- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Организация данных. Данные, информация, информационные системы презентация
Содержание
- 1. Организация данных. Данные, информация, информационные системы
- 2. Зачем Вам нужен этот курс? У каждой
- 3. Зачем Вам нужен этот курс? Базы данных
- 4. Кем я буду после изучения курса?
- 6. Как получить зачет? 1. Знать, как зовут
- 7. Лекция 1. Данные, информация, информационные системы Данные
- 8. Информация – 1) данные независимо от формы
- 10. Информационная система (ИС, Information system) – система,
- 11. Структурно Информационная система включают в себя: аппаратное
- 12. База данных (Database) – 1) совокупность взаимосвязанных
- 13. Информационная технология (ИТ) – процессы, методы поиска,
- 14. История БД Понятие истории баз данных обобщается
- 15. Древняя история БД Средства учета царской казны
- 16. БД на перфокартах На самых ранних стадиях
- 17. Первая БД Североамериканская компания Rockwell заключила контракт
- 18. Первая БД Столкнувшись с задачей координации заказов
- 19. Лекция 2. Модели данных, проектирование БД
- 20. Проектирование БД Анализ предметной
- 21. Первая стадия проектирования БД предполагает определение диапазона
- 22. Предметная область В основе любой БД лежит
- 23. При проектировании БД предметная область, в соответствии
- 24. Семантическая сеть Семантическая сеть — информационная модель
- 25. Модель сущность-связь (ER-модель) (англ. entity-relationship model, ERM)
- 26. Основные понятия ER-диаграмм
- 27. Иерархическая модель данных — это модель данных,
- 28. Реляционная модель данных ориентирована на организацию данных
- 29. Лекция 3. Нормализация отношений
- 30. Нормальная форма Нормальная форма (НФ) – требование,
- 31. Функциональная зависимость Функциональная зависимость имеет место, если
- 32. Функциональная зависимость Пример Рассмотрим отношение, заданное следующей
- 33. 1 нормальная форма Условия первой нормальной формы:
- 34. 1 нормальная форма Пример. Пусть для отношения
- 35. 1 нормальная форма Преобразование очевидно: отношение заменяется
- 36. 1 нормальная форма Пример 2. Если в
- 37. 1 нормальная форма. Избыточность Таблица 1.2 –
- 38. 1 нормальная форма. Целостность Избыточность данных или
- 39. 1 нормальная форма Проблема возникает из-за того,
- 40. 1 нормальная форма
- 41. 1 нормальная форма Предположим, что в ходе
- 42. 1 нормальная форма Отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ декомпозируем на
- 43. 2 нормальная форма Условия второй нормальной формы:
- 44. 2 нормальная форма Отношение СОТРУДНИКИ_ОТДЕЛЫ не находится
- 45. 3 нормальная форма Условия третьей нормальной формы:
- 46. 3 нормальная форма. Альтернативное определение Условия третьей
- 47. 3 нормальная форма Таблица 5. Отношение СОТРУДНИКИ
- 48. 3 нормальная форма Таблица 5. Отношение СОТРУДНИКИ
- 49. + и - нормализации Как видно из
- 50. Лекция 4. Нормализация отношений. Нормальные формы более
- 51. Критерии оценки качества логической модели данных Легкость
- 52. Критерии оценки качества логической модели данных Скорость
- 53. OLTP и OLAP-системы OLTP (On-Line Transaction Processing
- 54. НФБК (Нормальная Форма Бойса-Кодда) Условия нормальной формы
- 55. Потенциальный ключ
- 56. НФБК (Нормальная Форма Бойса-Кодда) Ситуация, когда отношение
- 57. Четвертая нормальная форма (4NF) Условия четвертой нормальной
- 58. Четвертая нормальная форма Другими словами все строки
- 59. Четвертая нормальная форма Декомпозиция отношения "Абитуриенты-Факультеты-Предметы" не
- 60. Четвертая нормальная форма (4NF) Кажется, что в
- 61. Пятая нормальная форма (5NF) Условия пятой нормальной
- 62. Пятая нормальная форма (5NF) Предположим, что нужно
- 63. Пятая нормальная форма (5NF) Зависимость соединения Х
- 64. Доменно-ключевая нормальная форма Рассмотрим пример с интернет-магазином,
- 65. Нормальная форма Рассмотрим модель данных для деканата.
- 66. Лекция 5. Целостность реляционных данных Для
- 67. Внешние ключи Различные объекты предметной области, информация
- 68. Внешние ключи Разобьем данные по трем отношениям
- 69. Внешние ключи Замечание 1. Внешний ключ, также
- 70. Ссылочная целостность Ссылочная целостность может нарушиться в
- 71. Ссылочная целостность Существуют две основные стратегии поддержания
- 72. 12 правил Кодда 2. Гарантированный доступ -
- 73. Лекция 6. Обзор программного обеспечения для проектирования
- 74. Система управления данными (СУБД, DataBase Management System
- 75. Классификация СУБД Классификация по степени распределённости Локальные
- 76. Файл-серверные В файл-серверных СУБД файлы данных располагаются
- 77. Клиент-серверные Клиент-серверная СУБД располагается на сервере вместе
- 78. Встраиваемые Встраиваемая СУБД – СУБД, которая может
- 79. MySQL Workbench В-третьих, MySQL Workbench позволяет осуществлять
- 80. MySQL Workbench Далее переходим на вкладку «Columns»
- 81. MySQL Workbench После того, как вы создадите
- 82. MySQL Workbench Создание диаграммы БД Для создания
- 83. MySQL Workbench Синхронизация с сервером Это самый
- 84. Лекция 7. Язык SQL SQL (язык структурных
- 85. Операторы SQL DDL (Data Definition Language) -
- 86. Бонусные операторы для MySQL SELECT VERSION(), CURRENT_DATE;
- 87. CREATE DATABASE CREATE DATABASE database_name [ON
- 88. CREATE TABLE Для создания таблиц применяется оператор CREATE
- 89. ALTER TABLE Для изменения структуры существующей таблицы
- 90. Модификация данных Оператор UPDATE Для изменения значений
- 91. Краткий перечень операций реляционной алгебры
- 92. SELECT Выбор данных представляет собой наиболее часто
- 93. SELECT Предложение WHERE Для фильтрации результатов, возвращаемых
- 94. SELECT Применение WHERE Приведем несколько примеров применения
- 95. SELECT Применение ORDER BY Предложение ORDER BY
- 96. SELECT Связывание таблиц В общем случае синтаксис
- 98. SELECT Пример запроса объединяющего 3 таблицы SELECT
- 99. SELECT Подзапросы Решим простую задачу, требующую сравнения
- 100. SELECT Предложение GROUP BY Для вычисления суммарных
- 101. SELECT Агрегатные функции При статистическом анализе баз
- 102. SELECT GROUP BY Строки имеющие одинаковое значение
- 103. SELECT Предложение HAVING Предложение HAVING имеет назначение,
- 104. SELECT Преобразование текста Часто, текстовые значения заполняются
Слайд 1Организация данных
Лектор: к.т.н., старший преподаватель кафедры 105
Каратанов Александр Владимирович

Слайд 2Зачем Вам нужен этот курс?
У каждой мало-мальски серьезной организации есть собственная
Да-да, все данные с Вашей странички Вконтакте и на Фейсбуке также хранятся в базе данных.
Это все лежит в базе данных
Каждый Ваш запрос в Google или Яндексе – это, прежде всего обращение к базе данных.

Слайд 3Зачем Вам нужен этот курс?
Базы данных находят применение повсеместно:
в организациях для
в биллинговых системах для учёта трафика у интернет провайдеров, потреблённых услуг у телефонных операторов, в банковском деле.
в интернет-технологиях для организации хранения учётных записей зарегистрированных пользователей, текстов сообщений на форумах, в гостевых книгах, социальных сетях, интернет-дневниках и в новостных лентах.
без всякого сомнения, базы данных используются поисковыми системами для хранения индексов отсканированных веб-страниц.

Слайд 4Кем я буду после изучения курса?
аналитиком баз данных;
разработчиком баз
системным администратором БД;
кем-то другим;
никем.

Слайд 6Как получить зачет?
1. Знать, как зовут преподавателя.
2. Знать, как называется
3. Сдать все лабораторные.
4. Написать модуль (так, чтобы преподавателю не было стыдно).
5. Сдать ДЗ.
Откуда берутся баллы?

Слайд 7Лекция 1. Данные, информация, информационные системы
Данные – это представление фактов и

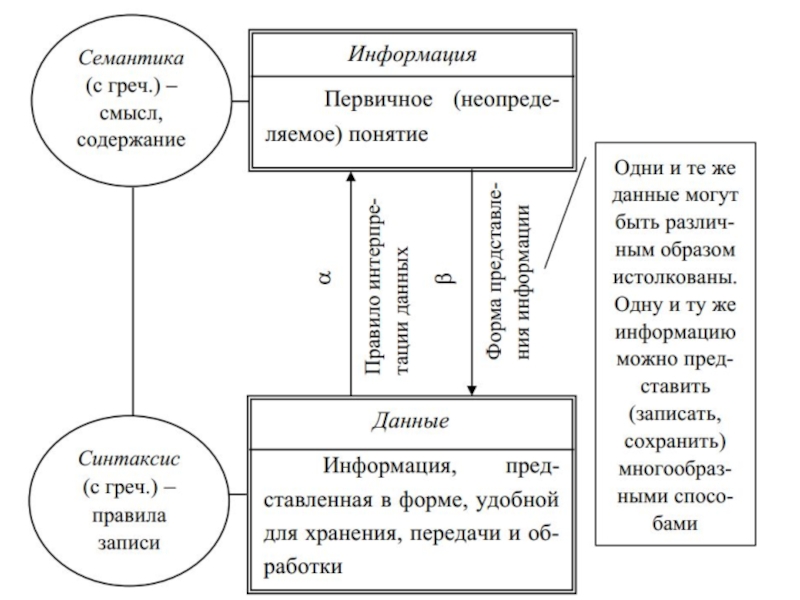
Слайд 8Информация – 1) данные независимо от формы их представления [ГОСТ Р 52653-2006]; примечание -
2) это смысл, который придается данным при их представлении;
3) информация является данным, которым предоставляется некоторое содержание (интерпретация) в конкретной ситуации в рамках некоторой системы понятий.
Данные
Информация
Информация о посещаемости
Информация об оценках
Информация о том, будет ли у студента стипендия
Другая информация
Интерпретация
 данные независимо от формы их представления [ГОСТ Р 52653-2006]; примечание - в соответствии с")
Слайд 10Информационная система (ИС, Information system) – система, которая организует хранение и манипулирование
[ГОСТ 34.321-96].
Прием информации
Хранение и преобразование информации
Вывод информации
Источник
информации
Потребительинформации
Информационная система
Обратная связь
ИС предназначена для своевременного обеспечения надлежащих людей надлежащей информацией.
Результатом функционирования информационных систем является информационная продукция — документы, информационные массивы, базы данных и информационные услуги.
 – система, которая организует хранение и манипулирование информацией о предметной")
Слайд 11Структурно Информационная система включают в себя:
аппаратное обеспечение (hardware),
программное обеспечение (software),
коммуникационное обеспечение
обеспечение промежуточного слоя (middleware),
лингвистическое обеспечение
организационно-технологическое обеспечение.
,программное обеспечение (software),коммуникационное обеспечение (netware), обеспечение промежуточного слоя")
Слайд 12База данных (Database) – 1) совокупность взаимосвязанных данных, организованных в соответствии
2) совокупность данных, организованных в соответствии с концептуальной структурой, описывающей характеристики этих данных и взаимоотношения между ними.
[ГОСТ Р 52653-2006].
 – 1) совокупность взаимосвязанных данных, организованных в соответствии со схемой базы данных")
Слайд 13Информационная технология (ИТ) – процессы, методы поиска, сбора, хранения, обработки, предоставления,
Схема базы данных (Database schema) – формальное описание данных в соответствии с конкретной схемой данных
[ГОСТ 34.321-96].
Схема данных (Data schema) или Модель данных – логическое представление организации данных [ГОСТ 34.321-96].
Модели данных
 – процессы, методы поиска, сбора, хранения, обработки, предоставления, распространения информации и способы")
Слайд 14История БД
Понятие истории баз данных обобщается до истории любых средств, с
Недостатком этого подхода является размывание понятия «база данных» и фактическое его слияние с понятиями «архив» и даже «письменность».

