- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Методы и средства исследования и оптимизации процессов. Основные понятия презентация
Содержание
- 1. Методы и средства исследования и оптимизации процессов. Основные понятия
- 2. Оптимизируются те или иные объекты. Для
- 3. При исследовании объекта применяют аналитические методы, т.
- 4. Таким образом, модель процесса бурения –
- 5. Сущность математического описания объекта (системы) или
- 6. Основной характеристикой объекта исследований является его
- 7. простой объект – такой объект, при
- 8. Сложный объект – это объект, при
- 9. Данные – результаты некоторого количества измерений
- 11. наблюдение ВЫБОРКА Генеральная совокупность = популяция –
- 12. Выборка должна быть репрезентативной, т.е. её свойства
- 13. Три основные концепции в анализе данных:
- 14. Переменные Количественные Ранговые ordinal (качественные, но
- 15. шкала отношений (ratio scale): размер интервалов на
- 16. Частотное распределение переменной (frequency distribution) – это
- 17. Частотное распределение переменной (frequency distribution) Картинка распределения
- 18. Частотное распределение количественной переменной Взвешиваем N кроликов
- 19. Частотное распределение количественной переменной Упорядочим по возрастанию
- 20. Гистограмма – графическое представление частотного распределения, разбитого
- 21. Частотное распределение переменной
- 22. Три ОСНОВНЫЕ ХАРАКТЕРИСТИКИ, которыми можно почти полностью
- 23. «Середина» распределения (central tendency) «Середина» Мода (mode)
- 24. Частотное распределение переменной «Середина» распределения Среднее значение
- 25. Частотное распределение переменной «Середина» распределения Медиана (median)–
- 26. Если распределение не симметричное, медиана лучше
- 27. Частотное распределение переменной Квартили (quartiles) делят распределение
- 29. Мода (mode) – наиболее часто встречающееся значение,
- 30. Частотное распределение переменной «Середина» распределения Мода, медиана
- 31. Для публикаций Традиционно, для выборки приводят среднее
- 32. Частотное распределение переменной «Ширина» распределения = Разброс*
- 33. Стандартное отклонение (standard deviation) Частотное распределение переменной
- 34. Частотное распределение переменной Разброс распределения Дисперсия (variance)
- 35. Коэффициент вариации (Coefficient of variation) Частотное распределение
- 36. Параметры разброса для качественных данных: Индексы разнообразия
- 37. Для публикаций Традиционно, вместе со средним
- 38. Частотное распределение переменной По ФОРМЕ распределения различаются:
- 39. Частотное распределение переменной По признаку симметрии:
- 40. Частотное распределение переменной 3. распределение асимптотическое не асимптотическое По ФОРМЕ распределения различаются:
- 41. Частотное распределение переменной Нормальное распределение (Гауссово): первое
- 42. Стандартное отклонение (standard deviation): для нормального распределения
- 43. Частотное распределение переменной «Площадь распределения» Площадь, которую
- 44. Частотное распределение переменной Процентили и z-оценка (standard
- 45. Частотное распределение переменной Процентили и z-оценка (standard
- 46. Частотное распределение переменной Площадь нормального распределения Нормальное
- 47. Частотное распределение переменной Площадь нормального распределения Z-оценка
- 48. Частотное распределение переменной Площадь нормального распределения
- 49. Площадь нормального распределения
- 50. Распределение выборочных средних (sampling distribution of the
- 51. Распределение выборочных средних Что мы можем сказать
- 52. Распределение выборочных средних Мы посчитали средние массы
- 53. Распределение выборочных средних Распределение
- 54. Распределение выборочных средних ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА
- 55. Распределение выборочных средних Следствие: если некоторая величина
- 56. Распределение выборочных средних Масса кролика определяет многими
- 57. Распределение выборочных средних У нас есть одна
- 58. Распределение выборочных средних Вопрос: какая часть ОСОБЕЙ
- 59. Оценка параметров популяции на основе свойств выборки
- 60. Оценка параметров популяции на основе свойств выборки
- 61. Оценка параметров популяции на основе свойств выборки
- 62. Оценка параметров популяции на основе свойств выборки
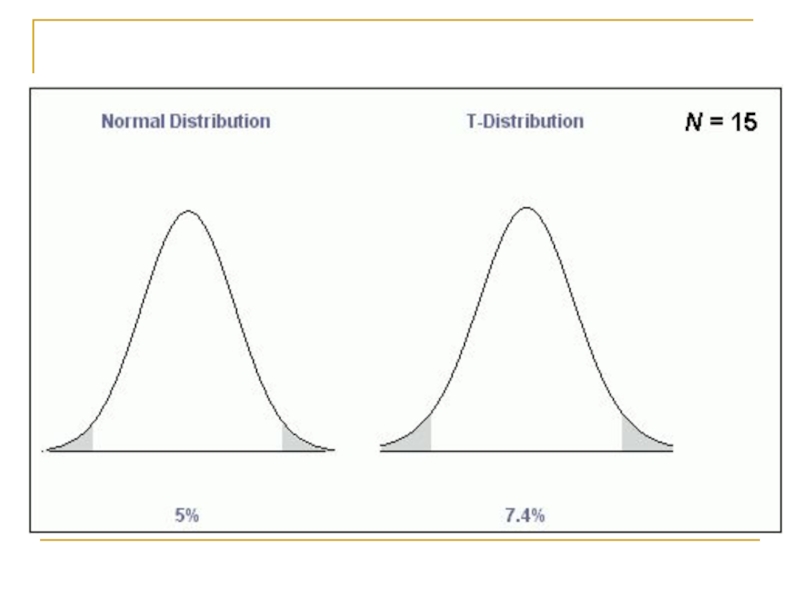
- 63. t-распределение (Стьюдента) df=k При больших (>30) размерах выборок приближается к нормальному
- 65. иногда стандартную ошибку среднего приводят как
- 66. В чём ошибки?
- 67. Темы занятий (2015 год) 1. Основные
Слайд 1Методы и средства исследования и оптимизации процессов .
Основные понятия.
Фролова Мария Сагитовна
marsag@list.ru

