MPI
- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Разработка параллельных программ для систем с распределенной памятью презентация
Содержание
- 1. Разработка параллельных программ для систем с распределенной памятью
- 2. СИСТЕМЫ С РАСПРЕДЕЛЕННОЙ ПАМЯТЬЮ Особенности систем с распределенной памятью
- 3. Распределенные системы (1) Мультикомпьютеры Кластерные системы (Clusters) Массивно-параллельные процессоры (MPP)
- 4. Распределенные системы (2) Своя оперативная память Своя операционная система Различные вычислительные мощности Неограниченное масштабирование
- 5. Распределенные системы (3) Возможно использовать только процессы Высокая стоимость коммуникаций
- 6. СОЗДАНИЕ РАСПРЕДЕЛЕННЫХ ПРИЛОЖЕНИЙ Способы создания распределенных программ
- 7. Распределенное приложение Распределенное приложение (программа) - множество
- 8. Стоимость коммуникаций Выбор оптимальной топологии Минимизация количества
- 9. Выбор технологии Специальные языки Erlang, Go и
- 10. Специализированные языки Инкапсулируют сложность коммуникаций Основное внимание
- 11. Общая шина сообщений Инкапсулирует сложность коммуникаций Основное
- 12. Высокоуровневые библиотеки Инкапсулируют сложность коммуникаций Основное внимание
- 13. Низкоуровневые функции Сложность осуществления коммуникаций Гибкость осуществления коммуникаций Вероятная зависимость от платформы Произвольная схема взаимодействия
- 14. Combo? При разработке крупных систем зачастую используются разные подходы
- 15. ОСНОВЫ ТЕХНОЛОГИИ MPI Распараллеливание вычислительных алгоритмов с помощью MPI
- 16. Почему рассматриваем MPI? Позволяет раскрыть некоторые особенности
- 17. MPI «The MPI standard includes point-to-point message-passing,
- 18. Концепция MPI Определяет API и протокол обмена
- 19. Коммуникатор
- 20. Виртуальные топологии Есть возможность задавать виртуальную топологию
- 21. Структура кода MPI-процесса #include void
- 22. Ранг и количество процессов #include
- 23. Передача и прием сообщений int MPI_Send( void*
- 24. Корневой процесс #include void main(int
- 25. Редукция Передача данных от всех процессов одному
- 26. Барьерная синхронизация Точка синхронизации, которую должны достигнуть
- 27. Время выполнения double startTime = MPI_Wtime();;
- 28. Пример вычислений void CalculatePi(int rank, int size,
- 29. ВОПРОСЫ?
Слайд 1Разработка параллельных программ для систем с распределенной памятью
Создание распределенных приложений
Основы технологии


Слайд 3Распределенные системы (1)
Мультикомпьютеры
Кластерные системы (Clusters)
Массивно-параллельные процессоры (MPP)
МультикомпьютерыКластерные системы (Clusters)Массивно-параллельные процессоры (MPP)")
Слайд 4Распределенные системы (2)
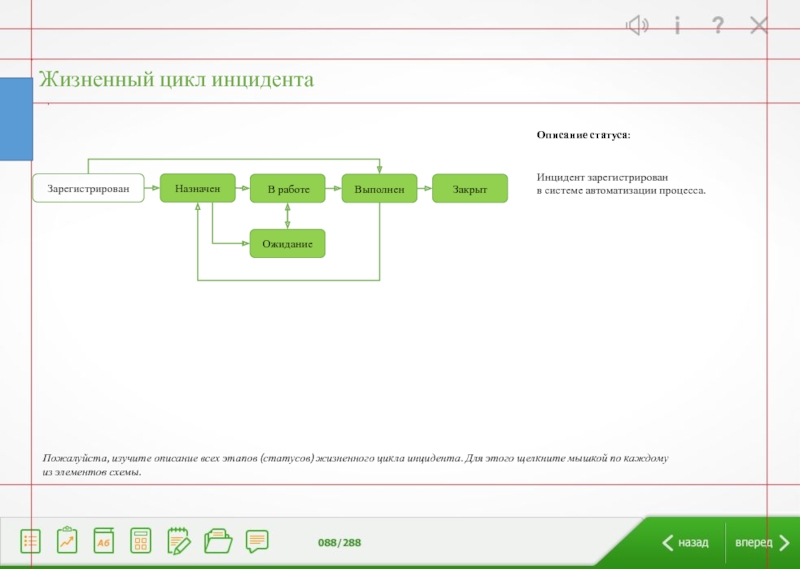
Своя оперативная память
Своя операционная система
Различные вычислительные мощности
Неограниченное масштабирование
Своя оперативная памятьСвоя операционная системаРазличные вычислительные мощностиНеограниченное масштабирование")
Слайд 5Распределенные системы (3)
Возможно использовать только процессы
Высокая стоимость коммуникаций
Возможно использовать только процессыВысокая стоимость коммуникаций")