Слайд 15Древняя история БД
Средства учета царской казны и налогов в древнем Шумере
узелковая письменность инков — кипу,
клинописи, содержащие документы Ассирийского царства и т. п.

Слайд 16БД на перфокартах
На самых ранних стадиях развития информационных технологий использовались списки

Слайд 17Первая БД
Североамериканская компания Rockwell заключила контракт с правительством США на участие
Однако в ходе последующей проверки обнаружилась огромная избыточность. Выяснилось, что почти все данные повторяются в двух и более файлах.

Слайд 18Первая БД
Столкнувшись с задачей координации заказов на миллионы деталей, компания Rockwell
Названная IMS (Information Management System — система управления информацией), она заложила основу концепции СУБД.


Слайд 20Проектирование БД
Анализ предметной области.
Проектирование информационной модели.
Разработка даталогической модели.
Физическое проектирование БД.
Процесс проектирования

Слайд 21Первая стадия проектирования БД предполагает определение диапазона действий и границ приложения
Основной задачей этой стадии является сбор требований, предъявляемых всеми пользователями к содержимому БД и процессу обработки информации, который осуществляется для последующего создания основных пользовательских представлений.
Анализ предметной области

Слайд 22Предметная область
В основе любой БД лежит понятие предметной области.
Предметная область –
Предметная область представляется совокупностью реальных и абстрактных объектов, которые характеризуется свойствами. Кроме того, объекты предметной области связаны между собой смысловыми (семантическими) зависимостями.

Слайд 23При проектировании БД предметная область, в соответствии с моделью ANSI/SPARC, рассматривается
представление предметной области в том виде, как она реально существует – инфологическая (информационная, семантическая) модель;
модель данных в том виде, как ее представляет проектировщик БД – даталогическая (логическая) модель;
модель данных в виде, пригодном для хранения во внешней памяти ЭВМ – физическая модель.
Инфологическая модель позволяет представить предметную область в формализованном виде. При этом используются наиболее естественные для человека формы представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому для построения инфологической модели данных используют различные виды семантических моделей: семантические сети, модель «сущность-отношение» (ER-модель), IDEF1X-модель и др.

Слайд 24Семантическая сеть
Семантическая сеть — информационная модель предметной области, имеющая вид ориентированного

Слайд 25Модель сущность-связь (ER-модель) (англ. entity-relationship model, ERM) — модель данных, позволяющая
IDEF1X (IDEF1 Extended) — Data Modeling — методология моделирования баз данных на основе модели «сущность-связь».
Применяется для построения информационной модели, которая представляет структуру информации, необходимой для поддержки функций производственной системы или среды.
 (англ. entity-relationship model, ERM) — модель данных, позволяющая описывать концептуальные схемы предметной")
Слайд 26
Основные понятия ER-диаграмм
Сущность - это класс однотипных объектов, информация о которых должна
Каждая сущность должна иметь наименование, выраженное существительным в единственном числе. Примерами сущностей могут быть такие классы объектов как "Поставщик", "Сотрудник", "Накладная". Каждая сущность в модели изображается в виде прямоугольника с наименованием.
Экземпляр сущности - это конкретный представитель данной сущности.
Например, представителем сущности "Сотрудник" может быть "Сотрудник Фартушный".
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные для каждого экземпляра этой сущности.
Атрибут сущности - это именованная характеристика, являющаяся некоторым свойством сущности.
Наименование атрибута должно быть выражено существительным в единственном числе (возможно, с характеризующими прилагательными).
Примерами атрибутов сущности "Сотрудник" могут быть такие атрибуты как "Табельный номер", "Фамилия", "Имя", "Отчество", "Должность", "Зарплата" и т.п.
Атрибуты изображаются в пределах прямоугольника, определяющего сущность.
Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности.
Это минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности.
Ключевые атрибуты изображаются на диаграмме подчеркиванием.
Связь - это некоторая ассоциация между двумя сущностями.
Одна сущность может быть связана с другой сущностью или сама с собою.
Например, связи между сущностями могут выражаться следующими фразами –
"СОТРУДНИК может иметь несколько ДЕТЕЙ", "каждый СОТРУДНИК обязан числиться ровно в одном ОТДЕЛЕ".
Графически связь изображается линией, соединяющей две сущности.

Слайд 27Иерархическая модель данных — это модель данных, где используется представление базы
в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможна ситуация, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами (в программировании применительно к структуре данных «дерево» устоялось название братья).
Корень
Потомок
Предок
Порядок обхода
")
Слайд 28Реляционная модель данных ориентирована на организацию данных в виде отношений
(англ.
Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков.
В сетевой модели возможны связи всех информационных объектов со всеми.
Например, каждый преподаватель может обучать много студентов и каждый студент может обучаться у многих преподавателей
Использование иерархической и сетевой моделей ускоряет доступ к информации,
но требует значительных ресурсов памяти,
так как каждый элемент данных содержит ссылки на другие элементы.
Характерна сложность реализации СУБД.
Разработана в начале 1970-х годов Эдгаром Ф. Коддом.
Даталогическая модель проектируется на основании информационной модели, посредством ее нормализации и приведения к третьей нормальной форме.
.Разница между иерархической")
Слайд 29Лекция 3. Нормализация отношений
Процесс нормализации был впервые предложен Эдгаром Франком Коддом
Нормализация – это последовательный процесс разбиения и преобразования некоторого небольшого исходного набора таблиц для построения набора взаимосвязанных таблиц в нормальных формах.
Определение для альтернативно одаренных
Нормализация – это когда у нас было много таблиц, а мы сделаем еще больше, чтобы они соответствовали каким-то там правилам.

Слайд 30Нормальная форма
Нормальная форма (НФ) – требование, предъявляемое к структуре таблиц в
Всего существует восемь НФ:
– 1–6 НФ;
– доменно-ключевая НФ;
– НФ Бойса-Кодда.
 – требование, предъявляемое к структуре таблиц в теории реляционных баз данных")
Слайд 31Функциональная зависимость
Функциональная зависимость имеет место, если значение кортежа на одном множестве
Другими словами, множество атрибутов Y функционально зависит от X тогда и только тогда, когда в любой момент времени для каждого из различных значений Y существует только одно из различных значений X.
Встречается и эквивалентный термин: множество X определяет Y.
Обозначение –
X → Y.
Каждый из уровней нормализации ограничивает типы допустимых функциональных зависимостей отношения.
детерминанта
зависимая часть

Слайд 32Функциональная зависимость
Пример
Рассмотрим отношение, заданное следующей схемой:
график (Пилот, Рейс, Дата, Время).
Ясно, что
для каждого рейса определено лишь одно время вылета;
для атрибутов (Пилот, Дата, Время) определен лишь один рейс;
для атрибутов (Рейс, Дата) определен единственный пилот.
Таким образом, задано множество функциональных зависимостей:
Рейс → Время
(Пилот, Дата, Время)→ Рейс
(Рейс, Дата)→ Пилот
.Ясно, что допустимо не любое сочетание")
Слайд 331 нормальная форма
Условия первой нормальной формы:
каждой сущности соответствует отдельная таблица;
каждый набор
поля не имеют дубликатов в каждой записи;
каждое поле содержит только одно значение (атомарно).
Атомарность (неделимость) поля означает, что содержащиеся в нем значения не должны делиться на более мелкие.

Слайд 341 нормальная форма
Пример. Пусть для отношения со схемой Рейс (Номер, Пункт
В этом случае легко реализовать запросы типа «Выдать все рейсы до Уфы», в отличие от запроса «Выдать все рейсы, вылетающие по понедельникам». С точки зрения второй задачи отношение не находится в 1НФ.
Дублирование информации
Отсутствие атомарности
 атрибут Вылет")
Слайд 351 нормальная форма
Преобразование очевидно: отношение заменяется другим со схемой:
Рейс (Номер,
Это позволит достичь атомарности.
Выделение для пунктов назначения отдельной таблицы устранит дублирование информации.

Слайд 361 нормальная форма
Пример 2. Если в поле «Подразделение» содержится название факультета

Слайд 371 нормальная форма. Избыточность
Таблица 1.2 – «Работник»
Таблица 1.1 – «Работник»
Избыточность данных
Приведение к первой нормальной форме провоцирует избыточность

Слайд 381 нормальная форма. Целостность
Избыточность данных или повторение приводит не только к
Чтобы добиться целостности следует устранить аномалии.
Целостность данных – согласованность данных в базе данных.
Аномалия удаления – непреднамеренная потеря данных, вызванная удалением других данных.
Аномалия обновления – противоречивость данных, вызванная их избыточностью и частичным обновлением.
Аномалия ввода – невозможность ввести данные в таблицу, вызванная отсутствием других данных.

Слайд 391 нормальная форма
Проблема возникает из-за того, что один и тот же
Теперь предположим, что Мирненко в течение трех месяцев был на больничном и все здания, на которых он был назначен работать, уже закончены. Если принимается решение удалить все строки о законченных зданиях из таблицы, то информация о Мирненко, его специальности будет потеряна. Это называется аномалией удаления.
Обратный случай: мы могли нанять нового работника по фамилии Алдошин, которого еще не успели назначить ни на какое здание. Если мы не допускаем пустых значений, то не можем ввести информацию о Алдошине в базу данных. Это называется аномалией ввода.


