Середина 1990-х: скользящее окно
Поздние 1990-е: локальные признаки
Ранние 2000-е: модели частей и формы
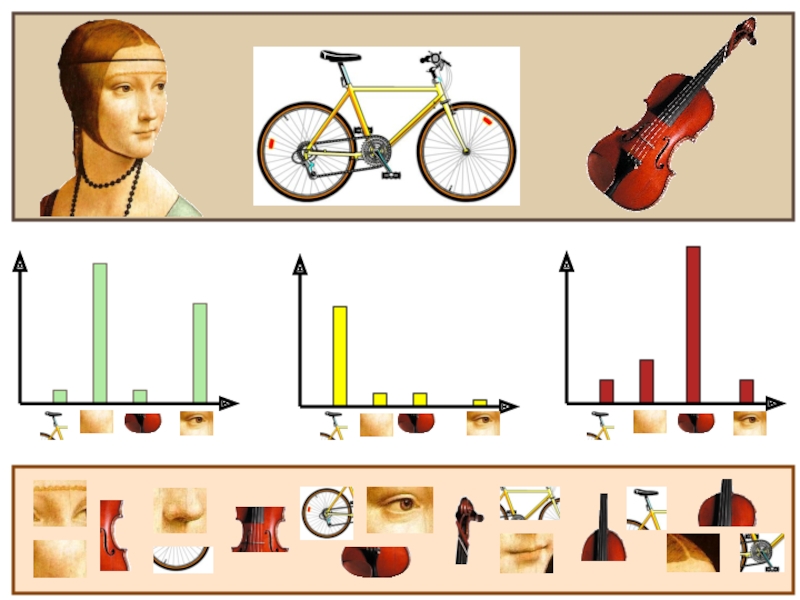
Середина 2000-х: мешки признаков
Наше время: комбинация локальных и глобальных методов, методы, управляемые данными, контекст
Svetlana Lazebnik
Svetlana Lazebnik

http://people.csail.mit.edu/torralba/code/spatialenvelope/
* сутьhttp://people.csail.mit.edu/torralba/code/spatialenvelope/")

Геометрический контекст



Оценка гипотез
Принятие решения

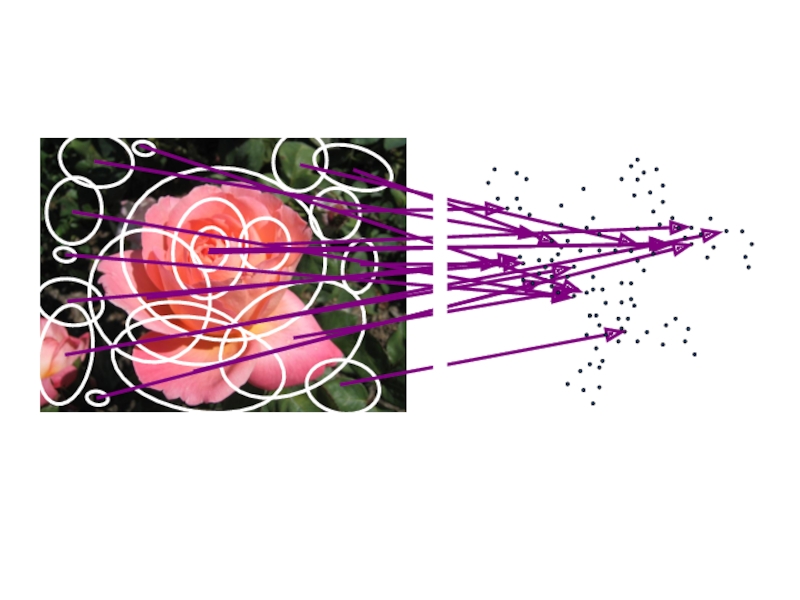
3. Extract and
normalize the
region content
2. Define a region
around each
keypoint
4. Compute a local
descriptor from the
normalized region
5. Match local
descriptors

