подходов.
Семантическая разнородность неявно разрешается путем отображения (mapping) на хорошо структурированные и обще доступные RDF онтологии. Перевод на основе значений может быть выполнено с помощью таблиц перевода.
 1 : 1, 1 : n, n : 1 и n : n:")