Слайд 411 нормальная форма
Предположим, что в ходе логического моделирования на первом шаге
СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ (Н_СОТР, ФАМ, Н_ОТД, ТЕЛ, Н_ПРО, ПРОЕКТ, Н_ЗАДАН)
Где Н_СОТР - табельный номер сотрудника,
ФАМ - фамилия сотрудника,
Н_ОТД - номер отдела, в котором числится сотрудник,
ТЕЛ - телефон сотрудника,
Н_ПРО - номер проекта, над которым работает сотрудник,
ПРОЕКТ - наименование проекта, над которым работает сотрудник,
Н_ЗАДАН - номер задания, над которым работает сотрудник.
Т.к. каждый сотрудник в каждом проекте выполняет ровно одно задание, то в качестве потенциального ключа отношения необходимо взять пару атрибутов (Н_СОТР, Н_ПРО).
В текущий момент состояние предметной области отражается следующими фактами:
Сотрудник Сусловец, работающий в 1 отделе, выполняет в первом проекте "Космос" задание 1 и во втором проекте "Климат" задание 1.
Сотрудник Сусловец, работающий в 1 отделе, выполняет в первом проекте "Космос" задание 2.
Сотрудник Волошина, работающий во 2 отделе, выполняет в первом проекте "Космос" задание 3 и во втором проекте "Климат" задание 2.
Это состояние отражается в таблице (курсивом выделены ключевые атрибуты):
Из таблицы СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ
видно, что данные отношения хранятся
в ней с большой избыточностью.
Во многих строках повторяются фамилии сотрудников, номера телефонов, наименования проектов. Кроме того, в данном отношении хранятся вместе независимые друг от друга данные - и данные о сотрудниках, и об отделах, и о проектах, и о работах по проектам.

Слайд 421 нормальная форма
Отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ декомпозируем на три отношения - СОТРУДНИКИ_ОТДЕЛЫ, ПРОЕКТЫ,
Таблица 2. Отношение СОТРУДНИКИ_ОТДЕЛЫ
Таблица 3. Отношение ПРОЕКТЫ
Функциональные зависимости:
Н_ПРО → ПРОЕКТ
Таблица 4. Отношения ЗАДАНИЯ
Функциональные зависимости:
(Н_СОТР, Н_ПРО) → Н_ЗАДАН
Функциональные зависимости:
Зависимость атрибутов, характеризующих сотрудника от табельного номера сотрудника:
Н_СОТР → ФАМ
Н_СОТР → Н_ОТД
Н_СОТР → ТЕЛ
Зависимость номера телефона от номера отдела:
Н_ОТД → ТЕЛ

Слайд 432 нормальная форма
Условия второй нормальной формы:
модель удовлетворяет условиям 1 НФ;
все поля
Замечание. Если ключ отношения является простым, то отношение автоматически находится в 2НФ.

Слайд 442 нормальная форма
Отношение СОТРУДНИКИ_ОТДЕЛЫ не находится в 2НФ, т.к. есть атрибуты,
(фамилия сотрудника не зависит от номера отдела)
Для того, чтобы устранить зависимость атрибутов от части сложного ключа, нужно произвести декомпозицию отношения на несколько отношений. При этом те атрибуты, которые зависят от части сложного ключа, выносятся в отдельное отношение.
Таблица 2. Отношение СОТРУДНИКИ_ОТДЕЛЫ

Слайд 453 нормальная форма
Условия третьей нормальной формы:
модель удовлетворяет условиям 2 НФ;
все не
Неключевой атрибут — это атрибут, который не входит в состав первичного ключа рассматриваемой переменной-отношения.
Два или более атрибутов называются взаимно независимыми, если ни один из них функционально не зависит от какой-либо комбинации остальных атрибутов. Подобная независимость подразумевает, что каждый такой атрибут может обновляться независимо от значений остальных атрибутов.

Слайд 463 нормальная форма. Альтернативное определение
Условия третьей нормальной формы:
модель удовлетворяет условиям 2
отсутствует транзитивная функциональная зависимость не ключевых полей от первичного ключа.
Неключевой атрибут — это атрибут, который не входит в состав первичного ключа рассматриваемой переменной-отношения.
Два или более атрибутов называются взаимно независимыми, если ни один из них функционально не зависит от какой-либо комбинации остальных атрибутов. Подобная независимость подразумевает, что каждый такой атрибут может обновляться независимо от значений остальных атрибутов.

Слайд 473 нормальная форма
Таблица 5. Отношение СОТРУДНИКИ
Таблица 6. Отношение ОТДЕЛЫ
При
Для приведения ко второй нормальной форме мы разбили эту таблицу:
Однако могли поступить и проще – убрать составной первичный ключ:
Вот эта модель данных также соответствует второй нормальной форме.

Слайд 483 нормальная форма
Таблица 5. Отношение СОТРУДНИКИ
Таблица 6. Отношение ОТДЕЛЫ
Отношение
Но таким образом вы всего лишь отодвинете свои страдания по нормализации до 3 НФ, вам все равно придется разбить эту таблицу на две.

Слайд 49+ и - нормализации
Как видно из таблицы, более сильно нормализованные отношения

Слайд 50Лекция 4. Нормализация отношений. Нормальные формы более высоких порядков
Критерии оценки качества
Для того чтобы оценить качество принимаемых решений на уровне логической модели данных, необходимо сформулировать некоторые критерии качества и посмотреть, как различные решения, принятые в процессе логического моделирования, влияют на скорость и качество работы базы данных.
Рассмотрим некоторые из таких критериев, которые являются безусловно важными с точки зрения получения качественной базы данных:
- адекватность базы данных предметной области;
- легкость разработки и сопровождения базы данных;
- скорость выполнения операций обновления данных (вставка, обновление, удаление кортежей);
- скорость выполнения операций выборки данных.
Адекватность базы данных предметной области
База данных должна адекватно отражать предметную область. Это означает, что должны выполняться следующие условия:
- состояние базы данных в каждый момент времени должно соответствовать состоянию предметной области;
- изменение состояния предметной области должно приводить к соответствующему изменению состояния базы данных;
- ограничения предметной области, отраженные в модели предметной области, должны некоторым образом отражаться и учитываться базе данных.

Слайд 51Критерии оценки качества логической модели данных
Легкость разработки и сопровождения базы данных
Практически
Очевидно, что чем больше программного кода в виде триггеров и хранимых процедур содержит база данных, тем сложнее ее разработка и дальнейшее сопровождение.
Хранимые процедуры - это процедуры и функции, хранящиеся непосредственно в БД в откомпилированном виде и которые могут запускаться пользователями или приложениями, работающими с БД. Хранимые процедуры обычно пишутся либо на специальном процедурном расширении языка SQL (например, PL/SQL для ORACLE или Transact-SQL для MS SQL Server), или на некотором универсальном языке программирования, например, C++, с включением в код операторов SQL в соответствии со специальными правилами такого включения.
Основное назначение хранимых процедур - реализация бизнес-процессов предметной области.
Триггеры - это хранимые процедуры, связанные с некоторыми событиями, происходящими во время работы БД. В качестве таких событий выступают операции вставки, обновления и удаления строк таблиц. Если в базе данных определен некоторый триггер, то он запускается автоматически всегда при возникновении события, с которым этот триггер связан. Очень важным является то, что пользователь не может обойти триггер. Триггер срабатывает независимо от того, кто из пользователей и каким способом инициировал событие, вызвавшее запуск триггера. Таким образом, основное назначение триггеров - автоматическая поддержка целостности базы данных. Триггеры могут быть как достаточно простыми, например, поддерживающими ссылочную целостность, так и довольно сложными, реализующими какие-либо сложные ограничения предметной области или сложные действия, которые должны произойти при наступлении некоторых событий.
Например, с операцией вставки нового товара в накладную может быть связан триггер, который выполняет следующие действия - проверяет, есть ли необходимое количество товара, при наличии товара добавляет его в накладную и уменьшает данные о наличии товара на складе, при отсутствии товара формирует заказ на поставку недостающего товара и тут же посылает заказ по электронной почте поставщику.

Слайд 52Критерии оценки качества логической модели данных
Скорость операций обновления данных (вставка, обновление,
В базах данных, требующих постоянных изменений (складской учет, системы продаж билетов и т.п.) производительность определяется скоростью выполнения большого количества небольших операций вставки, обновления и удаления.
Скорость выполнения операций вставки, обновления и удаления уменьшается при увеличении количества индексов у таблицы.
Чем больше атрибутов имеют отношения, разработанные в ходе логического моделирования, тем медленнее будут выполняться операции обновления данных, за счет затраты времени на перестройку большего количества индексов.
Скорость операций выборки данных
Увеличение количества взаимосвязанных отношений (для которых необходима операция соединения таблиц ) приводит к замедлению выполнения операций выборки данных.
Индексы - это специальные структуры в базах данных, которые позволяют ускорить поиск и сортировку по определенному полю или набору полей в таблице.
Например мы хотим найти запись, удовлетворяющую условию:
SELECT * FROM Customers
WHERE CustomerID = ‘ROMEY’
SQL Server прочитает все записи начиная с первой и заканчивая последней и выберет те, которые будут удовлетворять указанному условию.
SQL Server не знает что в таблице существует только одна запись, удовлетворяющая условию, пока в таблице не существует индекса.
Информация извлекается из реляционной базы данных при помощи оператора SQL - SELECT. Одной из наиболее дорогостоящих операций при выполнении оператора SELECT является операция соединение таблиц. Таким образом, чем больше взаимосвязанных отношений было создано в ходе логического моделирования, тем больше вероятность того, что при выполнении запросов эти отношения будут соединяться, и, следовательно, тем медленнее будут выполняться запросы. Таким образом, увеличение количества отношений приводит к замедлению выполнения операций выборки данных, особенно, если запросы заранее неизвестны.
Индексы отличаются от первичных ключей тем, что не требуют непременной уникальности значений входящих в их состав полей.
В базах данных, требующих")
Слайд 53OLTP и OLAP-системы
OLTP (On-Line Transaction Processing – оперативная обработка транзакций) –
Сильно нормализованные модели данных хорошо подходят для так называемых OLTP-приложения.
Типичными примерами OLTP-приложений являются:
системы складского учета,
системы заказов билетов,
банковские системы, выполняющие операции по переводу денег…
Основная функция подобных систем заключается в выполнении большого количества коротких транзакций.
Другим типом приложений являются так называемые OLAP-приложения. Это обобщенный термин, характеризующий принципы построения:
систем поддержки принятия решений (Decision Support System - DSS),
хранилищ данных (Data Warehouse),
систем интеллектуального анализа данных (Data Mining).
Такие системы предназначены для нахождения зависимостей между данными (например, можно попытаться определить, как связан объем продаж товаров с характеристиками потенциальных покупателей), для проведения анализа "что если…".
Данные в таких системах целесообразно хранить в виде слабо нормализованных отношений, содержащих заранее вычисленные основные итоговые данные. Большая избыточность и связанные с ней проблемы тут не страшны, т.к. обновление происходит только в момент загрузки новой порции данных.
OLAP (On-Line Analitical Processing - оперативная аналитическая обработка данных) – это способ организации БД, заключающаяся в подготовке суммарной (агрегированной) информации на основе больших массивов данных, структурированных по многомерному принципу.
 – это способ организации БД,")
Слайд 54НФБК (Нормальная Форма Бойса-Кодда)
Условия нормальной формы Бойса-Кодда:
модель удовлетворяет условиям 3 НФ;
детерминанты
Условия нормальной формы Бойса-Кодда:модель удовлетворяет условиям 3 НФ;детерминанты всех функциональных зависимостей являются")
Слайд 55Потенциальный ключ
В отношении может быть одновременно несколько потенциальных ключей.
Один из
Теоретически, все потенциальные ключи равно пригодны в качестве первичного ключа, на практике в качестве первичного обычно выбирается тот из потенциальных ключей, который имеет меньший размер (физического хранения) и/или включает меньшее количество атрибутов.
Потенциальный ключ — в реляционной модели данных — подмножество атрибутов отношения, удовлетворяющее требованиям уникальности и минимальности (несократимости / атомарности).
Уникальность означает, что не существует двух кортежей данного отношения, в которых значения этого подмножества атрибутов совпадают (равны).

