Коды, примеры кодов
Порождающие матрицы
Смежные классы группы по подгруппе, теорема Лагранжа
Декодирование по лидеру смежного класса
Декодирование по лидеру смежного класса с использованием синдромов
Коды Хемминга
- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Теория кодирования презентация
Содержание
- 1. Теория кодирования
- 2. Коды Определим код как представление множества символов
- 3. Коды Желательно, чтобы коды обладали некоторыми свойствами.
- 4. Коды Существует несколько способов достижения этой цели.
- 5. Коды
- 6. Коды
- 7. Коды Часто необходимо сжимать данные, чтобы минимизировать
- 8. Коды В кодах Хаффмана и Морзе буквы
- 9. Коды В коде Морзе буквы разделены "пробелами",
- 10. Коды В процессе передачи данных могут возникать
- 11. Коды В некоторых случаях интерес представляет только
- 12. Коды В другом случае, когда данные не
- 13. Коды Может показаться разумным всегда использовать коды
- 14. Коды К сожалению, использование кодов с исправлением
- 15. Коды В качестве первого метода обнаружения ошибок
- 16. Коды ASCII-код является блоковым кодом, который использует
- 17. Коды К сожалению, если произошло две ошибки,
- 19. Коды
- 20. Коды Если при кодировании каждая строка повторена
- 21. Коды Например, если закодированная строка имеет вид
- 22. Коды Если имеется отличие в битах в
- 23. Коды
- 24. Порождающие матрицы
- 25. Порождающие матрицы
- 26. Напоминание
- 27. Напоминание
- 28. Порождающие матрицы
- 29. Порождающие матрицы
- 30. Порождающие матрицы
- 31. Порождающие матрицы
- 32. Порождающие матрицы
- 33. Порождающие матрицы
- 34. Порождающие матрицы
- 35. Порождающие матрицы
- 36. Порождающие матрицы
- 37. Порождающие матрицы
- 38. Порождающие матрицы
- 39. Порождающие матрицы
- 40. Порождающие матрицы
- 41. Порождающие матрицы
- 42. Порождающие матрицы
- 43. Порождающие матрицы
- 44. Порождающие матрицы
- 45. Порождающие матрицы
- 46. Порождающие матрицы
- 47. Порождающие матрицы
- 48. Порождающие матрицы
- 49. Порождающие матрицы
- 50. Порождающие матрицы
- 51. Коды
- 52. Теорема Лагранжа
- 53. Теорема Лагранжа
- 54.
- 55.
- 56.
- 57. Теорема Лагранжа
- 58. Теорема Лагранжа
- 59. Декодирование по лидеру смежного класса
- 60. Декодирование по лидеру смежного класса
- 61. Декодирование по лидеру смежного класса
- 62. Декодирование по лидеру смежного класса
- 63. Декодирование по лидеру смежного класса
- 64. Декодирование по лидеру смежного класса
- 65. Декодирование по лидеру смежного класса
- 66. Декодирование по лидеру смежного класса
- 67. Коды
- 68. Декодирование по лидеру смежного класса
- 69. Декодирование по лидеру смежного класса
- 70. Декодирование по лидеру смежного класса
- 71. Декодирование по лидеру смежного класса
- 72. Декодирование по лидеру смежного класса
- 73.
- 74.
- 75. Декодирование по лидеру смежного класса
- 76. Декодирование по лидеру смежного класса
- 77. Декодирование по лидеру смежного класса
- 78. Декодирование по лидеру смежного класса
- 79. В общем случае, если то
- 80. Декодирование по лидеру смежного класса
- 81. Декодирование по лидеру смежного класса
- 82.
- 83. Декодирование по лидеру смежного класса
- 84. Декодирование по лидеру смежного класса
- 85. Декодирование по лидеру смежного класса Снова вернемся
- 86. Декодирование по лидеру смежного класса Уже известно,
- 87. Декодирование по лидеру смежного класса
- 88. Декодирование по лидеру смежного класса Находим, что
- 89. Декодирование по лидеру смежного класса
- 90. Декодирование по лидеру смежного класса
- 91. Декодирование по лидеру смежного класса
- 92. Декодирование по лидеру смежного класса Продолжая процесс, получаем следующую таблицу.
- 94. Декодирование по лидеру смежного класса
- 95. Декодирование по лидеру смежного класса
- 96. Декодирование по лидеру смежного класса
- 97. Декодирование по лидеру смежного класса Заметим, однако,
- 98. Декодирование по лидеру смежного класса
- 99. Декодирование по лидеру смежного класса
- 100. Декодирование по лидеру смежного класса
- 101. Декодирование по лидеру смежного класса
- 102. Декодирование по лидеру смежного класса
- 103. Декодирование по лидеру смежного класса
- 104. Коды Хемминга В рассматриваемом примере существуют определенные
- 105. Коды Хемминга
- 106. Коды Хемминга
- 107. Коды Хемминга
- 108. Коды Хемминга Для изучения матриц Хемминга необходимо
- 109. Коды Хемминга
- 110. Коды Хемминга
- 111. Коды Хемминга
- 112. Коды Хемминга
- 113. Коды Хемминга
- 114. Коды Хемминга
- 115. Коды Хемминга
- 116. Коды Хемминга В приведенной далее теореме сформулирован
- 117. Коды Хемминга
- 118. Коды Хемминга
- 119. Коды Хемминга
- 120. Коды Хемминга
- 121. Коды Хемминга
- 122. Коды Хемминга Задание Построить код Хэмминга.
Слайд 1 Теория кодирования
Ирина Борисовна Просвирнина