Слайд 2
Оптимизируются те или иные объекты. Для оптимизации объекта следует иметь об
Априорная информация – уровень достоверной информации об объекте исследования, позволяющей построить модель того или иного уровня детализации и достоверности.

Слайд 3При исследовании объекта применяют аналитические методы, т. е. методы, основанные на
По определению Е.А. Козловского «Математическая модель процесса бурения представляет собой динамическую аналогию данного объекта с нетождественным подобием свойств».

Слайд 4
Таким образом, модель процесса бурения – воспроизведенный в той или иной
Результаты исследования могут быть представлены в виде таблиц, график и уравнений, т.е. математическое описание технологического процесса.

Слайд 5
Сущность математического описания объекта (системы) или процесса заключается в получении математической
Y = F{X},
где Y – сов-ть выходных параметров процесса, которые определяют свойства выходящего продукта.
Х – совокупность выходных параметров (факторов), определяющих характеристики процесса (объекта) и свойства входящего материала (продукта).
F{X} – символ, называемый оператором, который характеризует математическую модель объекта или системы.
 или процесса заключается в получении математической модели или соотношения, связывающего")
Слайд 6
Основной характеристикой объекта исследований является его сложность. Она определяется количеством разнообразия,
Простой объект – это такой объект, в котором изменение влияющих факторов приводит к предсказуемому изменению выходных данных. Как правило, подобное может происходить только на определенном ограниченном интервале изменения влияющих факторов.

Слайд 7
простой объект – такой объект, при функционировании которого выходной параметр (скорость
 изменяется под влиянием")
Слайд 8
Сложный объект – это объект, при функционировании которого под влиянием факторов
Система объектов может включать несколько отдельных «блоков», каждый из которых является сложным объектом.
Пример. Работа бурового агрегата, как система объектов, включает:
– работу бурового инструмента, осуществляющего углубку забоя;
– работу бурильной колонны, передающей буровому инструменту
крутящий момент, осевую нагрузку и промывочную жидкость;
– работу бурового станка;
– работу бурового насоса.