Слайд 56НФБК (Нормальная Форма Бойса-Кодда)
Ситуация, когда отношение будет находится в 3NF, но
Заметим, что на практике такая ситуация встречается достаточно редко, для всех прочих отношений 3NF и BCNF эквивалентны.
Существует функциональная зависимость Тариф → Номер корта, в которой левая часть (детерминант) не является потенциальным ключом отношения, то есть отношение не находится в нормальной форме Бойса — Кодда.
Недостатком данной структуры является то, что, например, по ошибке можно приписать тариф «Бережливый» к бронированию 2 корта, хотя он может относиться только к 1корту.
Ситуация, когда отношение будет находится в 3NF, но не в BCNF, возникает")
Слайд 57Четвертая нормальная форма (4NF)
Условия четвертой нормальной формы:
модель удовлетворяет условиям НФБК;
все нетривиальные
Условия четвертой нормальной формы:модель удовлетворяет условиям НФБК;все нетривиальные многозначные зависимости фактически являются")
Слайд 58Четвертая нормальная форма
Другими словами все строки таблицы должны быть независимыми друг
В том смысле, что наличие какой-то строки X, не должно означать, что строка Y тоже где-то есть в этой таблице.
Отношения с нетривиальными многозначными зависимостями возникают, как правило, в результате естественного соединения двух отношений по общему полю, которое не является ключевым ни в одном из отношений. Фактически это приводит к попытке хранить в одном отношении информацию о двух независимых сущностях.
В качестве примера можно привести ситуацию, когда сотрудник может иметь много работ и много детей. Хранение информации о работах и детях в одном отношении приводит к возникновению нетривиальной многозначной зависимости Работник-Работа-Дети.

Слайд 59Четвертая нормальная форма
Декомпозиция отношения "Абитуриенты-Факультеты-Предметы" не может быть выполнена на основе
В отношении "Абитуриенты-Факультеты-Предметы" имеется именно нетривиальная многозначная зависимость Факультет→→ Абитуриент | Предмет.

Слайд 60Четвертая нормальная форма (4NF)
Кажется, что в отношении имеется аномалия обновления, связанная
Аномалия вставки. При попытке добавить в отношение "Абитуриенты-Факультеты-Предметы" новый кортеж, например (Красношапка, Самолетостроительный, Математика), мы обязаны добавить также и кортеж (Красношапка, Самолетостроительный, Информатика), т.к. все абитуриенты самолетостроительного факультета обязаны иметь один и тот же список сдаваемых предметов. Соответственно, при попытке вставить в модифицированное отношении кортеж (3, 1, 1), мы обязаны вставить в него также и кортеж (3, 1, 2).
Аномалия удаления. При попытке удалить кортеж (Руденкова, СУЛА, Математика), мы обязаны удалить также и кортеж (Руденкова, СУЛА, Физика) по той же самой причине.
Таким образом, вставка и удаление кортежей не может быть выполнена независимо от других кортежей отношения.
Кроме того, если мы удалим эти кортежи, то будет потеряна информация о предметах, которые должны сдаваться на факультете СУЛА.
Кажется, что в отношении имеется аномалия обновления, связанная с тем, что дублируются")
Слайд 61Пятая нормальная форма (5NF)
Условия пятой нормальной формы (проекционно-соединительной нормальной форме):
модель удовлетворяет
каждая нетривиальная зависимость соединения в нём определяется потенциальным ключом (ключами) этого отношения;
любая имеющаяся зависимость соединения является тривиальной.
Условия пятой нормальной формы (проекционно-соединительной нормальной форме):модель удовлетворяет условиям 4 НФ; каждая")
Слайд 62Пятая нормальная форма (5NF)
Предположим, что нужно учесть следующее ограничение: каждый продавец
В рассматриваемом примере, в частности, предполагается, что продавец Железняк имеет право торговать товарами только фирмы «Рога и Копыта», продавец Кривенко — товарами только фирмы «Калашников», зато продавец Ломова не имеет право торговать барбитуратами и стероидами и т.д.
Товары продавцов
Фирмы продавцов
Товары фирм
Предположим, что нужно учесть следующее ограничение: каждый продавец имеет в своём ассортименте")
Слайд 63Пятая нормальная форма (5NF)
Зависимость соединения Х называется нетривиальной зависимостью соединения, если
- одно из множеств атрибутов Х не содержит потенциального ключа отношения Y.
- ни одно из множеств атрибутов Х не совпадает со всем множеством атрибутов отношения Y.
Для удобства работы сформулируем это определение так же и в отрицательной форме.
Зависимость соединения Х называется тривиальной зависимостью соединения, если выполняется одно из условий:
- либо все множества атрибутов X содержат потенциальный ключ отношения Y;
- либо одно из множеств атрибутов X совпадает со всем множеством атрибутов отношения Y.
Шестая нормальная форма
Модель находится в шестой нормальной форме тогда и только тогда, когда она удовлетворяет всем нетривиальным зависимостям соединения.
Эта модель является финальной и не может быть подвергнута дальнейшей декомпозиции без потерь.
Практически не применяется. Для хронологических баз данных максимально возможная декомпозиция позволяет бороться с избыточностью и упрощает поддержание целостности базы данных.
Зависимость соединения Х называется нетривиальной зависимостью соединения, если выполняется два условия: -")
Слайд 64Доменно-ключевая нормальная форма
Рассмотрим пример с интернет-магазином, в котором есть некие товары.
Рассмотрим тот же самый пример но с триггером. Мы удаляем некую категорию (не дефолтовую). Срабатывает триггер и удаляет все товары, связанные с этой категорией. Таким образом, при удалении категории у нас не образуется товаров "подвешенных в воздухе". Целостность данных сохранена.
В данный момент нет никакой информации о том база в какой нормальной форме может быть приведена к ДКНФ. Т.е. можно пытаться приводить базу к этой форме из 3НФ, 2НФ или даже 1НФ. Не факт, что это у вас до конца получится. Однако даже если не получится, прописанные правила добавления и удаления записей а так же ограничения на поля, существенно повысят качество разрабатываемой вами БД.
Альтернативное определение: переменная отношения находится в ДКНФ тогда и только тогда, когда каждое наложенное на неё ограничение является логическим следствием ограничений доменов и ограничений ключей, наложенных на данную переменную отношения.
Это достигается добавлением дополнительных ограничений на значения полей записи. Поддержание целостности данных возлагается на механизмы конкретной СУБД. Например дефолтовые значения полей, ограничения диапазон данных, триггеры, срабатывающие при создании, модификации или удалении записей и так далее. Словом всё что угодно, что способствует сохранению целостности данных. Её предложил Рональд Фагин в 1981 году.
Доменно-ключевая нормальная форма (ДКНФ) - это такая форма, когда любая операция добавления или удаления записи не может привести к нарушению целостности данных.
Ограничение домена – ограничение, предписывающее использовать для определённого атрибута значения только из некоторого заданного домена. Ограничение по своей сути является заданием перечня (или логического эквивалента перечня) допустимых значений типа и объявлением о том, что указанный атрибут имеет данный тип.
Ограничение ключа – ограничение, утверждающее, что некоторый атрибут или комбинация атрибутов является потенциальным ключом.
Любая переменная отношения, находящаяся в ДКНФ, обязательно находится в 5НФ. Однако не любую переменную отношения можно привести к ДКНФ.


Слайд 66Лекция 5. Целостность реляционных данных
Для реляционной модели данных определяются два ограничения,
целостность сущностей,
целостность внешних ключей.
Прежде, чем говорить о целостности сущностей, опишем использование null-значений в реляционных базах данных.
Null-значения
Основное назначение баз данных состоит в том, чтобы хранить и предоставлять информацию о реальном мире. Для представления этой информации в базе данных используются привычные для программистов типы данных - строковые, численные, логические и т.п. Однако в реальном мире часто встречается ситуация, когда данные неизвестны или не полны. Например, место жительства или дата рождения человека могут быть неизвестны (база данных разыскиваемых преступников). Если вместо неизвестного адреса уместно было бы вводить пустую строку, то что вводить вместо неизвестной даты? Ответ - пустую дату - не вполне удовлетворителен, т.к. простейший запрос "выдать список людей в порядке возрастания дат рождения" даст заведомо неправильных ответ.
Null - это некий маркер, показывающий, что значение неизвестно, который используется для того чтобы обойти проблему неполных или неизвестных данных.
Правило целостности сущностей - атрибуты, входящие
в состав некоторого потенциального ключа не могут принимать null-значений.
Правило целостности внешних ключей - внешние ключи не должны быть несогласованными, т.е. для каждого значения внешнего ключа должно существовать соответствующее значение первичного ключа в родительском отношении.

Слайд 67Внешние ключи
Различные объекты предметной области, информация о которых хранится в базе
Рассмотрим пример с поставщиками и поставками алкоголя. Предположим, что нам требуется хранить информацию о наименовании поставщиков, наименовании и количестве поставляемого ими алкоголя, причем каждый поставщик может поставлять несколько видов алкоголя и каждая разновидность алкоголя может поставляться несколькими поставщиками.
Приведенный способ хранения данных обладает рядом недостатков.
Что произойдет, если изменилось наименование поставщика? Т.к. наименование поставщика повторяется во многих кортежах отношения, то это наименование нужно одновременно изменить во всех кортежах, где оно встречается, иначе данные станут противоречивыми. То же самое с наименованиями деталей. Значит, данные хранятся в нашем отношении с большой избыточностью.
Далее, как отразить факт, что некоторый поставщик, например Холодняк, временно прекратил поставки алкоголя? Если мы удалим все кортежи, в которых хранится информация о поставках этого поставщика, то мы потеряем данные о самом Петрове как потенциальном поставщике. Выйти из этого положения, оставив в отношении кортеж типа (2, Холодняк, NULL, NULL, NULL) мы не можем, т.к. атрибут "Номер алкоголя" входит в состав потенциального ключа и не может содержать null-значений. То же самое произойдет, если некоторый алкоголь временно не поставляется никаким поставщиком. Получается, что мы не можем хранить информацию о том, что есть некий поставщик, если он не поставляет хотя бы один вид алкоголя, и не можем хранить информацию о том, что есть некоторое бухло, если оно никем не поставляется. Это проблема плохой нормализации.
Отношение "Поставщики и поставляемые детали"
Потенциальным ключом этого отношения может выступать пара атрибутов {"Номер поставщика", "Номер алкоголя"} - в таблице они выделены подчеркиванием.