# Inliers
Affine-variant point locations
Выбор модели объекта
Генерация гипотез
Оценка гипотез
Принятие решения

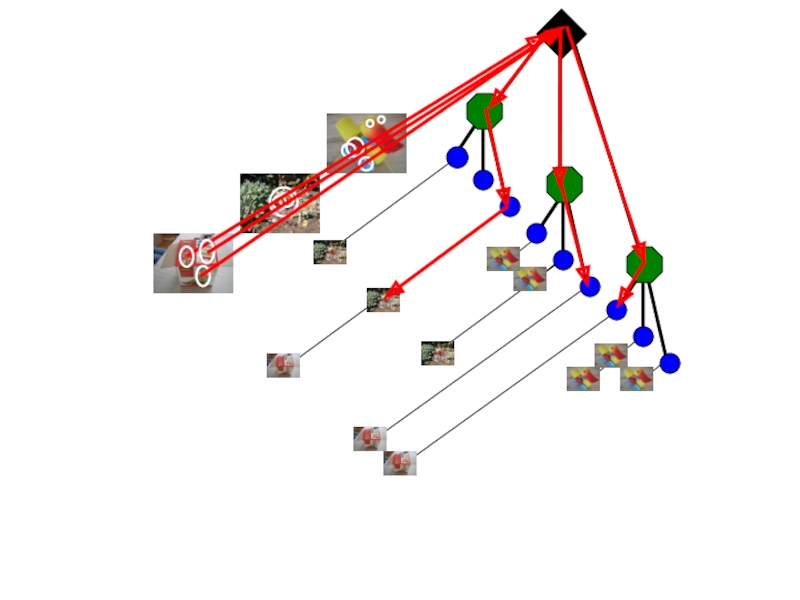
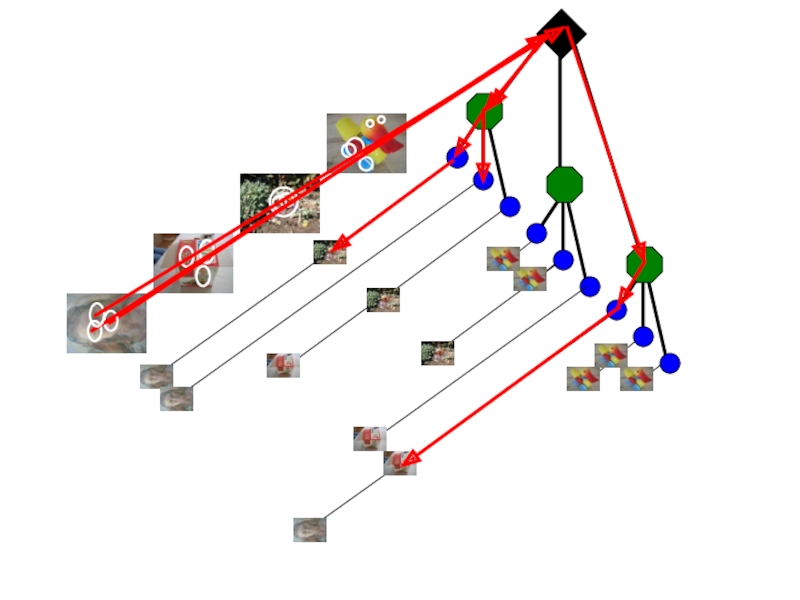
Сопоставить особые точки между входным изображением и базовымСопоставленные точки голосуют за грубое положение/ориентацию/масштаб")
Сохраненным изображением с объектомДан дескриптор x0, найти два")
Scaling/skew
Translation
What is the minimum number of matched points that we need?

SIFTРаспознавание док-станцииОбщение с визуальными карточкамиДругое применениеРаспознавание местаЗамыкание кругов в SLAMK. Grauman, B.")
Kristen Grauman

Область запроса
Найденные кадры
Kristen Grauman


")

[Quack CIVR’08]
Moulin Rouge
Tour Montparnasse
Colosseum
Viktualienmarkt
Maypole
Old Town Square (Prague)

Много похожих
Мало или нет совсем
Но это очень, ОЧЕНЬ МЕДЛЕННО!