Слайд 7Распределенное приложение
Распределенное приложение (программа) - множество одновременно выполняемых взаимодействующих процессов, которые
могут выполняться на одном или нескольких узлах вычислительной сети
 - множество одновременно выполняемых взаимодействующих процессов, которые могут выполняться на одном")
Слайд 8Стоимость коммуникаций
Выбор оптимальной топологии
Минимизация количества связей
Минимизация количества пересылок
Минимизация размера сообщений
Унификация и
типизация сообщений
И т.д.
И т.д.

Слайд 9Выбор технологии
Специальные языки
Erlang, Go и т.п.
Общая шина сообщений
RabbitMq и т.п.
Высокоуровневые библиотеки
WCF
(SOAP), WebAPI (REST), MPI и т.п.
Низкоуровневые функции и объекты
Socket, Pipe и т.п.
Низкоуровневые функции и объекты
Socket, Pipe и т.п.
, WebAPI (REST), MPI")
Слайд 10Специализированные языки
Инкапсулируют сложность коммуникаций
Основное внимание на прикладной задаче
Простая запись математических алгоритмов
Встроенные
средства распараллеливания

Слайд 11Общая шина сообщений
Инкапсулирует сложность коммуникаций
Основное внимание на прикладной задаче
Простая и очевидная
схема взаимодействия
Гибкие схемы маршрутизации сообщений
Гибкие схемы маршрутизации сообщений

Слайд 12Высокоуровневые библиотеки
Инкапсулируют сложность коммуникаций
Основное внимание на прикладной задаче
Асинхронность чаще реализуется вручную
Произвольная
схема взаимодействия

Слайд 13Низкоуровневые функции
Сложность осуществления коммуникаций
Гибкость осуществления коммуникаций
Вероятная зависимость от платформы
Произвольная схема взаимодействия



Слайд 16Почему рассматриваем MPI?
Позволяет раскрыть некоторые особенности реализации более высокоуровневых решений, а
также дает хорошее представление о сложностях и особенностях разработки распределенных приложений

Слайд 17MPI
«The MPI standard includes point-to-point message-passing, collective communications, group and communicator
concepts, process topologies, environmental management, process creation and management, one-sided communications, extended collective operations, external interfaces, I/O, some miscellaneous topics, and a profiling interface»
Стандарт - http://www.mpi-forum.org
MPICH - http://www.mpich.org
Microsoft MPI
Стандарт - http://www.mpi-forum.org
MPICH - http://www.mpich.org
Microsoft MPI

Слайд 18Концепция MPI
Определяет API и протокол обмена сообщениями между процессами распределенного приложения
Базовые
понятия касаются преимущественно вопросов коммуникации: функции обмена сообщениями, типы данных и формат сообщений, коммуникаторы, топологии и способ идентификации процесса (ранг)


Слайд 20Виртуальные топологии
Есть возможность задавать виртуальную топологию связей между процессами, которая будет
отражать логическую взаимосвязь процессов приложения
Виртуальная топология может быть использована при распределении процессов по узлам с целью уменьшения коммуникационной трудоемкости
Виртуальная топология может быть использована при распределении процессов по узлам с целью уменьшения коммуникационной трудоемкости

