- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Параллельные вычислительные процессы и системы презентация
Содержание
- 1. Параллельные вычислительные процессы и системы
- 2. Структура курса: Тема 1. Архитектура и функционирование
- 3. Модуль 1. Архітектура та функціонування сучасних паралельних
- 4. Литература: Гергель, В.П., Стронгин, Р.Г. (2003, 2
- 5. Первый вопрос. Основные определения и понятия. Актуальность
- 6. Руководители проекта Top500 представили очередной рейтинг самых
- 7. Titan: Oak Ridge National Laboratory No.
- 10. Два основных подхода к достижению параллельности
- 11. Типичная архитектура построения параллельной и распределенной программ
- 12. ПРЕИМУЩЕСТВА ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ Программы, надлежащее качество
- 13. Простейшая модель параллельного программирования (PRAM) В качестве
- 14. Все процессоры имеют доступ для чтения и
- 15. Таблица 1.1. Четыре базовых алгоритма считывания
- 16. Преимущества распределенного программирования Методы распределенного программирования
- 17. Простейшие модели распределенного программирования модель типа "клиент/сервер".
- 18. Мультиагентные распределенные системы Агенты — рациональные компоненты
- 19. Второй вопрос. Основные классы параллельных вычислительных средств.
- 20. ОСНОВНЫЕ КЛАССЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СРЕДСТВ
- 22. Особенности параллельных ЭВМ с симметричной мультипроцессорной обработкой
- 23. Третий вопрос. Анализ путей повышения эффективности использования
- 25. АНАЛИЗ ПУТЕЙ ПОВЫШЕНИЯ ЭФФЕКТИВНОСТИ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
- 26. ЗАКОНЫ АМДАЛА Пусть пиковая производительность однопроцессорной системы
- 27. КОНЦЕПЦИИ ПОСТРОЕНИЯ САМООРГАНИЗУЮЩИХСЯ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ .
- 28. Четвертый вопрос. Характеристика методов параллельной обработки
- 29. МЕТОДЫ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ДАННЫХ
- 31. Последовательный (а) и параллельный (б) графы решения задачи, иллюстрирующие метод совмещения независимых операций
- 32. МЕТОДЫ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ДАННЫХ
Слайд 1ВВОДНАЯ ЛЕКЦИЯ.
ПАРАЛЛЕЛЬНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ
ПРОЦЕССЫ И
СИСТЕМЫ
Д.т.н. , с.н.с. Толстолужская Е.Г.

Слайд 2Структура курса:
Тема 1. Архитектура и функционирование параллельных процессоров и многопроцессорных систем.
Тема
2. Автоматизация проектирования параллельных программ.
Тема 3. Методы параллельной обработки данных.
Тема 3. Методы параллельной обработки данных.

