Рассмотрим пример.
Пусть необходимо построить базу
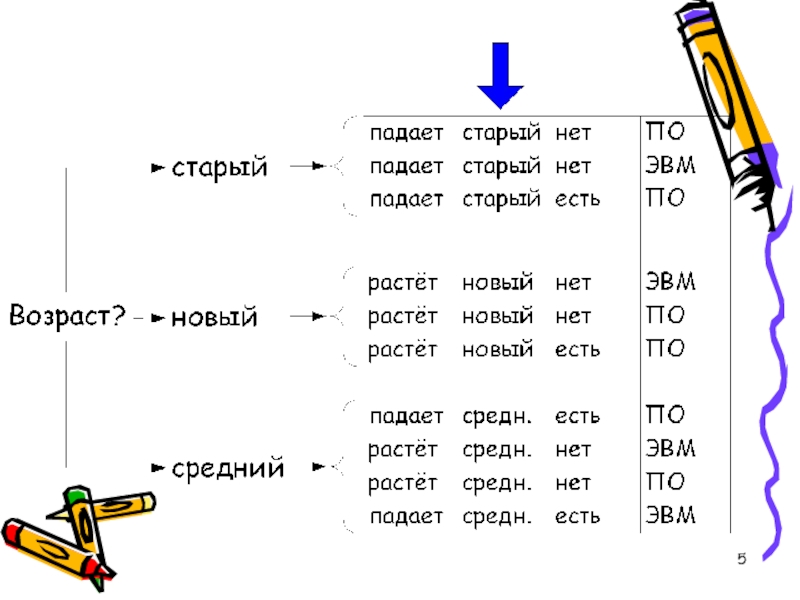
знаний для получения ответа: «Как поступить, чтобы при-быль росла?».
знаний для получения ответа: «Как поступить, чтобы при-быль росла?».





Теперь алгоритм не зависит от порядка следования атрибутов таблицы данных.

(столбцов таблицы)
")
;C1 , C2")
Пусть freq(Cj,T ) — количество примеров из множества T, в которых атрибут класса равен Cj

Например, вероятность того, что прибыль будет расти, составляет P = 5 / 10 = 0,5

 = -")

2.2. В противном случае рекурсивно применяем алгоритм C4.5 к полученной подтаблице

Info(T) = -(0,5·log2(0.5) +
+ 0,5·log2(0.5)) = -(-0,5-0,5) = 1

Gain(ВОЗРАСТ) = 1 – 0,4 = 0,6.
 = -(3/3 · log2(3/3)) = 0.Info(T2) = -(3/3 ·")
Gain(КОНКУРЕНЦИЯ) = 1 – 1,354 =
= -0,354.
 = -(1/4 · log2(1/4) + 3/4 · log2(3/4))= =")
Gain(ТИП) = 1 – 1 = 0.
 = -(2/4 · log2(2/4) + 2/4 · log2(2/4))= =")
Если не удалось найти и скачать презентацию, Вы можете заказать его на нашем сайте. Мы постараемся найти нужный Вам материал и отправим по электронной почте. Не стесняйтесь обращаться к нам, если у вас возникли вопросы или пожелания:
Email: Нажмите что бы посмотреть
Это сайт презентаций, докладов, проектов, шаблонов в формате PowerPoint. Мы помогаем школьникам, студентам, учителям, преподавателям хранить и обмениваться учебными материалами с другими пользователями.

")