Пространство точек дескриптора
Kristen Grauman
Пространство точек")
Пространство признаков
Изображения базы данных
Входной кадр
Easily can have millions of features to search!
Kristen Grauman

Kristen Grauman

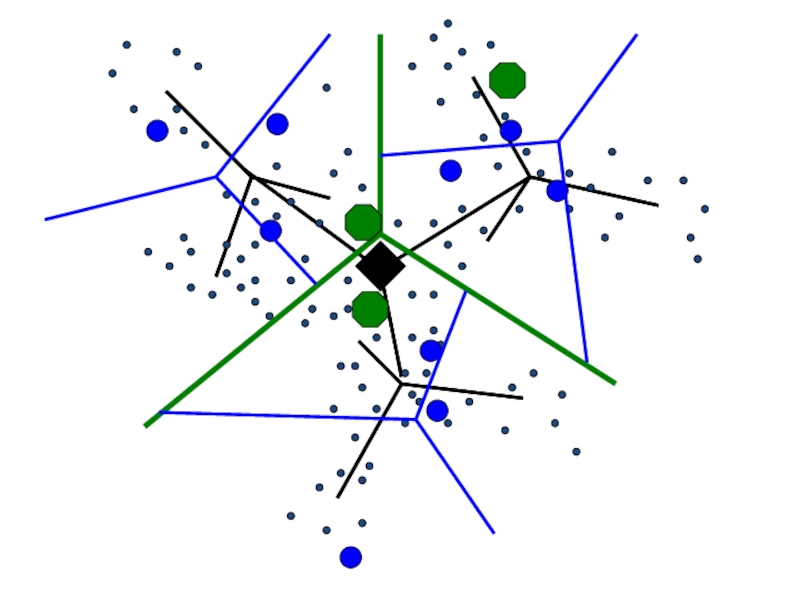
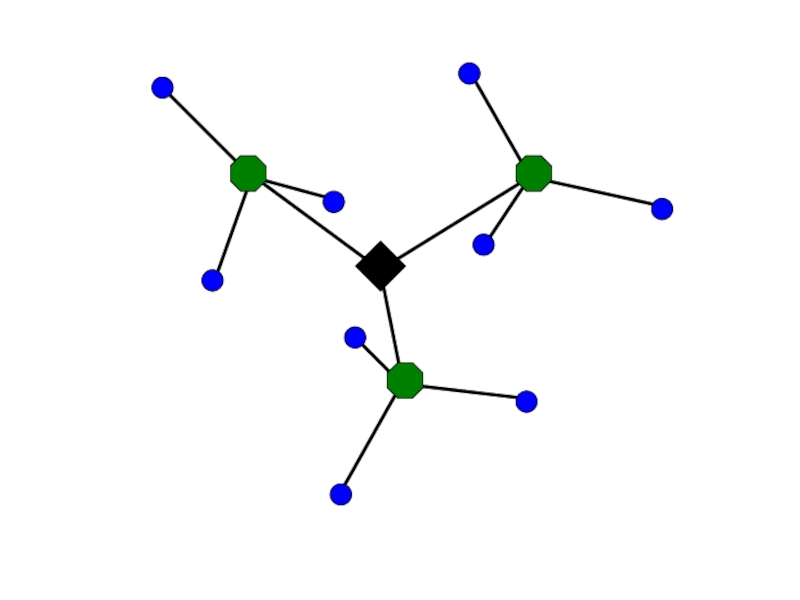