Слайд 68Внешние ключи
Разобьем данные по трем отношениям - "Поставщики", "Алкоголь", "Поставки". Для
Отношение "Поставщики и поставляемые детали"
Взаимосвязь между "Поставщиками" и " Алкоголем" можно переформулировать так: "Несколько видов Алкоголя может поставляться несколькими Поставщиками". Это пример взаимосвязи типа "много-ко-многим".
В реляционных базах данных основными являются взаимосвязи типа "один-ко-многим". Взаимосвязи типа "много-ко-многим" реализуются использованием нескольких взаимосвязей типа "один-ко-многим".
Отношение, входящее в связь со стороны "один" (например, "Поставщики"), называют родительским отношением. Отношение, входящее в связь со стороны "много" (например, "Поставки"), называется дочернем отношением.
Эти фразы отражают различные типы взаимосвязей. Чтобы более точно отразить предметную область, можно иначе переформулировать фразы: "Один Поставщик может выполнять несколько Поставок", "Один вид Алкоголя может поставляться несколькими Поставками". Это пример взаимосвязи типа "один-ко-многим".
Отношение «Поставщик»
Отношение «Алкоголь»
Отношение «Поставка»
Найдите внешние ключи?

Слайд 69Внешние ключи
Замечание 1. Внешний ключ, также как и потенциальный, может быть
Замечание 2. Внешний ключ должен быть определен на тех же доменах, что и соответствующий первичный ключ родительского отношения.
Замечание 3. Внешний ключ, как правило, не обладает свойством уникальности. Так и должно быть, т.к. в дочернем отношении может быть несколько кортежей, ссылающихся на один и тот же кортеж родительского отношения. Это, собственно, и дает тип отношения "один-ко-многим".
Замечание 4. Если внешний ключ все-таки обладает свойством уникальности, то связь между отношениями имеет тип "один-к-одному". Чаще всего такие отношения объединяются в одно отношение, хотя это и не обязательно.
Домен в реляционной модели данных — тип данных, то есть допустимое множество значений.
Примерами могут являться типы «целое» (множество всех целых чисел), «строка» (множество всех строк), «номер детали» (множество всех номеров деталей) и т. д. Таким образом, когда мы говорим, что некоторое отношение имеет атрибут типа «целое», мы имеем в виду, что все значения этого атрибута принадлежат множеству «целое» и никакому другому.
Замечание 5. Хотя каждое значение внешнего ключа обязано совпадать со значениями потенциального ключа в некотором кортеже родительского отношения, то обратное, вообще говоря, неверно. Например, могут существовать поставщики, не поставляющие никаких деталей.
Замечание 6. Для внешнего ключа не требуется, чтобы он был компонентом некоторого потенциального ключа (как получилось в примере с поставщиками и деталями).
Замечание 7. Null-значения для атрибутов внешнего ключа допустимы только в том случае, когда атрибуты внешнего ключа не входят в состав никакого потенциального ключа.

Слайд 70Ссылочная целостность
Ссылочная целостность может нарушиться в результате операций, изменяющих состояние базы
Для родительского отношения
Вставка кортежа в родительском отношении. При вставке кортежа в родительское отношение возникает новое значение потенциального ключа. Т.к. допустимо существование кортежей в родительском отношении, на которые нет ссылок из дочернего отношения, то вставка кортежей в родительское отношение не нарушает ссылочной целостности.
Обновление кортежа в родительском отношении. При обновлении кортежа в родительском отношении может измениться значение потенциального ключа. Если есть кортежи в дочернем отношении, ссылающиеся на обновляемый кортеж, то значения их внешних ключей станут некорректными. Обновление кортежа в родительском отношении может привести к нарушению ссылочной целостности, если это обновление затрагивает значение потенциального ключа.
Удаление кортежа в родительском отношении. При удалении кортежа в родительском отношении удаляется значение потенциального ключа. Если есть кортежи в дочернем отношении, ссылающиеся на удаляемый кортеж, то значения их внешних ключей станут некорректными. Удаление кортежей в родительском отношении может привести к нарушению ссылочной целостности.
Для дочернего отношения
Вставка кортежа в дочернее отношение. Нельзя вставить кортеж в дочернее отношение, если вставляемое значение внешнего ключа некорректно. Вставка кортежа в дочернее отношение привести к нарушению ссылочной целостности.
Обновление кортежа в дочернем отношении. При обновлении кортежа в дочернем отношении можно попытаться некорректно изменить значение внешнего ключа. Обновление кортежа в дочернем отношении может привести к нарушению ссылочной целостности.
Удаление кортежа в дочернем отношении. При удалении кортежа в дочернем отношении ссылочная целостность не нарушается.
Таким образом, ссылочная целостность в принципе может быть нарушена при выполнении одной из четырех операций:
Обновление кортежа в родительском отношении.
Удаление кортежа в родительском отношении.
Вставка кортежа в дочернее отношение.
Обновление кортежа в дочернем отношении.

Слайд 71Ссылочная целостность
Существуют две основные стратегии поддержания ссылочной целостности. Эти стратегии являются
RESTRICT (ОГРАНИЧИТЬ) – не разрешать выполнение операции, приводящей к нарушению ссылочной целостности. Это самая простая стратегия, требующая только проверки, имеются ли кортежи в дочернем отношении, связанные с некоторым кортежем в родительском отношении.
CASCADE (КАСКАДИРОВАТЬ) – разрешить выполнение требуемой операции, но внести при этом необходимые поправки в других отношениях так, чтобы не допустить нарушения ссылочной целостности и сохранить все имеющиеся связи. Изменение начинается в родительском отношении и каскадно выполняется в дочернем отношении. В реализации этой стратегии имеется одна тонкость, заключающаяся в том, что дочернее отношение само может быть родительским для некоторого третьего отношения. При этом может дополнительно потребоваться выполнение какой-либо стратегии и для этой связи и т.д. Если при этом какая-либо из каскадных операций (любого уровня) не может быть выполнена, то необходимо отказаться от первоначальной операции и вернуть базу данных в исходное состояние. Это самая сложная стратегия, но она хороша тем, что при этом не нарушается связь между кортежами родительского и дочернего отношений.
0. Реляционная СУБД должна быть способна полностью управлять базой данных через ее реляционные возможности.
1. Информационное правило - вся информация в реляционной БД (включая имена таблиц и столбцов) должна определяться строго как значения в таблицах.
12 правил Кодда

Слайд 7212 правил Кодда
2. Гарантированный доступ - любое значение в реляционной БД
3. Поддержка пустых значений (null value) - СУБД должна уметь работать с пустыми значениями (неизвестными или неиспользованными значениями), в отличие от значений по умолчанию и независимо для любых доменов.
4. Онлайновый реляционный каталог - описание БД и ее содержания должны быть представлены на логическом уровне как таблицы, к которым можно применять запросы, используя язык базы данных.
5. Исчерпывающий язык управления данными - по крайней мере, один из поддерживаемых языков должен иметь четко определенный синтаксис и быть всеобъемлющим. Он должен поддерживать описание структуры данных и манипулирование ими, правила целостности, авторизацию и транзакции. 6. Правило обновления представлений (views) - все представления, теоретически обновляемые, могут быть обновлены через систему. 7. Вставка, обновление и удаление - СУБД поддерживает не только запрос на отбор данных, но и вставку, обновление и удаление
8. Физическая независимость данных - на программы-приложения и специальные программы логически не влияют изменения физических методов доступа к данным и структур хранилищ данных. 9. Логическая независимость данных - на программы-приложения и специальные программы логически не влияют, в пределах разумного, изменения структур таблиц.
10. Независимость целостности - язык БД должен быть способен определять правила целостности. Они должны сохраняться в онлайновом справочнике, и не должно существовать способа их обойти. 11. Независимость распределения - на программы-приложения и специальные программы логически не влияет, первый раз используются данные или повторно. 12. Неподрывность - невозможность обойти правила целостности, определенные через язык базы данных, использованием языков низкого уровня

Слайд 73Лекция 6. Обзор программного обеспечения для проектирования архитектуры БД
MySQL Workbench
MS Visio
ErWin
ARIS

Слайд 74Система управления данными (СУБД, DataBase Management System (DBMS)) – Совокупность языковых
средств, обеспечивающих управление БД.
[ГОСТ 34.321-96]
Различают следующие виды СУБД:
- файл-серверные;
- клиент-серверные;
- встраиваемые.
Другими словами, СУБД – это программа, либо комплекс программ, предназначенных для полнофункциональной работы с данными. Как правило, включает в себя инструменты для создания и изменения структуры хранения наборов данных, а также средства доступа к хранимым данным, с возможностью их чтения, добавления, изменения и удаления. При этом, у большинства СУБД имеется собственный встроенный язык (возможно не один) для работы с данными.
Сама база данных (БД) обычно находится просто в файлах закрытого, либо открытого формата.
В соответствии с концептуальным требованием независимости базы данных и приложений, СУБД призвана играть роль посредника между пользователем (точнее его непосредственным запросом или приложением, в котором сформулирован запрос) и базой данных.
) – Совокупность языковых и программных,средств, обеспечивающих управление")
Слайд 75Классификация СУБД
Классификация по степени распределённости
Локальные СУБД (все части локальной СУБД размещаются
Распределённые СУБД (части СУБД могут размещаться на двух и более компьютерах)
Классификация по модели данных
– иерархические;
– сетевые;
– реляционные;
– объектно-ориентированные
Классификация по способу доступа к БД
- файл-серверные;
- клиент-серверные;
- встраиваемые.
Иерархические СУБД
IMS (англ. IBM Information Management System, система управления информацией IBM) — система управления иерархическими базами данных с транзакционными возможностями, выпускается компанией IBM с 1968 года.
Распределённые СУБД")
Слайд 76Файл-серверные
В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается
Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.