Слайд 2Коды
Определим код как представление множества символов строками, состоящими из единиц и
нулей.
Это множество символов обычно включает буквы алфавита, цифры и, как правило, определенные контрольные символы.
Коды представляются бинарными строками с целью использования их компьютерами для хранения и передачи данных.
Это множество символов обычно включает буквы алфавита, цифры и, как правило, определенные контрольные символы.
Коды представляются бинарными строками с целью использования их компьютерами для хранения и передачи данных.

Слайд 3Коды
Желательно, чтобы коды обладали некоторыми свойствами.
Наиболее важное свойство кода состоит
в том, что когда сообщение кодируется как двоичная строка, состоящая из конкатенации элементов кода, эта конкатенация однозначна.
При декодировании сообщения не должно возникать проблем с тем, какую букву представляет элемент кода. Такой код назовем однозначно декодируемым кодом.
При декодировании сообщения не должно возникать проблем с тем, какую букву представляет элемент кода. Такой код назовем однозначно декодируемым кодом.

Слайд 4Коды
Существует несколько способов достижения этой цели.
Один из них – кодирование
всех символов двоичными строками одной длины. Такой код называется блоковым.
Например, если для кодирования каждого символа используется 8 бит, то известно, что каждые восемь бит представляют один символ передаваемого сообщения.
Блоковый код особенно полезен при ограничении длины кода для каждого посланного символа или буквы.
Например, если для кодирования каждого символа используется 8 бит, то известно, что каждые восемь бит представляют один символ передаваемого сообщения.
Блоковый код особенно полезен при ограничении длины кода для каждого посланного символа или буквы.



Слайд 7Коды
Часто необходимо сжимать данные, чтобы минимизировать объем памяти для их хранения
или время для передачи данных.
Что касается минимизации объема памяти, то наиболее эффективным является код Хаффмана. Преимущество кода Хаффмана состоит также в том, что это мгновенный код.
Хорошо известным примером кода, минимизирующего время передачи, является код Морзе.
Что касается минимизации объема памяти, то наиболее эффективным является код Хаффмана. Преимущество кода Хаффмана состоит также в том, что это мгновенный код.
Хорошо известным примером кода, минимизирующего время передачи, является код Морзе.

Слайд 8Коды
В кодах Хаффмана и Морзе буквы или символы, которые встречаются наиболее
часто, имеют более короткий код.

Слайд 9Коды
В коде Морзе буквы разделены "пробелами", а слова – тремя "пробелами".
В данном случае "пробелы" – это единицы времени.

Слайд 10Коды
В процессе передачи данных могут возникать ошибки.
Все, что может стать
причиной ошибок, называется неопределенным термином "шум".
Например, данные, полученные от отдаленного космического корабля, наверняка подвержены различного рода шумам.
Например, данные, полученные от отдаленного космического корабля, наверняка подвержены различного рода шумам.