Слайд 9
Данные – результаты некоторого количества измерений какой-либо ПЕРЕМЕННОЙ (переменных) – variable.
вес, длина тела, пол, окрас, температура .....
Статистика – инструмент для количественного анализа и интерпретации данных
Как проверить истинность суждений о свойствах окружающего мира?
 – variable. Например: вес, длина тела,")

Слайд 11наблюдение
ВЫБОРКА
Генеральная совокупность = популяция – совокупность всех интересующих нас объектов
Описательная (descriptive)
Индуктивная (inferential) статистика : на основе свойств выборки (параметров выборки) делаем заключения о СВОЙСТВАХ ГЕНЕРАЛЬНОЙ СОВОКУПНОСТИ (популяции).
 статистика : ОПИСЫВАЕМ ВЫБОРКУИндуктивная")
Слайд 12Выборка должна быть репрезентативной, т.е. её свойства должны ОТРАЖАТЬ СВОЙСТВА ПОПУЛЯЦИИ.
Для
Dr. Nostat сформировал выборки для эксперимента; в одну поместил зверьков, которые первыми вышли из клетки, а в другую – тех, кто в ней остался

Слайд 13Три основные концепции в анализе данных:
Что такое РАСПРЕДЕЛЕНИЕ ПЕРЕМЕННОЙ и как
Что такое распределение ВЫБОРОЧНЫХ СРЕДНИХ и как оно связано с распределением переменной
Что такое СТАТИСТИКА КРИТЕРИЯ
Необходимо для обдумывания и обсуждения данных

Слайд 14Переменные
Количественные
Ранговые
ordinal
(качественные, но могут быть упорядочены; размер интервалов на шкале неодинаковый)
Качественные
nominal
Дискретные
discrete
Непрерывные
continuous
шкала
интервальная шкала
interval scale
(в.т.ч круговые шкалы)
(их нельзя выстроить в последовательность)
Потеря информации и точности
Переменная – характеристика окружающего мира, которую мы измеряем
КачественныеnominalДискретныеdiscreteНепрерывныеcontinuousшкала отношений ratio scaleинтервальная шкалаinterval")
Слайд 15шкала отношений (ratio scale):
размер интервалов на протяжении всей шкалы одинаковый;
существует реальное
Примеры: масса тела, размер выводка, объём, температура по Кельвину
интервальная шкала (interval scale):
размер интервалов на протяжении всей шкалы одинаковый;
положение нулевой точки выбрано произвольно.
Примеры: температура по Цельсию, время дня, дата
:размер интервалов на протяжении всей шкалы одинаковый;существует реальное нулевое значение.Примеры: масса тела,")
Слайд 16Частотное распределение переменной (frequency distribution) – это соответствие между значениями переменной
Рассмотрение частотного распределения облегчает обдумывание и обсуждение данных
Можно представить в виде таблички или картинки.
 – это соответствие между значениями переменной и их вероятностями (на")
Слайд 17Частотное распределение переменной (frequency distribution)
Картинка распределения КАЧЕСТВЕННЫХ или ранговых переменных (bar
Оставим на некоторое время качественные и ранговые переменные и обратимся только к КОЛИЧЕСТВЕННЫМ
промежутки между столбиками
Картинка распределения КАЧЕСТВЕННЫХ или ранговых переменных (bar graph). Столбчатая диаграмма («гистограмма»")

Слайд 19Частотное распределение количественной переменной
Упорядочим по возрастанию значения переменной (выстроим кроликов от
разобьём их на группы по равным интервалам.
;разобьём их")
Слайд 20Гистограмма – графическое представление частотного распределения, разбитого по интервалам, где высота
Частотное распределение количественной переменной
Частота – то, сколько раз встретилось данное значение переменной
Интервалы должны быть:
одного размера,
не должны иметь общих точек,
для биологических данных – 10-20 интервалов
Полигон частот (frequency polygon)


Слайд 22Три ОСНОВНЫЕ ХАРАКТЕРИСТИКИ, которыми можно почти полностью описать большинство распределений
«Середина» распределения;
«Ширина»
Форма распределения
Как описать частотное распределение переменной?
Речь идёт не только о количественных данных, но и о качественных

Слайд 23«Середина» распределения (central tendency)
«Середина»
Мода
(mode)
Медиана (median)
Среднее значение (mean)
Разница понятий parameter и statistic
Все
Среднее в выборке – наиболее эффективная и несмещённая оценка.
«Середина»Мода(mode)Медиана (median)Среднее значение (mean)Разница понятий parameter и statisticВсе они могут служить оценками")
Слайд 24Частотное распределение переменной
«Середина» распределения
Среднее значение – сумма всех значений переменной, делённая
*«balancing point» method
Среднее для выборки
Среднее для популяции