Слайд 21Структура кода MPI-процесса
#include
void main(int argc, char *argv[])
{
функций MPI>
MPI_Init(&argc, &argv);
<Программный код с использованием функций MPI>
MPI_Finalize();
<Программный код без использования функций MPI>
}
MPI_Init(&argc, &argv);
<Программный код с использованием функций MPI>
MPI_Finalize();
<Программный код без использования функций MPI>
}
{ MPI_Init(&argc, &argv); MPI_Finalize(); }")
Слайд 22Ранг и количество процессов
#include
void main(int argc, char *argv[])
{
использования функций MPI>
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
<Программный код с использованием функций MPI>
MPI_Finalize();
<Программный код без использования функций MPI>
}
MPI_Init(&argc, &argv);
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
<Программный код с использованием функций MPI>
MPI_Finalize();
<Программный код без использования функций MPI>
}
{ MPI_Init(&argc, &argv); int rank, size; MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); MPI_Finalize(); }")
Слайд 23Передача и прием сообщений
int MPI_Send(
void* buffer,
int count,
MPI_Datatype type,
int dest,
int tag,
MPI_Comm comm
);
int
MPI_Recv(
void* buffer,
int count,
MPI_Datatype type,
int source,
int tag,
MPI_Comm comm,
MPI_Status* status
);
void* buffer,
int count,
MPI_Datatype type,
int source,
int tag,
MPI_Comm comm,
MPI_Status* status
);
;int MPI_Recv( void* buffer, int count, MPI_Datatype type, int")
Слайд 24Корневой процесс
#include
void main(int argc, char *argv[])
{
int rank, size;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD,
&size);
if (rank == 0)
{
// Корневой процесс
}
else
{
// Дочерние процессы
}
MPI_Finalize();
}
if (rank == 0)
{
// Корневой процесс
}
else
{
// Дочерние процессы
}
MPI_Finalize();
}
{ int rank, size; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &size); if (rank == 0) { //")
Слайд 25Редукция
Передача данных от всех процессов одному процессу (обычно корневому процессу)
int MPI_Reduce(
void*
sendBuffer,
void* receiveBuffer,
MPI_Datatype type,
MPI_Op operation,
int root,
MPI_Comm comm
);
void* receiveBuffer,
MPI_Datatype type,
MPI_Op operation,
int root,
MPI_Comm comm
);
int MPI_Reduce( void* sendBuffer, void* receiveBuffer, MPI_Datatype type, MPI_Op operation, int")
Слайд 26Барьерная синхронизация
Точка синхронизации, которую должны достигнуть все процессы, прежде чем продолжат
свое выполнение
int MPI_Barrier(MPI_Comm comm);
;")
Слайд 27Время выполнения
double startTime = MPI_Wtime();;
double stopTime = MPI_Wtime();;
double elapsed =
stopTime - startTime;
;;double stopTime = MPI_Wtime();;double elapsed = stopTime - startTime;")
Слайд 28Пример вычислений
void CalculatePi(int rank, int size, int n)
{
double pi;
MPI_Bcast(&n, 1, MPI_INT,
0, MPI_COMM_WORLD);
double sum = 0.0;
double coeff = 1.0 / (double)n;
for (int i = rank + 1; i <= n; i += size)
{
double x = coeff * ((double)i + 0.5);
sum += 4.0 / (1.0 + x * x);
}
sum *= coeff;
MPI_Reduce(&sum, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0)
{
printf("PI = %.8f\n", pi);
}
}
double sum = 0.0;
double coeff = 1.0 / (double)n;
for (int i = rank + 1; i <= n; i += size)
{
double x = coeff * ((double)i + 0.5);
sum += 4.0 / (1.0 + x * x);
}
sum *= coeff;
MPI_Reduce(&sum, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (rank == 0)
{
printf("PI = %.8f\n", pi);
}
}
{ double pi; MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD); double sum =")