Слайд 11Коды
В некоторых случаях интерес представляет только определение наличия ошибки, что соответствует
ситуации передачи данных еще раз.
Коды, обладающие свойством определения наличия ошибок, называются кодами, обнаруживающими ошибки.
Коды, обладающие свойством определения наличия ошибок, называются кодами, обнаруживающими ошибки.

Слайд 12Коды
В другом случае, когда данные не могут быть переданы еще раз
(например, данные от удаленного космического корабля), требуется дополнительная информация о данных с целью не только обнаружения, но и исправления ошибки.
Коды, позволяющие исправлять ошибки, называются кодами, исправляющими ошибки.
Коды, позволяющие исправлять ошибки, называются кодами, исправляющими ошибки.

Слайд 13Коды
Может показаться разумным всегда использовать коды с исправлением ошибок.
Проблема использования
кодов с исправлением ошибок и кодов с обнаружением ошибок состоит в том, что они должны включать в себя дополнительную информацию, поэтому они являются менее эффективными в отношении минимизации объема памяти.

Слайд 14Коды
К сожалению, использование кодов с исправлением ошибок и кодов с обнаружением
ошибок не дает абсолютной гарантии того, что ошибка будет исправлена или обнаружена.

Слайд 15Коды
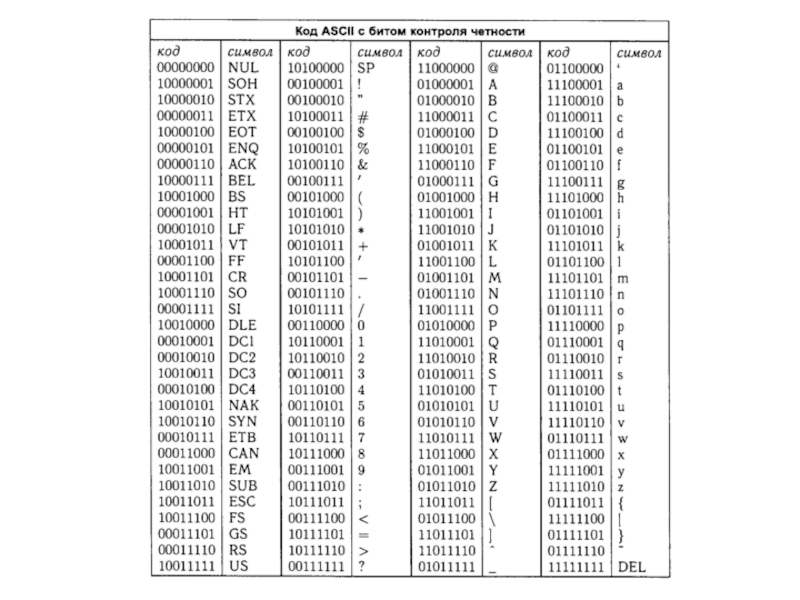
В качестве первого метода обнаружения ошибок рассмотрим бит контроля четности.
Продемонстрируем этот
метод на примере кода ASCII.

Слайд 16Коды
ASCII-код является блоковым кодом, который использует 7 битов, поэтому любой закодированный
символ изображается строкой из семи символов 1 и 0.
Восьмой бит добавляется таким образом, чтобы количество единиц было четным.
Поэтому, если код переданной строки получен с единственной ошибкой, то количество единиц будет нечетным, и получатель информации поймет, что произошла ошибка.
Восьмой бит добавляется таким образом, чтобы количество единиц было четным.
Поэтому, если код переданной строки получен с единственной ошибкой, то количество единиц будет нечетным, и получатель информации поймет, что произошла ошибка.

Слайд 17Коды
К сожалению, если произошло две ошибки, их нельзя будет обнаружить, поскольку
количество единиц опять будет четным.


Слайд 20Коды
Если при кодировании каждая строка повторена один раз, то в результате
получаем код с обнаружением ошибок.
Если произошла ошибка, то соответствующие позиции не будут совпадать.
Если произошла ошибка, то соответствующие позиции не будут совпадать.