Слайд 25Частотное распределение переменной
«Середина» распределения
Медиана (median)– значение, которое делит распределение пополам (его
1,0
1,5
4,1
5,7
9,5
6,0
7,1
7,9
10,4
11,0
Медиана
Имеет смысл не только для количественных переменных, но и для ранговых! (не для качественных).
3,2
– значение, которое делит распределение пополам (его площадь в т.ч.): половина")
Слайд 26 Если распределение не симметричное, медиана лучше характеризует центр распределения.
она
но зато она не чувствительна к «аутлаерам» и может применяться даже в случае, если не для всех особей измерения точные.
Распределение можно поделить не только на ДВЕ равные части, но и на:
четыре (значения, стоящие на границах - квартили);
восемь (... октили);
сто (... процентили);
N (... квантили).
Частотное распределение переменной

Слайд 27Частотное распределение переменной
Квартили (quartiles) делят распределение на четыре части так, что
1-я квартиль = 25% процентиль
3-я квартиль = 75% процентиль
Интерквартильный размах – разница между третьей и первой квартилями.
Пример про 500 р и магазин
 делят распределение на четыре части так, что в каждой из них")
Слайд 28
Квартиль 1
Квартиль 3
медиана
Частота
Значение переменной
25%
25%
25%
25%
Частотное распределение переменной

Слайд 29Мода (mode) – наиболее часто встречающееся значение, локальный максимум
Частотное распределение переменной
«Середина»
Существует не только для количественных, но и для ранговых, и для качественных переменных
В первую очередь биолога интересует количество мод в распределении, а не мода как таковая. Если мода не одна, наверняка выборка может быть поделена на группы
 – наиболее часто встречающееся значение, локальный максимумЧастотное распределение переменной«Середина» распределенияСуществует не только для")
Слайд 30Частотное распределение переменной
«Середина» распределения
Мода, медиана и среднее СОВПАДАЮТ для симметричного унимодального
К появлению перекоса чувствительнее всего среднее значение
1/3
2/3

Слайд 31Для публикаций
Традиционно, для выборки приводят среднее значение (mean) – удобно для
Если распределение скошенное, дополнительно приводят медиану (М);
Моду не приводят, иногда бывает важно упомянуть, сколько в распределении мод.
 – удобно для сравнения с литературой и")
Слайд 32Частотное распределение переменной
«Ширина» распределения = Разброс*
Размах
(range)
Стандартное отклонение (standard deviation)
Дисперсия (variance)
* Это
Размах (range) – разность между максимальным и минимальным значениями = Xn – X1
Хорош тем, что легко считается и имеет «биологический смысл».
Плох тем, что зависит лишь от 2-х точек из распределения. Недооценивает истинный размах в популяции.
Стандартное отклонение (standard deviation)Дисперсия (variance)* Это лишь основные параметры разбросаРазмах")
Слайд 33Стандартное отклонение (standard deviation)
Частотное распределение переменной
Разброс распределения
Для выборки:
Для популяции:
Поправка на то,
Стандартное отклонение зависит ото всех значений переменной.
Измеряется в тех же единицах, что и переменная!
Частотное распределение переменнойРазброс распределенияДля выборки:Для популяции:Поправка на то, что в выборке разброс")
Слайд 34Частотное распределение переменной
Разброс распределения
Дисперсия (variance)
Для выборки:
Для популяции:
Равна стандартному отклонению в квадрате
Дисперсия используется скорее в различных статистических тестах, а не в описательной статистике
Для выборки:Для популяции:Равна стандартному отклонению в квадрате и содержит почти ту")
Слайд 35Коэффициент вариации
(Coefficient of variation)
Частотное распределение переменной
Разброс распределения
Даёт понять, насколько на самом
Не годится для данных, измеренных по интервальной шкале (температура, время и пр.)
Частотное распределение переменнойРазброс распределенияДаёт понять, насколько на самом деле велик разброс в")
Слайд 36Параметры разброса для качественных данных:
Индексы разнообразия (indices of diversity)
Показывают, насколько равномерно
Индекс Шеннона-Винера
p = доля объектов в той или иной категории;
k – число категорий.
Нормированный индекс Шеннона ( )
Этих индексов много для разных целей; это показатели ОПИСАТЕЛЬНОЙ статистики!
Показывают, насколько равномерно данные распределены по категориям.")
Слайд 37Для публикаций
Традиционно, вместе со средним значением приводят стандартное отклонение (±SD);
Коэффициент вариации приводят, если хотят сравнить разброс в разных по характеру данных.
Для публикаций
Традиционно, вместе со средним значением приводят стандартное отклонение (±SD);
Иногда в статье приводится размах, но в дополнение следует привести ещё какую-нибудь характеристику разброса.;
Коэффициент вариации приводят, если хотят сравнить разброс в разных по характеру данных.
Для публикаций
; Иногда в статье приводится")
Слайд 38Частотное распределение переменной
По ФОРМЕ распределения различаются:
По количеству «максимумов» (мод):
унимодальное
бимодальное
мультимодальное
обычно возникают, если
:унимодальноебимодальноемультимодальноеобычно возникают, если популяция имеет естественные обособленные подгруппы")
Слайд 39Частотное распределение переменной
По признаку симметрии:
Симметричное
Скошенное (skewed)
вправо (positively)
влево negatively
По ФОРМЕ распределения различаются:
вправо (positively)влево negativelyПо ФОРМЕ распределения различаются:")
Слайд 40Частотное распределение переменной
3. распределение
асимптотическое
не асимптотическое
По ФОРМЕ распределения различаются:

Слайд 41Частотное распределение переменной
Нормальное распределение (Гауссово):
первое знакомство
Унимодальное
Симметричное
Асимптотическое
Высота деревьев, масса
Это непрерывное распределение
Название в честь Гаусса не совсем справедливо – первым его описал вовсе не он.
Симметрия и эксцесс.
:первое знакомство Унимодальное Симметричное АсимптотическоеВысота деревьев, масса тела новорожденных, IQ, скорость")
Слайд 42Стандартное отклонение (standard deviation):
для нормального распределения = дистанции от среднего значения
Частотное распределение переменной
:для нормального распределения = дистанции от среднего значения до каждой из точек")
Слайд 43Частотное распределение переменной
«Площадь распределения»
Площадь, которую занимает график распределения, соответствует количеству измерений
Отрезая часть распределения на графике, мы отделяем эквивалентную часть от выборки
частота
масса, кг
16% площади распределения ~ 16% объёма выборки

Слайд 44Частотное распределение переменной
Процентили и z-оценка (standard score)
95% процентиль – значение переменной,
95%
95% процентиль – значение переменной, левее которого находится 95%")
Слайд 45Частотное распределение переменной
Процентили и z-оценка (standard score)
Z-оценка (z-scores) – переменная, соответствующая
выборка
популяция
Z-оценка (z-scores) – переменная, соответствующая количеству стандартных отклонений от")
Слайд 46Частотное распределение переменной
Площадь нормального распределения
Нормальное распределение определяется лишь 2-мя параметрами –
Необыкновенное свойство:
Относительные площади нормального распределения над одинаковым количеством стандартных отклонений всегда одинаковы!

Слайд 47Частотное распределение переменной
Площадь нормального распределения
Z-оценка
(количество стандартных отклонений)
Откладывая от среднего значения стандартное
Пример с IQ (μ=100, σ=15)
Откладывая от среднего значения стандартное отклонение (в ту или")


Слайд 50Распределение выборочных средних (sampling distribution of the means)
Три основные концепции в
Что такое РАСПРЕДЕЛЕНИЕ переменной и как его описывать
Что такое распределение ВЫБОРОЧНЫХ СРЕДНИХ и как оно связано с распределением переменной
Что такое СТАТИСТИКА КРИТЕРИЯ
выборка
популяция
Три основные концепции в анализе данных:Что такое РАСПРЕДЕЛЕНИЕ")
Слайд 51Распределение выборочных средних
Что мы можем сказать обо всей ПОПУЛЯЦИИ, если всё,
На 1-м курсе института 25 групп по 22 студента.
Предположим, средняя масса студента – μ=50 кг, σ = 4 кг, а группы – случайные выборки студентов.
Трудно ожидать, что и в каждой группе средняя масса будет 50 кг!
Выборки не обязательно должны удовлетворять критериям нормального распределения. Про IQ
…..