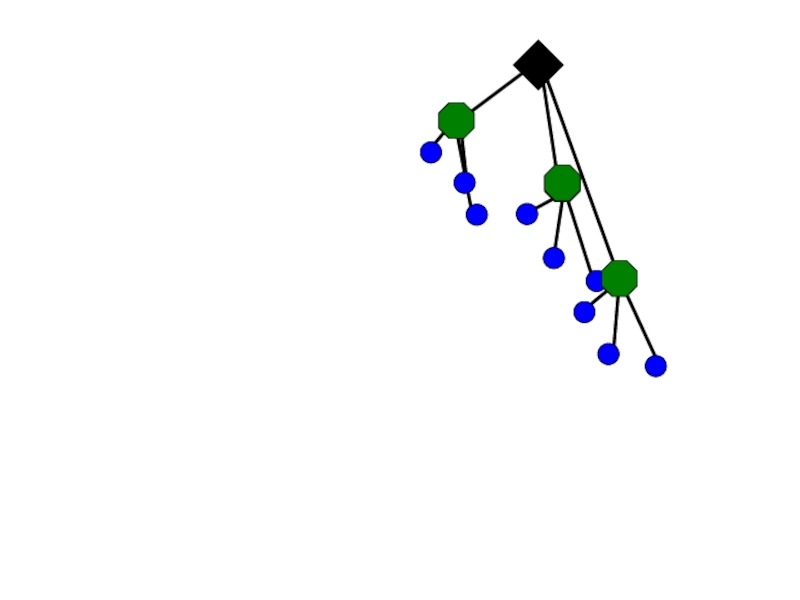
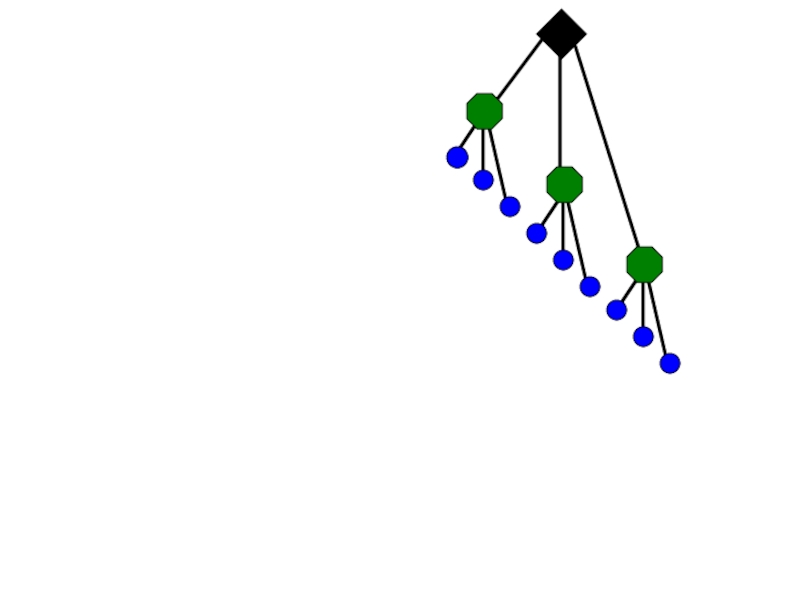
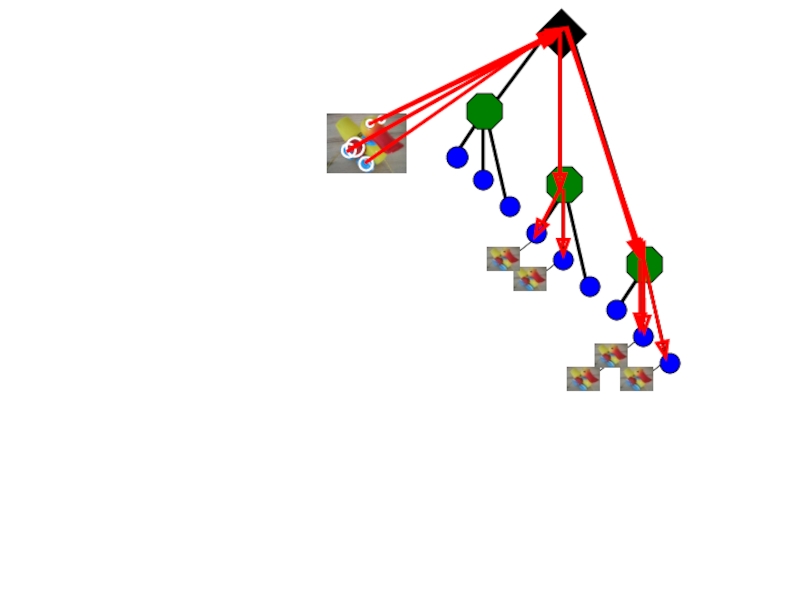
Квантование путем кластеризации – пусть центры кластеров будут прототипами “слов”
Определим, какое слово сопоставить новой области кадра, находя центр ближайшего кластера
Слово #2
Kristen Grauman