Слайд 21Коды
Например, если закодированная строка имеет вид 111111010110111011, то ошибки имеются в
третьем и в последнем битах.
Исправить ошибки мы не можем, поскольку не знаем, в какой из копий какая ошибка присутствует.
Если кодируемая строка повторяется дважды, то лучше всего выявить ошибку.
Если имеются три копии строки, то можно исправить код при наличии единственной ошибки.
Исправить ошибки мы не можем, поскольку не знаем, в какой из копий какая ошибка присутствует.
Если кодируемая строка повторяется дважды, то лучше всего выявить ошибку.
Если имеются три копии строки, то можно исправить код при наличии единственной ошибки.

Слайд 22Коды
Если имеется отличие в битах в соответствующих позициях строк, то выбирается
значение, которое встречается дважды.
Например, если строка имеет длину 4 и нам передано 110110011101, то во второй позиции мы два раза получим 1 и один раз 0.
Таким образом, предполагаем, что правильное значение равно 1, и правильным вариантом закодированной строки является 1101.
Например, если строка имеет длину 4 и нам передано 110110011101, то во второй позиции мы два раза получим 1 и один раз 0.
Таким образом, предполагаем, что правильное значение равно 1, и правильным вариантом закодированной строки является 1101.







































































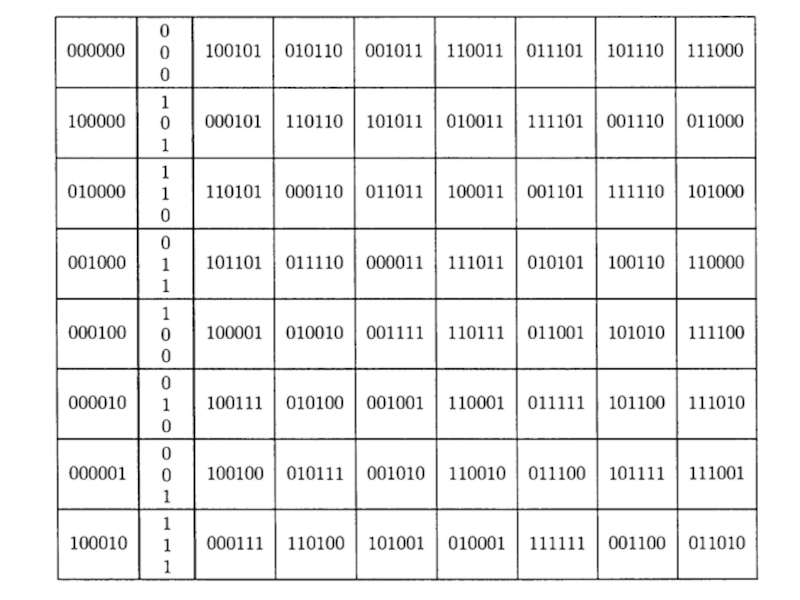



Слайд 97Декодирование по лидеру смежного класса
Заметим, однако, что процесс можно сделать еще
быстрее.
При этом потребуются только два первых столбца приведенной выше таблицы.
При этом потребуются только два первых столбца приведенной выше таблицы.







Слайд 104Коды Хемминга
В рассматриваемом примере существуют определенные трудности при попытке исправить код
для некоторых строк, поскольку все лидеры имеют вес 1.
Эти трудности устраняются путем использования матрицы, называемой матрицей Хемминга, в качестве порождающей матрицы.
Эти трудности устраняются путем использования матрицы, называемой матрицей Хемминга, в качестве порождающей матрицы.




Слайд 108Коды Хемминга
Для изучения матриц Хемминга необходимо понятие расстояния и его связь
с весом каждой из строк.
Начнем с теоремы о весах строк.
Начнем с теоремы о весах строк.








Слайд 116Коды Хемминга
В приведенной далее теореме сформулирован важный критерий для определения числа
ошибок, которые могут быть исправлены или обнаружены с использованием кода.






Слайд 122Коды Хемминга
Задание
Построить код Хэмминга.
Изучить корректирующие способности кода Хэмминга.
Показать, что синдромы
указывают позиции ошибок.