Слайд 77Клиент-серверные
Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ
Также к ним относятся: Firebird, Interbase, H2, IBM DB2, Informix, Sybase Adaptive Server Enterprise, Cache, ЛИНТЕР…

Слайд 78Встраиваемые
Встраиваемая СУБД – СУБД, которая может поставляться как составная часть некоторого
Встраиваемые СУБД применяются во многих программах, которые хранят большие массивы данных, но при этом не требуется доступ с многих компьютеров.
Также к ним относятся: OpenEdge, BerkeleyDB, Microsoft SQL Server Compact, ЛИНТЕР…

Слайд 79MySQL Workbench
В-третьих, MySQL Workbench позволяет осуществлять синхронизацию локальной схемы БД с
Как установить MySQL Workbench на Windows?
Во-вторых, программа имеет встроенный редактор SQL-кода, с помощью которого можно быстро внести любые правки в SQL-запросы. При этом возможно строить запросы любой сложности, получать различные выборки из таблиц, связывать их, создавать новые таблицы и редактировать существующие, работать с ключами, полями, связями. Одним словом — полноценный SQL-редактор.
Первое, что стоит отметить — Workbench дает возможность визуально проектировать вашу базу данных, т.е. составлять схему БД. Визуальное представление вашей базы данных всегда дает куда большую информацию, чем сухой список таблиц. В таком варианте вы сразу видите, каким образом связаны между собой таблицы, можете группировать таблицы по каким-либо параметрами и отражать это на схеме. При этом визуальное проектирование удобно не только для того, чтобы кому-то рассказывать о проектируемой БД, но и для личного использования.
http://dev.mysql.com/downloads/workbench/
Создание новой модели данных
Для создания новой модели выбери в меню File->New Model или нажмите на плюсик внизу в списке всех моделей. Появится окно для построения таблиц, представлений, схем, ролей, скриптов и т.д. Несмотря на всю эту автоматизацию, рекомендуется сначала примерно набросать список таблиц на бумаге, опираясь на предметную область, на поставленную задачу и специфику проекта. После этого создать таблицы в Workbench, а затем уже составлять диаграмму.
.
Для создания новой таблицы на вкладке физической схемы (Physical Schemas) выберите «Add Table» и заполняйте поля

Слайд 80MySQL Workbench
Далее переходим на вкладку «Columns» и создаем поля таблицы. Тут
Примечание: При выборе типа данных для поля изначально не указывается нигде поля для задания размерности. Но это не значит, что этого сделать нельзя. Советую указывать длину, не стоит отмечать тип поля просто INT, например. Укажите в скобках его размер (к примеру, INT (11)). Т.е. выбираете типа данных и в скобках уже сами дописываете его размер.
Каждый столбец имеет:
1 имя (не используйте русские буквы в имени!),
2 тип данных. Самые распространенные типы данных:
INT – целое число;
VARCHAR (размер) – символьные данные переменной длины, в скобках указывается максимальный размер;
DECIMAL (размер, десятичные_знаки) – десятичное число;
DATE – дата:
DATETIME – дата и время.
3 PK (primary key) – первичный ключ;
4 NN (not null) – ячейка не допускает пустые значения;
5 UN (unique) – значение должно быть уникальным в пределах столбца;
6 AI (auto incremental) – это свойство полезно для простого первичного ключа, оно означает, что первичный ключ будет заполняться автоматически натуральными числами 1, 2, 3, и т.п.;
7 DEFAULT – значение по умолчанию, т.е., значение, которое при добавлении новой строки в таблицу автоматически вставляется в ячейку сервером, если пользователь оставил ячейку пустой.

Слайд 81MySQL Workbench
После того, как вы создадите несколько таблиц, можно переходить к
Если делаете через вкладку «Foreign Keys», то переходите на эту вкладку, вводите название вашего ключа и выбираете таблицу для связи. Дальше в правой части формы, где указана таблица с полями у нужного поля выбираете поля указанной ранее таблицы, т.е. здесь как раз указывается связь между полями. В случае с расхождением типов у этих полей будет выведено соответствующее сообщение, поэтому накосячить тут точно нельзя. Вот простейший пример ключа:

Слайд 82MySQL Workbench
Создание диаграммы БД
Для создания диаграммы используем меню Model->Add Diagram (Ctrl+T)
Вот и всё рисование. Ничего сложного.
Как вы могли заметить здесь есть панель инструментов, в которой можно выбрать создание новой таблицы, изображения, блоки комментариев, блоки для объединения таблиц и различные варианты связей между таблицами (один к одному, один ко многим и т.п.). Кстати, если будете здесь создавать новую таблицу визуально, то она сразу же добавится и в саму модель, т.е. дублировать ничего не нужно будет.
EER диаграмма (EER = Enhanced Entity Relationship)
Создание SQL CREATE скрипта
Последним этапом моделирования данных, является трансформация разработанной модели в базу данных MySQL. Для этого необходимо создать SQL скрипт. Заходим в меню. Выбираем пункт меню File->Export-> Forward Engineer SQL CREATE Script.
В появившемся окне в поле Output file при помощи кнопки Browse выбираем путь хранения скрипта и задаем его имя. Нажимаем кнопку Next.
В следующем окне нажимаем кнопку Finish .
 либо на вкладке «EER")
Слайд 83MySQL Workbench
Синхронизация с сервером
Это самый вкусный элемент программы, по-моему. Всё, что
И так, выбираете в меню Database->Synchronize Model… и в появившемся окне вводите параметры вашего сервера.
После этого идете дальше, будет проверено подключение и, если все ок, то сможете перейти к выбору модели для синхронизации. Здесь выбираете вашу модель, а внизу выбираете базу данных на вашем сервере. Снова идете дальше, где опять будет проверка все ваших данных.
После этого вы уже попадете на список таблиц в вашей моделе в программе и в БД на сервере. Важно, что данный способ синхронизации полностью синхронизирует данные, т.е. не только загружает на сервер новые таблицы, но и, наоборот, может загрузить таблицы с сервера в программу. Для этого достаточно выбрать таблицы в базе и нажать кнопку «Update Model», чтобы они загрузились в модель при синхронизации. Также какие-то таблицы можно запретить к загрузке. Для наглядности я взял реальную базу данных, при синхронизации четко видно куда грузятся какие таблицы, а какие запрещены для загрузки.

Слайд 84Лекция 7. Язык SQL
SQL (язык структурных запросов – Structured Query Language,
Отличия языка SQL и реляционной теории
Язык SQL оперирует терминами, несколько отличающимися от терминов реляционной теории, например,
вместо "отношений" используются "таблицы",
вместо "кортежей" - "строки",
вместо "атрибутов" - "колонки" или "столбцы".
Стандарт языка SQL, хотя и основан на реляционной теории, но во многих местах отходит он нее.
Компоненты языка SQL
Основу языка SQL составляют операторы, условно разбитые не несколько групп по выполняемым функциям:
DDL (Data Definition Language) - операторы определения объектов базы данных.
DML (Data Manipulation Language) - операторы манипулирования данными.
DCL (Data Control Language) – операторы для работы с правами доступа.
TCL (Transaction Control Language) – операторы управления транзакциями.
История
В начале 1970-х годов в одной из исследовательских лабораторий компании IBM была разработана экспериментальная реляционная СУБД IBM System R, для которой затем был создан специальный язык SEQUEL (Structured English QUEry Language). Позже язык SEQUEL был переименован в SQL.
Первыми СУБД, поддерживающими новый язык, стали в 1979 году Oracle V2 от компании Relational Software Inc. (впоследствии ставшей компанией Oracle) и System/38 от IBM, основанная на System/R.
В 1986 году первый стандарт языка SQL был принят ANSI (American National Standards Institute).
Год спустя Международная организация по стандартизации (International Organization
for Standardization, ISO) опубликовала стандарт ISO 9075-1987 «Database Language SQL»
(Язык баз данных SQL).
Последняя на данный момент редакция: ISO/IEC 9075:2011 «Информационные технологии. Языки базы данных. Язык структурированных запросов (SQL)», либо SQL:2011.
независимость от конкретных СУБД,
переносимость с одной аппаратной среды в другую,
наличие стандартов,
реляционная основа.
Достоинства SQL
 – это")
Слайд 85Операторы SQL
DDL (Data Definition Language) - операторы определения объектов базы данных
CREATE
CREATE TABLE - создать таблицу ALTER TABLE - изменить таблицу DROP TABLE - удалить таблицу
CREATE DOMAIN - создать домен ALTER DOMAIN - изменить домен DROP DOMAIN - удалить домен
CREATE COLLATION - создать последовательность DROP COLLATION - удалить последовательность
CREATE VIEW - создать представление DROP VIEW - удалить представление
DML (Data Manipulation Language) - операторы манипулирования данными
SELECT - отобрать строки из таблиц
INSERT - добавить строки в таблицу
UPDATE - изменить строки в таблице
DELETE - удалить строки в таблице
DCL (Data Control Language) – операторы для работы с правами доступа
CREATE ASSERTION - создать ограничение DROP ASSERTION - удалить ограничение
GRANT - предоставить привилегии пользователю или приложению на манипулирование объектами
REVOKE - отменить привилегии пользователя или приложения
TCL (Transaction Control Language) – операторы управления транзакциями
COMMIT - зафиксировать внесенные изменения
ROLLBACK - откатить внесенные изменения
 - операторы определения объектов базы данныхCREATE SCHEMA - создать схему")
Слайд 86Бонусные операторы для MySQL
SELECT VERSION(), CURRENT_DATE; - команда, запрашивающая у сервера
SELECT NOW(); - команда, запрашивающая у сервера информацию о текущем времени.
SELECT SIN(PI()/4), (4+1)*5; - демонстрируется использование mysql в качестве несложного калькулятора.
SELECT USER() – выводит имя текущего пользователя.
SHOW DATABASES; - показывает, какие базы существуют в настоящее время на сервере.
SHOW TABLES; - показывает, какие таблицы существуют в текущей БД.
USE test – использовать БД с именем test (это специфичная команда - ее необходимо писать в одну строку).
GRANT ALL ON menagerie.* TO your_mysql_name; – предоставить неограниченные права пользователю с именем your_mysql_name для работы с БД menagerie.
DESCRIBE pet; – выводит всю информацию о структуре таблицы pet.
Загрузка данных с помощью текстового файла
Предположим, ваши записи соответствуют приведенным в этой таблице (обратите внимание: MySQL принимает даты в формате ГГГГ-ММ-ДД; возможно, к такой записи вы не привыкли).
Так как вы начинаете работу с пустой таблицей, заполнить ее будет проще всего, если создать текстовый файл, содержащий по строке на каждое из животных, а затем загрузить его содержимое в таблицу одной командой.
Создайте текстовый файл с именем pet.txt, содержащий по одной записи в каждой строке (значения столбцов должны быть разделены символами табуляции и даны в том порядке, который был определен командой CREATE TABLE). Незаполненным полям (например, неизвестный пол или даты смерти живых на сегодняшний день животных), можно присвоить значение NULL. В текстовом файле это значение представляется символами \N. Например, запись для птицы Whistler должна выглядеть примерно так (между значениями должны располагаться одиночные символы табуляции):
Маркер конца строки и символ, разделяющий значения столбцов, можно специально задать в команде LOAD DATA, но по умолчанию используются символы табуляции и перевода строки. Воспринимая их, команда сможет корректно прочитать файл pet.txt.
Загрузить файл pet.txt в таблицу можно с помощью следующей команды:
mysql> LOAD DATA LOCAL INFILE "pet.txt" INTO TABLE pet;
CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20), species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
, CURRENT_DATE; - команда, запрашивающая у сервера информацию об его версии")
Слайд 87CREATE DATABASE
CREATE DATABASE database_name
[ON
{ [PRIMARY] (NAME = logical_file_name,
FILENAME =
[, SIZE = size]
[, MAXSIZE = max_size]
[, FILEGROWTH = growth_increment] )
} [,...n]
]
[LOG ON
{ ( NAME = logical_file_name,
FILENAME = 'os_file_name'
[, SIZE = size] )
} [,...n] ] [FOR RESTORE]
FILENAME - полный путь и имя файла для размещения БД, должен указывать на локальный диск компьютера, на котором установлен SQL Server. SIZE - начальный размер каждого файла в Мб. MAXSIZE - максимальный размер файла в Мб, если не указана размер не ограничивается. FILEGROWTH - единица увеличения файла, указывается в Мб (по умолчанию) или в процентах (т.е. к числу добавляется %), значение 0 запрещает увеличение файла.
CREATE DATABASE SQLStepByStep
ON
PRIMARY (NAME=SQLStepData,
FILENAME='c:\mssql7\data\sqlstep_data.mdf',
SIZE=5,
MAXSIZE=10,
FILEGROWTH=10% )
LOG ON
( NAME=SQLStepLog,
FILENAME='c:\mssql7\data\sqlstep_log.ldf',
SIZE=1, MAXSIZE=5,
FILEGROWTH=1 )