Kristen Grauman




Kristen Grauman

ICCV 2005 short course, L. Fei-Fei

 встречающихся словАналогично «мешку слов», часто используемому для документов")
[5 1 1 0]
[1 8 1 4]
для словаря из V слов
Kristen Grauman
 – метод")
Kristen Grauman

Kristen Grauman


К-т ветвления
Kristen Grauman

Плотно, равномерно
Разреженно, в особых точках
Случайно
Множественные операторы
Для поиска конкретных текстурированных объектов надежнее работают разреженные выборки.
Много дополняющих друг друга детекторов дают лучшее покрытие изображения.
Для категоризации объектов лучшее покрытие даёт плотная выборка.
[See Nowak, Jurie & Triggs, ECCV 2006]

Kristen Grauman

a
f
e
e
h
h
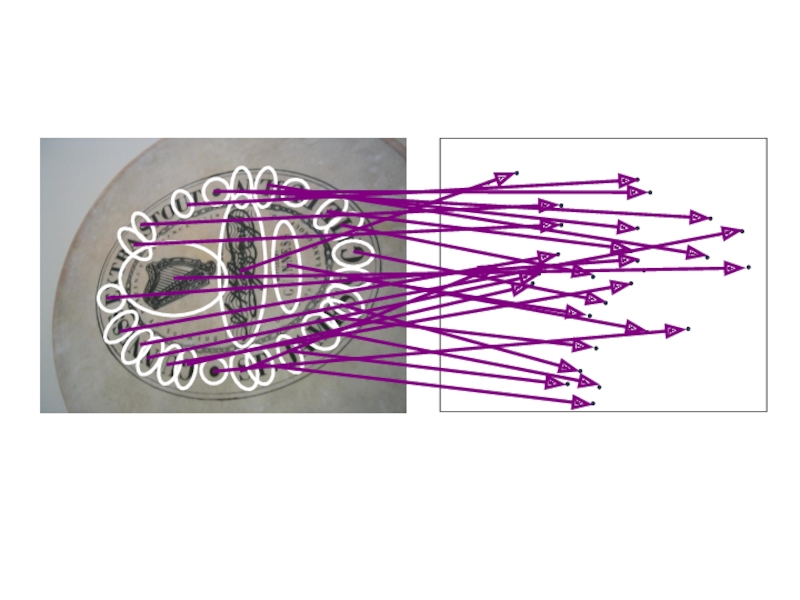
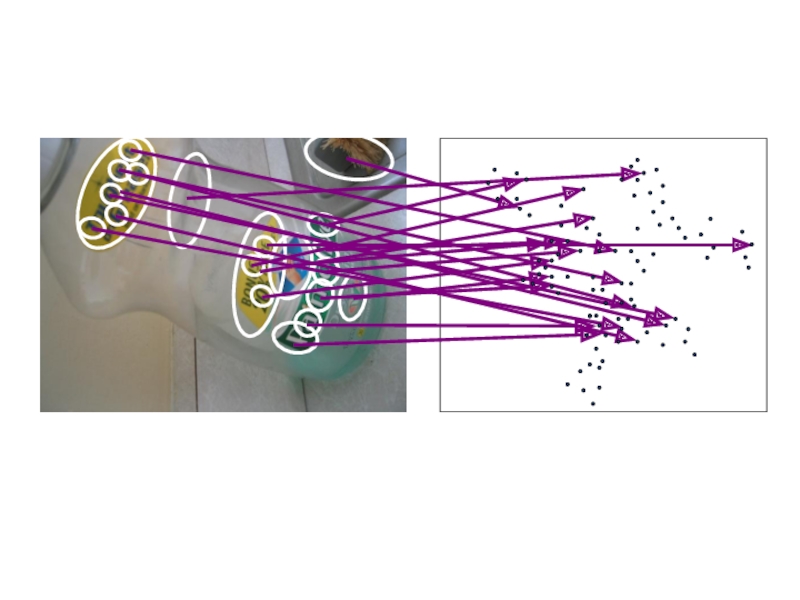
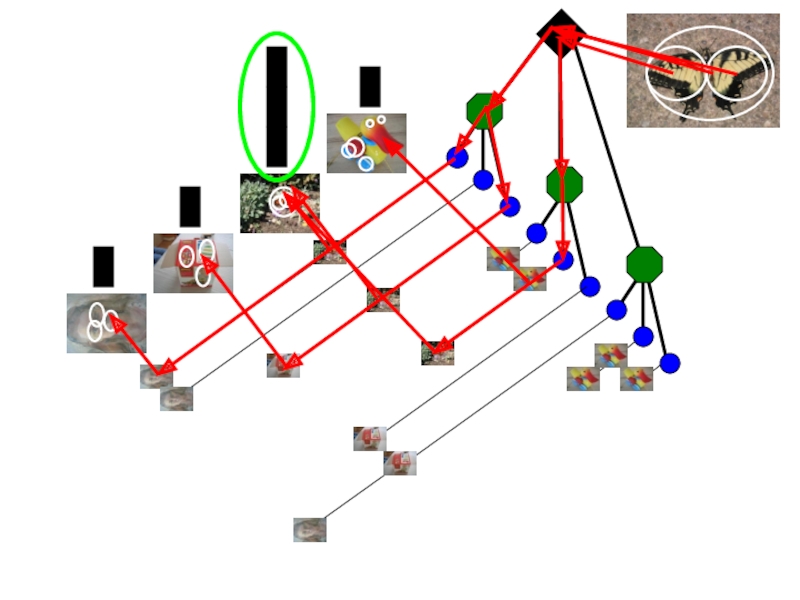
Какое сопоставление лучше?