Слайд 52Распределение выборочных средних
Мы посчитали средние массы студентов в КАЖДОЙ группе, и
50
5
55
60
45
40
50
1.2
Его среднее будет близко популяционному среднему, и оно будет намного УЖЕ распределения всех студентов, и УЖЕ, чем каждое из распределений выборок
Это и будет распределение выборочных средних (sampling distribution of the means)
Пример про бутылки с кока-колой

Слайд 53Распределение выборочных средних
Распределение выборочных средних
Выборка
(группа)
Популяция (все студенты)
Чтобы уменьшить ошибку
Популяция (все студенты)Чтобы уменьшить ошибку среднего, можно либо уменьшить")
Слайд 54Распределение выборочных средних
ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА
Определяет форму, среднее и разброс в
Пример с монеткой

Слайд 55Распределение выборочных средних
Следствие:
если некоторая величина отклоняется от среднего под воздействием слабых,

Слайд 56Распределение выборочных средних
Масса кролика определяет многими факторами:
Генотип – 7 кг
Питание –
Уход и любовь хозяина – 25 кг
Внутриутробные условия – 5 кг
Качество вскармливания мамой – 8 кг
Т.е., масса кролика – среднее по выборке многих гипотетических масс. А массы нескольких кроликов – выборочные средние

Слайд 57Распределение выборочных средних
У нас есть одна выборка. Из неё мы получили
Насколько оно близко среднему значению в популяции (μ)?
Мы знаем, что для нормального распределения есть z-оценка, значениям которой соответствуют определённые площади распределения.
Но мы также знаем, что выборочные средние образуют нормальное распределение!!
Это значит, что, зная среднее в популяции, мы можем рассчитать интервал, в который попадёт выборочное среднее с вероятностью, скажем, в 95% (или 99%).
Решим обратную задачу. Пусть нам известно μ, найдём
Как оценить популяционное среднее имея выборку?

Слайд 58Распределение выборочных средних
Вопрос: какая часть ОСОБЕЙ имеет массу больше 55 кг?
Другой

Слайд 59Оценка параметров популяции на основе свойств выборки
Пусть мы изначально знаем среднюю
Построим распределение выборочных средних! Вспомним, что оно – нормальное, а его среднее значение соответствует среднему в популяции.
Зная стандартное отклонение в нем (=SE!!) можем рассчитать интервал, в который попадёт 95% (99%) всех средних масс в группах:

Слайд 60Оценка параметров популяции на основе свойств выборки
95% доверительный интервал (95% confidence
Т.е., расстояние от среднего значения в популяции до выборочного среднего для 95% выборок не больше 1.96 SE
Вернёмся к исходной задаче:
Как оценить среднюю массу в популяции, если нам известно среднее в выборке??
Расстояние от среднего в выборке до (неизвестного) среднего в популяции с вероятностью 95% не больше 1.96 SE
cv – critical value, критическое значение статистики (в данном случае, Z) – грубо говоря, вероятность ошибки.
: интервал значений переменной,")
Слайд 61Оценка параметров популяции на основе свойств выборки
Вопрос: где расположено μ?
Ответ: я
Чем больше уровень достоверности – 99%, 99,9%... (= доверительный уровень) тем ШИРЕ будет интервал
Вопрос: где расположено μ?
Ответ: я совершенно уверен, что оно лежит в пределах... от до
В примере нам было известно σ, но на практике оно обычно неизвестно!

Слайд 62Оценка параметров популяции на основе свойств выборки
Мы не знаем стандартное отклонение
Насколько шире? Это будет зависеть от РАЗМЕРА ВЫБОРКИ (от числа степеней свободы df = n-1)
df
Пояснить про число степеней свободы

Слайд 63t-распределение (Стьюдента)
df=k
При больших (>30) размерах выборок приближается к нормальному
df=kПри больших (>30) размерах выборок приближается к нормальному")
Слайд 65 иногда стандартную ошибку среднего приводят как показатель разброса в выборке
зато в публикациях нередко используют доверительный интервал (95% CI), ведь он показывает местонахождение популяционного среднего;
Для публикаций
; это не очень")

Слайд 67Темы занятий (2015 год)
1. Основные понятия. Описательная статистика
2. Тестирование гипотез в
3. Мощность статистического теста. Величина различий (effect size). Формирование выборок для параметрических критериев.
4. Дисперсионный анализ ANOVA
5. Дисперсионный анализ ANOVA (продолжение)
6. Корреляции. Регрессионный анализ
7. Трансформация данных. Непараметрические критерии.
8. Частотный анализ.
9. Основы многомерных методов анализа. Факторный анализ.
10. Дискриминантный анализ. Многомерное шкалирование. Кластерный анализ
1. Основные понятия. Описательная статистика2. Тестирование гипотез в статистике. Критерии Стьюдента3. Мощность")