Слайд 88CREATE TABLE
Для создания таблиц применяется оператор CREATE TABLE. Вот как выглядит упрощенный
CREATE TABLE table_name (column_name data_type [NULL | NOT NULL] [,...n])
Например:
CREATE TABLE member ( member_no int NOT NULL, lastname char(50) NOT NULL, firstname char(50) NOT NULL, photo image NULL )
Этим оператором создается таблица member, состоящая из четырех колонок:
member_no - имеет тип int, значения NULL не допускаются;
lastname - имеет тип char(50) - 50 символов, значения NULL не допускаются;
firstname - аналогично lastname;
photo - имеет тип image (изображение), допускается значение NULL.
CREATE TABLE table ( column1 type1 [(size1)][CONSTRAINT _ column-constraint1] [, column2 type2 [(size2)][CONSTRAINT _ column-constraint2] [, ...]] [CONSTRAINT table-constraint1 _ [,table-constraint2 [, ...]]]);
В этом операторе следует указать имя поля, тип данных для него (тип данных должен поддерживаться данной СУБД), длину (для некоторых типов полей) и, если нужно, серверные ограничения (с применением ключевого слова CONSTRAINT).
Например, следующий запрос создает таблицу с именем Simple с четырьмя колонками — LastName, FirstName, EMail и HomePage:
CREATE TABLE Simple (FirstName varchar(50) NOT NULL, LastName varchar(50) NOT NULL, EMail varchar(50), HomePage varchar(255) )
Мы можем расширить эту таблицу добавлением поля PersonID, которое будет использовано как первичный ключ:
CREATE TABLE Simple ( PersonID Integer NOT NULL PRIMARY KEY, FirstName varchar(50) NOT NULL, LastName varchar(50) NOT NULL, EMail varchar(50), HomePage varchar(255) )
и указать, что комбинация полей LastName и FirstName должна быть уникальна:
CREATE TABLE Simple ( PersonID Integer NOT NULL PRIMARY KEY, FirstName varchar(50) NOT NULL, LastName varchar(50) NOT NULL, EMail varchar(50), HomePage varchar(255), CONSTRAINT SimpleConstraint UNIQUE (FirstName, LastName) )
MySQL:
id INTEGER PRIMARY KEY AUTO_INCREMENT
MS SQL server:
id INT identity(1,1) PRIMARY KEY

Слайд 89ALTER TABLE
Для изменения структуры существующей таблицы можно использовать оператор ALTER TABLE.
Первая разновидность этого оператора используется для добавления колонки к таблице, и ее синтаксис имеет вид:
ALTER TABLE table ADD [COLUMN] column datatype [(size)] [CONSTRAINT sinlge-column-constraint]
В запросах такого вида определяется имя таблицы, имя нового поля, его тип данных и, если нужно, размер. Помимо этого можно указать серверное ограничение, связанное с данным полем. Например, для добавления поля Phone к таблице Simple, можно выполнить следующий запрос:
ALTER TABLE Simple ADD Phone varchar(30)
Вторая разновидность оператора ALTER TABLE применяется для добавления серверных ограничений к таблице, а ее синтаксис имеет вид:
ALTER TABLE table ADD CONSTRAINT constraint
Такие запросы позволяют только добавлять индексы, позволяющие использовать соответствующие поля в качестве первичных или внешних ключей.
Третья разновидность предложения ALTER TABLE применяется для удаления поля из таблицы:
ALTER TABLE table DROP [COLUMN] column
Ключевое слово COLUMN использовать не обязательно. Например:
ALTER TABLE Simple DROP Phone
Обратите внимание на то, что для удаления проиндексированных полей следует сначала удалить индекс. Это можно сделать с помощью четвертой разновидности предложения ALTER TABLE:
ALTER TABLE table DROP CONSTRAINT index
Ниже приведен пример такого запроса:
ALTER TABLE Simple DROP CONSTRAINT PrimaryKey

Слайд 90Модификация данных
Оператор UPDATE
Для изменения значений в одной или нескольких колонках таблицы
UPDATE table SET column1 = expression1 [, column2 = expression2] [,…] [WHERE criteria]
Выражение в предложении SET может быть константой или результатом вычислений. Например, для повышения цен всех продуктов, стоящих меньше 10 долл., можно выполнить следующий запрос:
UPDATE Products SET UnitPrice = UnitPrice * 1.1 WHERE UnitPrice < 10
Оператор DELETE
Для удаления строк из таблиц следует использовать оператор DELETE, синтаксис которого имеет вид:
DELETE FROM table [WHERE criteria]
Предложение WHERE не является обязательным, но если вы забудете его включить, из таблицы будут удалены все записи. Например, для удаления из списка всех продуктов, которые больше не поставляются, можно выполнить следующий запрос:
DELETE FROM Products WHERE Discontinued = 1
Оператор INSERT
Для добавления записей в таблицы следует использовать оператор INSERT, синтаксис которого имеет вид:
INSERT [INTO] table ( [column_list] { VALUES ( { DEFAULT | NULL | expression } } [, …] )
Например, для добавления нового клиента в таблицу Customers можно использовать следующий запрос:
INSERT INTO Customers (CustomerID, CompanyName) VALUES (‘XYZFO’, ‘XYZ Deli’)


Слайд 92SELECT
Выбор данных представляет собой наиболее часто встречающуюся операцию, выполняемую с помощью
Оператор SELECT — один из самых важных операторов этого языка, применяемый для выбора данных. Синтаксис этого оператора имеет следующий вид:
SELECT column-list FROM table-list [WHERE where-clause] [ORDER BY order-by-clause]
Операторы SELECT должны содержать слова SELECT и FROM; другие ключевые слова, такие как WHERE или ORDER BY, являются необязательными.
За ключевым словом SELECT следуют сведения о том, какие именно поля необходимо включить в результирующий набор данных. Звездочка (*) обозначает все поля таблицы, например:
SELECT *
Для выбора одной колонки применяется следующий синтаксис:
SELECT CompanyName
Пример выбора нескольких колонок имеет вид:
SELECT CompanyName, ContactName, ContactTitle
Если выбор данных осуществляется из нескольких таблиц и при этом выбираются одноименные поля из разных таблиц, следует ссылаться на имена таблиц для полной идентификации полей, включаемых в результирующий набор данных, например:
SELECT Customers.CompanyName, Shippers.CompanyName
Обратите внимание!
Здесь даны неверные примеры (без FROM).

Слайд 93SELECT
Предложение WHERE
Для фильтрации результатов, возвращаемых оператором SELECT, можно использовать предложение WHERE,
WHERE expression1 [{AND | OR} expression2 […]]
Например, вместо получения полного списка продуктов можно ограничиться только теми из них, у которых значение поля CategoryID равно 4:
SELECT * FROM Products WHERE CategoryID = 4
В предложении WHERE можно использовать различные выражения, например:
SELECT * FROM Products WHERE CategoryID = 2 AND SupplierID > 10
SELECT ProductName, UnitPrice FROM Products WHERE CategoryID = 3 OR UnitPrice < 50
SELECT ProductName, UnitPrice FROM Products WHERE Discontinued IS NOT NULL
Предложение FROM
Для указания имен таблиц, из которых выбираются записи, применяется ключевое слово FROM, например, этот запрос возвратит все поля из таблицы Customers:
SELECT * FROM Customers
Если в результирующем наборе данных нужны только поля CompanyName и ContactName, мы можем ввести следующее предложение SELECT:
SELECT CompanyName, ContactName FROM Customers
Пример запроса к более чем одной таблице приведен ниже:
SELECT Customers.CompanyName, Shippers.CompanyName FROM Customers, Shippers
Операторы сравнения
< Меньше
<= Меньше или равно
<> Не равно
= Равно
> Больше
>= Больше или равно

Слайд 94SELECT
Применение WHERE
Приведем несколько примеров применения этих операторов. Для сопоставления данных с
SELECT CompanyName, ContactName FROM Customers WHERE CompanyName LIKE ‘M%’
В данной маске символ ‘%’ (процент) заменяет любую последовательность символов, а символ ‘_’ (подчеркивание) — один любой символ. Тот же самый результат может быть получен следующим способом:
SELECT CompanyName, ContactName FROM Customers WHERE CompanyName BETWEEN ‘M’ AND ‘N’
В последнем примере мы можем расширить область поиска. В частности, при поиске компаний с именами, начинающимися с букв от A до C, можно выполнить следующий оператор SELECT:
SELECT CompanyName, ContactName FROM Customers WHERE CompanyName BETWEEN ‘A’ AND ‘D’
Используя оператор LIKE, мы можем сузить диапазон поиска, применив более сложную маску для сравнения. Например, чтобы найти компании, содержащие в своем названии подстроку bl (маска ‘%bl%’ показывает, что до и после искомой подстроки может быть любое количество произвольных символов), можно применить следующий запрос:
SELECT CompanyName, ContactName FROM Customers WHERE CompanyName LIKE ‘%bl%’
Используя оператор IN, можно задать список значений, в котором должно содержаться значение поля:
SELECT CompanyName, ContactName FROM Customers WHERE CustomerID IN (‘ALFKI’, ‘BERGS’, ‘VINET’)
Операторы специального сравнения (применяются вместе с WHERE)
ALL Применяется совместно с операторами сравнения при сравнении со списком значений
ANY Применяется совместно с операторами сравнения при сравнении со списком значений
BETWEEN Применяется при проверке нахождения значения внутри заданного интервала (включая его границы)
IN Применяется для проверки наличия значения в списке
LIKE Применяется при проверке соответствия значения заданной маске