Слайд 3Модуль 1. Архітектура та функціонування сучасних паралельних процесорів та багатопроцесорних систем.
Тема
1. Класифікація паралельних процесорів. Архитектура та функціонування суперскалярних процесорів.
Тема 2. Паралельні архитектури. Класифікація паралельних систем по Флінну.
Тема 3. Архітектура і функціонування паралельних процесорів з довгим командним словом VLIW.
Тема 4. Архітектура і функціонування паралельних процесорів з управлінням потоком даних.
Тема 5. Багатопроцесорні ЕОМ з розділяємою пам`яттю. Багатомашинні системи.
Модуль 2. Автоматизація проектування паралельних програм.
Тема 1. Класифікація паралельних програм. Особливості програмування паралельних обчислювань.
Тема 2. Основні напрямки рішення проблем паралельного програмування.
Тема 3. Введення в паралельне програмування з використанням MPI («Інтерфейс Передачі Повідомлень»).
Тема 4. Обмін даними в MPI. Колективний обмін даними в MPI.
Тема 5. Введення в паралельне програмування з використанням PVM (Parallel Virtual Machine). Програмування з використанням PVM.
Модуль 3. Методи паралельної обробки даних.
Тема 1. Вступ. Загальні відомості про паралельні обчислювальні процеси та системи.
Тема 2. Статичні та часові паралельні алгоритми і процеси.
Тема 3. Часові паралельні алгоритми.
Тема 4. Показники ефективності паралельної реалізації алгоритмів та їх зв`язок з вимогами практики.
Тема 5. Метод суміщення незалежних операцій. Метод формального синтеза паралельних часових моделей алгоритму.
Тема 6. Проектування високонадійних паралельних програмних засобів для систем управління критичними технологіями та об`єктами.
Тема 2. Паралельні архитектури. Класифікація паралельних систем по Флінну.
Тема 3. Архітектура і функціонування паралельних процесорів з довгим командним словом VLIW.
Тема 4. Архітектура і функціонування паралельних процесорів з управлінням потоком даних.
Тема 5. Багатопроцесорні ЕОМ з розділяємою пам`яттю. Багатомашинні системи.
Модуль 2. Автоматизація проектування паралельних програм.
Тема 1. Класифікація паралельних програм. Особливості програмування паралельних обчислювань.
Тема 2. Основні напрямки рішення проблем паралельного програмування.
Тема 3. Введення в паралельне програмування з використанням MPI («Інтерфейс Передачі Повідомлень»).
Тема 4. Обмін даними в MPI. Колективний обмін даними в MPI.
Тема 5. Введення в паралельне програмування з використанням PVM (Parallel Virtual Machine). Програмування з використанням PVM.
Модуль 3. Методи паралельної обробки даних.
Тема 1. Вступ. Загальні відомості про паралельні обчислювальні процеси та системи.
Тема 2. Статичні та часові паралельні алгоритми і процеси.
Тема 3. Часові паралельні алгоритми.
Тема 4. Показники ефективності паралельної реалізації алгоритмів та їх зв`язок з вимогами практики.
Тема 5. Метод суміщення незалежних операцій. Метод формального синтеза паралельних часових моделей алгоритму.
Тема 6. Проектування високонадійних паралельних програмних засобів для систем управління критичними технологіями та об`єктами.

Слайд 4Литература:
Гергель, В.П., Стронгин, Р.Г. (2003, 2 изд.). Основы параллельных вычислений для
многопроцессорных вычислительных систем. - Н.Новгород, ННГУ.
Воеводин В.В., Воеводин Вл.В. (2002). Параллельные вычисления. – СПб.: БХВ-Петербург.
Немнюгин С. (2009). Модели и средства программирования для многопроцессорных систем– СПб.: БХВ-Петербург.
Хьюз К., Хьюз Т.(2004). Параллельное и распределенное программирование на С++.: Пер. с англ. – М.: Издательский дом «Вильямс», 2004. – 672с.
Поляков Г.А., Шматков С.И., Толстолужская Е.Г., Толстолужский Д.А. (2012). Синтез и анализ параллельных процессов в адаптивных времяпараметризованных вычислительных системах. – Х.: ХНУ имени В.Н. Каразина, 2012.-672с.
Grama, A., Gupta, A., Kumar V. (2003, 2nd edn.). Introduction to Parallel Computing. – Harlow, England: Addison-Wesley.
Quinn, M. J. (2004). Parallel Programming in C with MPI and OpenMP. – New York, NY: McGraw-Hill.
Parallel Programming in OpenMP. Morgan Kaufmann Publishers.
Culler, D., Singh, J.P., Gupta, A. (1998) Parallel Computer Architecture: A Hardware/Software Approach. - Morgan Kaufmann.
Tanenbaum, A. (2001). Modern Operating System. 2nd edn. – Prentice Hall (русский перевод Таненбаум Э. Современные операционные системы. – СПб.: Питер, 2002)
Воеводин В.В., Воеводин Вл.В. (2002). Параллельные вычисления. – СПб.: БХВ-Петербург.
Немнюгин С. (2009). Модели и средства программирования для многопроцессорных систем– СПб.: БХВ-Петербург.
Хьюз К., Хьюз Т.(2004). Параллельное и распределенное программирование на С++.: Пер. с англ. – М.: Издательский дом «Вильямс», 2004. – 672с.
Поляков Г.А., Шматков С.И., Толстолужская Е.Г., Толстолужский Д.А. (2012). Синтез и анализ параллельных процессов в адаптивных времяпараметризованных вычислительных системах. – Х.: ХНУ имени В.Н. Каразина, 2012.-672с.
Grama, A., Gupta, A., Kumar V. (2003, 2nd edn.). Introduction to Parallel Computing. – Harlow, England: Addison-Wesley.
Quinn, M. J. (2004). Parallel Programming in C with MPI and OpenMP. – New York, NY: McGraw-Hill.
Parallel Programming in OpenMP. Morgan Kaufmann Publishers.
Culler, D., Singh, J.P., Gupta, A. (1998) Parallel Computer Architecture: A Hardware/Software Approach. - Morgan Kaufmann.
Tanenbaum, A. (2001). Modern Operating System. 2nd edn. – Prentice Hall (русский перевод Таненбаум Э. Современные операционные системы. – СПб.: Питер, 2002)
. Основы параллельных вычислений для многопроцессорных вычислительных систем. -")
Слайд 5Первый вопрос. Основные определения и понятия. Актуальность использования
супер ЭВМ.
Процесс Параллелизм Параллельный процесс Параллельная обработка Параллельная вычислительная система