Настоящие объекты имеют консистентную геометрию

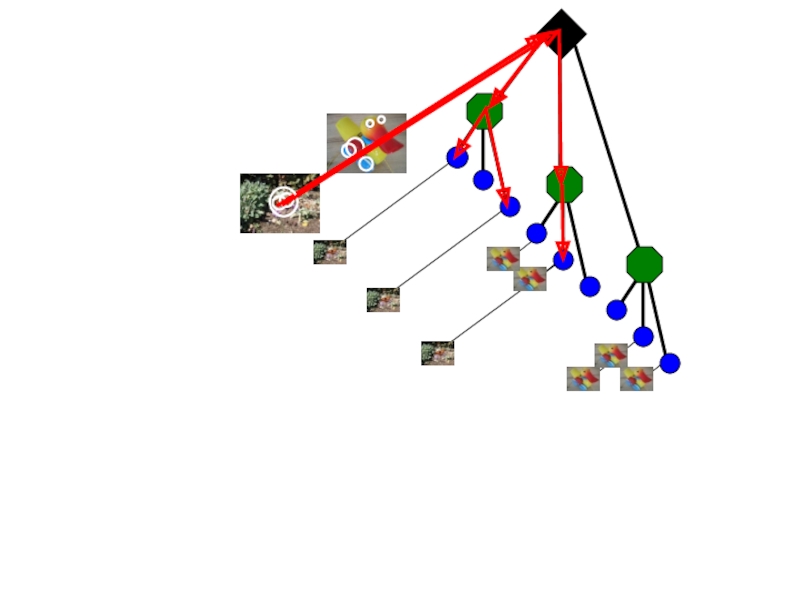
Запрос
Запрос
Кадр с высокой BoW - похожестью
Кадр с высокой BoW - похожестью

Кадр с высокой BoW - похожестью

Kristen Grauman

Slide credit: Ondrej Chum
: 5 кадровResults (ordered):precision = #relevant / #returnedrecall =")
Число документов в базе данных
Число документов, в которых встречается слово i
Количество слова i в документе d
Число слов в документе d
Kristen Grauman

Нерелевантные результаты могут привести к `смещению темы’:
Volkswagen Golf, 1999, Green, 2000cc, petrol, manual, , hatchback, 94000miles, 2.0 GTi, 2 Registered Keepers, HPI Checked, Air-Conditioning, Front and Rear Parking Sensors, ABS, Alarm, Alloy
Slide credit: Ondrej Chum

Slide credit: Ondrej Chum


Если не удалось найти и скачать презентацию, Вы можете заказать его на нашем сайте. Мы постараемся найти нужный Вам материал и отправим по электронной почте. Не стесняйтесь обращаться к нам, если у вас возникли вопросы или пожелания:
Email: Нажмите что бы посмотреть
Это сайт презентаций, докладов, проектов, шаблонов в формате PowerPoint. Мы помогаем школьникам, студентам, учителям, преподавателям хранить и обмениваться учебными материалами с другими пользователями.





")











")