Слайд 95SELECT
Применение ORDER BY
Предложение ORDER BY (необязательное) применяется для сортировки результирующего набора
ORDER BY column1 [{ASC | DESC}] [, column2 [{ASC | DESC}] [,…]
Например, для сортировки сотрудников по фамилии и затем по имени следует использовать следующий SQL-запрос:
SELECT LastName, FirstName, Title FROM Employees ORDER BY LastName, FirstName
Для сортировки в убывающем порядке (например, для списока продуктов в порядке убывания цен), используется слово DESC:
SELECT ProductName, UnitPrice FROM Products ORDER BY UnitPrice DESC
Связывание таблиц
Как мы уже убедились, можно создавать запросы, позволяющие извлечь данные из нескольких таблиц. Обратите внимание на то, что без связывания таблиц в результате запроса получится набор данных, содержащий все возможные комбинации строк каждой из исходных таблиц (известное также как декартово произведение):
SELECT ProductName, CategoryName FROM Products, Categories
в то время как запрос, показанный ниже, приводит к отображению списка продуктов с указанием, к какой категории принадлежит данный продукт:
SELECT ProductName, CategoryName FROM Products, Categories WHERE Products.CategoryID = Categories.CategoryID
Применение WHERE + AND, OR, NOT
SELECT CompanyName, ContactName FROM Customers WHERE CompanyName LIKE ‘S%’ AND Country = ‘USA’
Результатом выполнения этого запроса будет список заказчиков, находящихся в США, название которых начинается с буквы S.
SELECT CompanyName, ContactName FROM Customers WHERE Country NOT IN (‘USA’, ‘UK’)
В результате выполнения этого запроса мы получим список заказчиков из всех стран, кроме США и Великобритании.
 применяется для сортировки результирующего набора данных по одной или")
Слайд 96SELECT
Связывание таблиц
В общем случае синтаксис для связывания таблиц имеет вид:
SELECT column-list
Существует несколько типов связывания таблиц. Например, следующий оператор SQL осуществляет так называемое внутреннее соединение таблиц (inner join) — в этом случае в результирующем наборе данных содержатся записи, в которых значения в связанных полях совпадают:
SELECT ProductName, CategoryName FROM Products INNER JOIN Categories ON Products.CategoryID = Categories.CategoryID
Так называемые внешние соединения (outer joins) позволяют нам включить в результат запроса все строки из одной таблицы и соответствующие им строки из другой таблицы. Например:
SELECT ProductName, CategoryName FROM Products LEFT OUTER JOIN Categories ON Products.CategoryID = Categories.CategoryID
Это было так называемое левое внешнее соединение (left outer join). Существуют также правые внешние соединения (right outer join), возвращающие все строки из второй (то есть правой) таблицы и соответствующие им строки из другой таблицы:
SELECT ProductName, CategoryName FROM Products RIGHT OUTER JOIN Categories ON Products.CategoryID = Categories.CategoryID
Комбинируя левое и правое внешние соединения, можно получить полное внешнее соединение, возвращающее все данные из обеих таблиц:
SELECT ProductName, CategoryName FROM Products FULL OUTER JOIN Categories ON Products.CategoryID = Categories.CategoryID
Для получения всех комбинаций строк из обеих таблиц (декартова произведения) можно использовать ключевое слово CROSS JOIN без указания связываемых полей:
SELECT ProductName, CategoryName FROM Products CROSS JOIN Categories
Если в запросе используется более трех таблиц, можно использовать вложенные соединения.
CROSS JOIN эквивалентен «запятой»:
SELECT ProductName, CategoryName FROM Products, Categories
INNER JOIN эквивалентен просто JOIN
LEFT OUTER JOIN эквивалентен LEFT JOIN
RIGHT OUTER JOIN эквивалентен RIGHT JOIN
FULL OUTER JOIN эквивалентен FULL JOIN

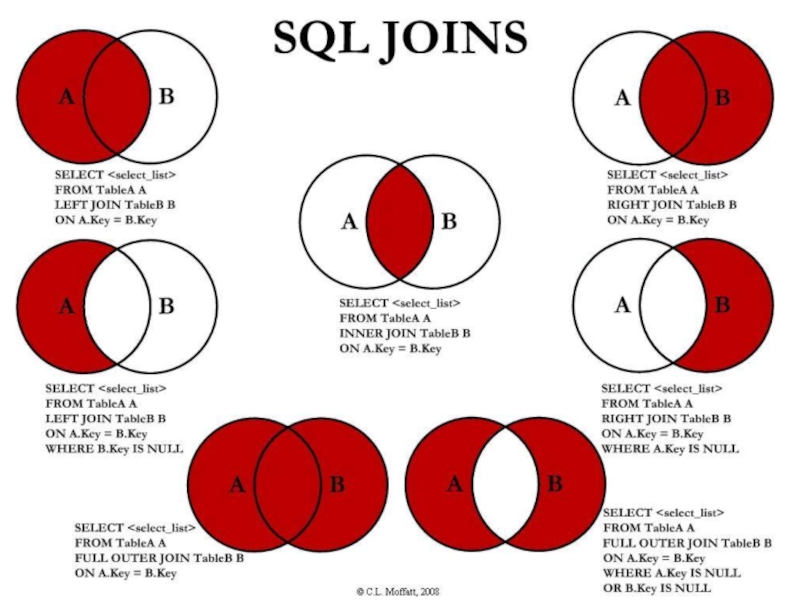
Слайд 98SELECT
Пример запроса объединяющего 3 таблицы
SELECT hst_name, sit_name, vis_timestamp FROM hosts JOIN
Псевдокод запроса объединяющего 3 таблицы
ВЫБРАТЬ (поля) поле_1, поле_2, поле_3 ИЗ (таблицы) таблица_1 СОЕДИНИВ (с таблицей) таблица_2 ПО (условию) (поле_внешнего_ключа_таблицы_1 = поле_первичного_ключа_таблицы_2) СОЕДИНИВ (с таблицей) таблицей_3 ПО (условию) (поле_внешнего_ключа_таблицы_2 = поле_первичного_ключа_таблицы_3);
Естественные соединения (NATURAL JOIN)
Естественным соединением называется соединение между двумя таблицами, в котором СУБД соединяет таблицы по одинаково называющемуся столбцу (столбцам) обеих таблиц (естественным образом!).
Естественное соединение выполняется в том случае, если указано ключевое слово NATURAL.
Аналогично
Единственным совпадающим столбцом
для таблиц emp и dept является столбец depnto.
Нетрудно заменить, что естественные соединения позволяют в значительной степени упростить запросы с соединением за счет устранения псевдонимов таблиц и сравнений для соединения.
SELECT ename, deptno, dname
FROM emp NATURAL JOIN dept;
SELECT ename, emp.deptno, dname
FROM emp JOIN dept
ON emp.deptno = dept.deptno;
Вычисление дат
В MySQL предусмотрено несколько функций для получения частей дат - YEAR(), MONTH(), и DAYOFMONTH().
Определить возраст любого из животных в базе (слайд № 49) можно, если вычислить разницу между текущим годом и годом его рождения, а из результата вычесть единицу, если текущий день находится к началу календаря ближе, нежели день рождения животного. Приведенный ниже запрос выводит дату рождения каждого животного, его возраст и текущую дату.
SELECT name, birth, CURRENT_DATE, (YEAR(CURRENT_DATE)-YEAR(birth)) - (RIGHT(CURRENT_DATE,5)
В этом примере функция YEAR() выделяет из даты год, а RIGHT() - пять крайних справа символов, представляющих календарный день (MM-DD). Часть выражения, сравнивающая даты, выдает 1 или 0, что позволяет уменьшить результат на единицу, если текущий день (CURRENT_DATE) находится к началу календаря ближе, нежели день рождения животного. Все выражение смотрится несколько неуклюже, поэтому вместо него в заголовке соответствующего столбца результатов выводится псевдоним (age - "возраст").

Слайд 99SELECT
Подзапросы
Решим простую задачу, требующую сравнения со значением, возвращаемого из подзапроса.
В этом

Слайд 100SELECT
Предложение GROUP BY
Для вычисления суммарных значений на основе данных одной или
Следующий запрос связывает две таблицы, сортирует их по полю CustomerID, для каждого значения CustomerID создает одну строку в результирующем наборе данных и вычисляет количество значений поля OrderID для каждого значения CustomerID:
SELECT Customers.CustomerID, COUNT (Orders.OrderID) FROM Customers INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID GROUP BY Customers.CustomerID
Наиболее часто используемые агрегатные функции

Слайд 101SELECT
Агрегатные функции
При статистическом анализе баз данных необходимо получать такую информацию, как
наименьшее значение заданного поля записи, усредненное значение поля. Это делается с помощью запросов, содержащих так
называемые агрегатные функции. Агрегатные функции возвращают всего одну запись называемую скалярным значением, в отличие от других запросов, возвращающих наборы записей.
Подсчет строк
Для определения общего числа записей в таблице Products используем следующий запрос:
SELECT count (*) FROM Products;
Для определения количества записей поля ProductName таблицы Products используем следующий запрос:
select count (ProductName) from Products;
Оператор count учитывает записи со значением поля null.
SELECT owner, COUNT(*) FROM pet GROUP BY owner;

Слайд 102SELECT
GROUP BY
Строки имеющие одинаковое значение в столбцах, указанных в списке, будут
Попробуем применить условие GROUP BY, чтобы увидеть, какие вычисления можно выполнять с информацией о ценах контрактов для групп эстрадных артистов.

Слайд 103SELECT
Предложение HAVING
Предложение HAVING имеет назначение, сходное с предложением WHERE, но используется
SELECT Customers.CustomerID, COUNT (Orders.OrderID) FROM Customers INNER JOIN Orders ON Customers.CustomerID = Orders.CustomerID GROUP BY Customers.CustomerID HAVING COUNT(Orders.OrderID) >= 10
Этот запрос аналогичен предыдущему, но в результирующий набор данных включены только заказчики, разместившие десять или более заказов.
Ключевые слова ALL и DISTINCT
До этого момента мы рассматривали, как извлечь все или заданные колонки из одной или нескольких таблиц. Для управления выводом дублирующихся строк результирующего набора данных можно использовать ключевые слова ALL или DISTINCT в предложении SELECT. Ключевое слово DISTINCT указывает, что строки результирующего набора данных должны быть уникальны, тогда как ключевое слово ALL указывает, что возвращать следует все строки. Например, для извлечения названий стран, в которых имеются заказчики, можно использовать следующий запрос:
SELECT DISTINCT Country FROM Customers
Отметим, что ключевое слово ALL используется по определению. Если в запросе требуется вывести более одной колонки и при этом использовано слово DISTINCT, то результирующий набор данных будет содержать различные строки, но некоторые значения одного и того же поля в разных строках могут совпадать.
Ключевое слово TOP
Ключевое слово TOP может быть использовано для возврата первых n строк или первых n процентов таблицы. Например, запрос:
SELECT TOP 10 * FROM PRODUCTS ORDER BY ProductName
возвращает первые 10 продуктов из таблицы, тогда как запрос:
SELECT TOP 25 PERCENT * FROM PRODUCTS ORDER BY ProductName
вернет первую четверть записей таблицы.

Слайд 104SELECT
Преобразование текста
Часто, текстовые значения заполняются пользователями программного обеспечения по-разному: кто пишет
Пример запроса и результат его обработки приведены ниже:
SELECT UCASE(D_STAFF.S_NAME) AS [UCASE(S_NAME)], LCASE(D_STAFF.S_NAME) AS [LCASE(S_NAME)] FROM D_STAFF
string LCASE( str string ) string
string LOWER( str string ) // дополнительно в MySQL
Возвращает строку str, заменив в ней все заглавные буквы на прописные.
string UCASE( str string )
string UPPER( str string ) // дополнительно в MySQL
Возвращает строку str, заменив в ней все прописные буквы на заглавные. Поддерживает многобайтовые символы.(По умолчанию ISO-8859-1 Latin1).
Примеры:
mysql> select LCASE('QUADRATICALLY');
-> 'quadratically‘
mysql> select LOWER('QUADRATICALLY');
-> 'quadratically‘
mysql> select UCASE('Hej');
-> 'HEJ‘
mysql> select UPPER('Hej');
-> 'HEJ'