Слайд 6Руководители проекта Top500 представили очередной рейтинг самых мощных в мире суперкомпьютеров.
Список систем в порядке убывания быстродействия приводится на сайте top500.org.
Первое место заняла Tianhe-2, расположенная в Национальном суперкомпьютерном центре в Тянжине в Китае, максимальная производительность которой составляет 33,86 Пфлоп/с
Первое место заняла Tianhe-2, расположенная в Национальном суперкомпьютерном центре в Тянжине в Китае, максимальная производительность которой составляет 33,86 Пфлоп/с
Tianhe-2 (MilkyWay-2) : National University of Defense Technology
No. 1 system since June 2013
Tianhe-2, a supercomputer developed by China’s National University of Defense Technology, retains its position as the world’s No. 1 system with a performance of 33.86 petaflop/s (quadrillions of calculations per second) on the Linpack benchmark. It was built by China's National University of Defense Technology (NUDT) in collaboration with the Chinese IT firm Inspur.
According to NUDT, Tianhe-2 will be used for simulation, analysis, and government security applications. With 16,000 computer nodes, each comprising two Intel Ivy Bridge Xeon processors and three Xeon Phi chips, it represents the world's largest installation of Ivy Bridge and Xeon Phi chips, counting a total of 3,120,000 cores.[3] Each of the 16,000 nodes possess 88 gigabytes of memory (64 used by the Ivy Bridge processors, and 8 gigabytes for each of the Xeon Phi processors). The total CPU plus coprocessor memory is 1,375 TiB (approximately 1.34 PiB). MPI: MPICH2.

Слайд 7
Titan: Oak Ridge National Laboratory
No. 1 system in November 2012
When the
40th edition of the list was released at the start of SC12, the No. 1 position was claimed by Titan, a 552,960 processor system with a Linpack performance of 17.6 petaflop/s. Oak Ridge National Laboratory's Titan is a Cray XK7 system that relies on a combination of GPUs and traditional CPUs to make it the world's most powerful supercomputer. Each of Titan's 18,688 nodes contains an NVIDIA Tesla K20 GPU along with a 16-core AMD Opteron 6274 CPU processor, giving the system a peak performance of more than 27 petaflops. Titan also has more than 700 terabytes of memory.
Titan's use of GPUs also points the way for future scientific supercomputers. Because GPUs provide high-performance and energy-efficient computing power, they will allow supercomputing systems to become ever more powerful while avoiding the obstacles inherent in growing size and power consumption.
Titan's use of GPUs also points the way for future scientific supercomputers. Because GPUs provide high-performance and energy-efficient computing power, they will allow supercomputing systems to become ever more powerful while avoiding the obstacles inherent in growing size and power consumption.



Слайд 10Два основных подхода к достижению параллельности
Параллельное и распределенное программирование — это
два базовых подхода к достижению параллельного выполнения составляющих программного обеспечения (ПО). Они представляют собой две различные парадигмы программирования, которые иногда пересекаются.
Методы параллельного программирования позволяют распределить работу программы между двумя (или больше) процессорами в рамках одного физического или одного виртуального компьютера.
Методы распределенного программирования позволяют распределить работу программы между двумя (или больше) процессами, причем процессы могут существовать на одном и том же компьютере или на разных.
Методы параллельного программирования позволяют распределить работу программы между двумя (или больше) процессорами в рамках одного физического или одного виртуального компьютера.
Методы распределенного программирования позволяют распределить работу программы между двумя (или больше) процессами, причем процессы могут существовать на одном и том же компьютере или на разных.


Слайд 12ПРЕИМУЩЕСТВА ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
Программы, надлежащее качество проектирования которых позволяет воспользоваться преимуществами
параллелизма, могут выполняться быстрее, чем их последовательные эквиваленты, что повышает их рыночную стоимость. Иногда скорость может спасти жизнь. В таких случаях быстрее означает лучше. Иногда решение некоторых проблем представляется естественнее в виде коллекции одновременно выполняемых задач. Это характерно для таких областей, как научное программирование, математическое и программирование искусственного интеллекта. Это означает, что в некоторых ситуациях технологии параллельного программирования снижают трудозатраты разработчика ПО, позволяя ему напрямую реализовать структуры данных, алгоритмы и эвристические методы, разрабатываемые учеными. При этом используется специализированное оборудование.
Применение более совершенных технологий параллельного программирования открывает двери к архитектурам ПО, которые специально разрабатываются для параллельных сред. Например, существуют специальные мультиагентные архитектуры и архитектуры, использующие методологию "классной доски", разработанные специально для среды с параллельными процессорами.
Применение более совершенных технологий параллельного программирования открывает двери к архитектурам ПО, которые специально разрабатываются для параллельных сред. Например, существуют специальные мультиагентные архитектуры и архитектуры, использующие методологию "классной доски", разработанные специально для среды с параллельными процессорами.

Слайд 13Простейшая модель параллельного программирования (PRAM)
В качестве простейшей модели, отражающей базовые концепции
параллельного программирования, рассмотрим модель PRAM (Parallel Random Access Machine — параллельная машина с произвольным доступом). PRAM — это упрощенная теоретическая модель с и процессорами, которые используют общую глобальную память. Простая модель PRAM изображена на рис. 1.2.
Рис. 1.2. Простая модель PRAM
Рис. 1.2. Простая модель PRAM
В качестве простейшей модели, отражающей базовые концепции параллельного программирования, рассмотрим модель")
Слайд 14 Все процессоры имеют доступ для чтения и записи к общей глобальной
памяти. В PRAM-среде возможен одновременный доступ. Предположим, что все процессоры могут параллельно выполнять различные арифметические и логические операции.
Кроме того, каждый из теоретических процессоров (см. рис. 1.2) может обращаться к общей памяти в одну непрерываемую единицу времени. PRAM-модель обладает как параллельными, так и исключающими алгоритмами считывания данных.
Параллельные алгоритмы считывания данных позволяют одновременно обращаться к одной и той же области памяти без искажения (порчи) данных. Исключающие алгоритмы считывания данных используются в случае, когда необходима гарантия того, что никакие два процесса никогда не будут считывать данные из одной и той же области памяти одновременно. PRAM- модель также обладает параллельными и исключающими алгоритмами записи данных.
Параллельные алгоритмы позволяют нескольким процессам одновременно записывать данные в одну и ту же область памяти, в то время как исключающие алгоритмы гарантируют, что никакие два процесса не будут записывать данные в одну и ту же область памяти одновременно.
Кроме того, каждый из теоретических процессоров (см. рис. 1.2) может обращаться к общей памяти в одну непрерываемую единицу времени. PRAM-модель обладает как параллельными, так и исключающими алгоритмами считывания данных.
Параллельные алгоритмы считывания данных позволяют одновременно обращаться к одной и той же области памяти без искажения (порчи) данных. Исключающие алгоритмы считывания данных используются в случае, когда необходима гарантия того, что никакие два процесса никогда не будут считывать данные из одной и той же области памяти одновременно. PRAM- модель также обладает параллельными и исключающими алгоритмами записи данных.
Параллельные алгоритмы позволяют нескольким процессам одновременно записывать данные в одну и ту же область памяти, в то время как исключающие алгоритмы гарантируют, что никакие два процесса не будут записывать данные в одну и ту же область памяти одновременно.

Слайд 15
Таблица 1.1. Четыре базовых алгоритма считывания и записи данных
Необходимо отметить,
что хотя PRAM — это упрощенная теоретическая модель, она успешно используется для разработки практических программ, и эти программы могут соперничать по производительности с программами, которые были разработаны с использованием более сложных моделей параллелизма.

Слайд 16 Преимущества распределенного программирования
Методы распределенного программирования позволяют воспользоваться преимуществами ресурсов, размещенных
в Internet, в корпоративных Intranet и локальных сетях.
Распределенное программирование обычно включает сетевое программирование в той или иной форме. Это означает, что программе, которая выполняется на одном компьютере в одной сети, требуется некоторый аппаратный или программный ресурс, который принадлежит другому компьютеру в той же или удаленной сети. Распределенное программирование подразумевает общение одной программы с другой через сетевое соединение, которое включает соответствующее оборудование (от модемов до спутников). Отличительной чертой распределенных программ является то, что они разбиваются на части. Эти части обычно реализуются как отдельные программы, которые, как правило, выполняются на разных компьютерах и взаимодействуют друг с другом через сеть.
Методы распределенного программирования предоставляют доступ к ресурсам, которые географически могут находиться на большом расстоянии друг от друга.
Распределенное программирование обычно включает сетевое программирование в той или иной форме. Это означает, что программе, которая выполняется на одном компьютере в одной сети, требуется некоторый аппаратный или программный ресурс, который принадлежит другому компьютеру в той же или удаленной сети. Распределенное программирование подразумевает общение одной программы с другой через сетевое соединение, которое включает соответствующее оборудование (от модемов до спутников). Отличительной чертой распределенных программ является то, что они разбиваются на части. Эти части обычно реализуются как отдельные программы, которые, как правило, выполняются на разных компьютерах и взаимодействуют друг с другом через сеть.
Методы распределенного программирования предоставляют доступ к ресурсам, которые географически могут находиться на большом расстоянии друг от друга.

Слайд 17Простейшие модели распределенного программирования
модель типа "клиент/сервер".
Самой простой и распространенной
моделью распределенной обработки данных является модель типа "клиент/сервер". В этой модели программа разбивается на две части: одна часть называется сервером, а другая — клиентом. Сервер имеет прямой доступ к некоторым аппаратным и программным ресурсам, которые желает использовать клиент.
В большинстве случаев сервер и клиент располагаются на разных компьютерах. Обычно между клиентом и сервером существует отношение типа "множество-к-одному", т.е., как правило, один сервер отвечает на запросы многих клиентов.
Сервер часто обеспечивает опосредованный доступ к огромной базе данных, дорогостоящему оборудованию или некоторой коллекции приложений. Клиент может запросить интересующие его данные, сделать запрос на выполнение вычислительной процедуры или обработку другого типа.
Несмотря на то что клиент и сервер представляют собой отдельные программы, выполняющиеся на разных компьютерах, вместе они составляют единое приложение. Разделение ПО на части клиента и сервера и есть основной метод распределенного программирования.
В большинстве случаев сервер и клиент располагаются на разных компьютерах. Обычно между клиентом и сервером существует отношение типа "множество-к-одному", т.е., как правило, один сервер отвечает на запросы многих клиентов.
Сервер часто обеспечивает опосредованный доступ к огромной базе данных, дорогостоящему оборудованию или некоторой коллекции приложений. Клиент может запросить интересующие его данные, сделать запрос на выполнение вычислительной процедуры или обработку другого типа.
Несмотря на то что клиент и сервер представляют собой отдельные программы, выполняющиеся на разных компьютерах, вместе они составляют единое приложение. Разделение ПО на части клиента и сервера и есть основной метод распределенного программирования.

Слайд 18Мультиагентные распределенные системы
Агенты — рациональные компоненты ПО, которые характеризуются самонаведением и
автономностью и могут постоянно находиться в состоянии выполнения. Агенты могут как создавать запросы к другим программным компонентам, так и отвечать на запросы, полученные от других программных компонентов. Агенты сотрудничают в пределах групп для коллективного выполнения определенных задач. В такой модели не существует конкретного клиента или сервера. Это — модель сети с равноправными узлами (peer-to-peer), в которой все компоненты имеют одинаковые права, и при этом у каждого компонента есть что предложить другому.
Агенты являются распределенными, поскольку все они размещаются на разных серверах в Internet. Для связи агенты используют согласованный Internet-протокол. Для одних типов распределенного программирования лучше подходит модель типа "клиент/сервер", а для других — модель равноправных агентов.
Агенты являются распределенными, поскольку все они размещаются на разных серверах в Internet. Для связи агенты используют согласованный Internet-протокол. Для одних типов распределенного программирования лучше подходит модель типа "клиент/сервер", а для других — модель равноправных агентов.

Слайд 19Второй вопрос. Основные классы параллельных вычислительных средств.
Суперскалярный процессор VLIW-процессор
Потоковый процессор SMP-ЭВМ MPP-суперЭВМ NUMA-кластерные ЭВМ



Слайд 22Особенности параллельных ЭВМ с симметричной мультипроцессорной обработкой (Symmetric Multi-Processing, SMP):
исполнительными устройствами являются универсальные процессоры, количество процессоров определяется конкретной конфигурацией ЭВМ;
наличие в каждом процессоре индивидуальной физической памяти, включаемой в общую виртуальную память ЭВМ с единым адресным пространством, доступным каждому из процессоров;
представление параллельного процесса в виде множества одновременно (параллельно) выполняемых процессорами программ – нитей (thread - program);
временная синхронизация выполнения программ – нитей, реализуемых различными процессорами в рамках параллельного решения единой задачи, например, с помощью оператора временной задержки WAIT.
наличие в каждом процессоре индивидуальной физической памяти, включаемой в общую виртуальную память ЭВМ с единым адресным пространством, доступным каждому из процессоров;
представление параллельного процесса в виде множества одновременно (параллельно) выполняемых процессорами программ – нитей (thread - program);
временная синхронизация выполнения программ – нитей, реализуемых различными процессорами в рамках параллельного решения единой задачи, например, с помощью оператора временной задержки WAIT.
: исполнительными устройствами являются универсальные процессоры,")
Слайд 23Третий вопрос. Анализ путей повышения эффективности использования
вычислительных систем
Мультипараллельность Адаптивность Самоорганизация Автоматический компромисс аппаратных и программных средств

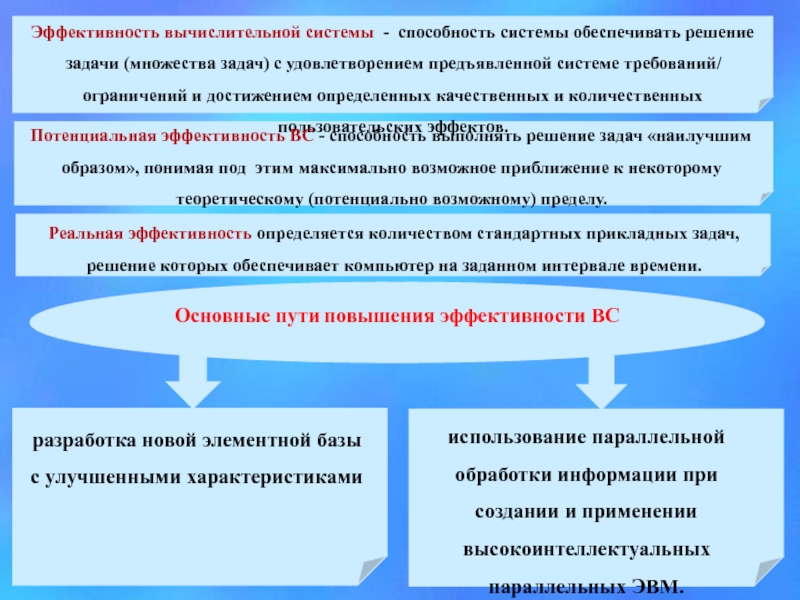

Слайд 26ЗАКОНЫ АМДАЛА
Пусть пиковая производительность однопроцессорной системы равна Т1 , тогда пиковая
производительность системы, состоящей из р таких процессоров, увеличивается в р раз, Т= рТ1 .
Ускорением параллельной системы R назовем отношение ее производительности к производительности соответствующей однопроцессорной системы. Тогда пиковое ускорение R=T/T1=p.
Ускорением параллельной системы R назовем отношение ее производительности к производительности соответствующей однопроцессорной системы. Тогда пиковое ускорение R=T/T1=p.
Первый закон Амдала.
Производительность вычислительной системы, состоящей из нескольких связанных между собой устройств, определяется самым непроизводительным устройством.


Слайд 28Четвертый вопрос. Характеристика методов параллельной обработки данных
Совмещение независимых операций
Конвейерная обработка Декомпозиционная обработка Мультипараллельная смесь



Слайд 31Последовательный (а) и параллельный (б) графы решения задачи, иллюстрирующие метод совмещения
независимых операций
 и параллельный (б) графы решения задачи, иллюстрирующие метод совмещения независимых операций")






