- Главная
- Разное
- Дизайн
- Бизнес и предпринимательство
- Аналитика
- Образование
- Развлечения
- Красота и здоровье
- Финансы
- Государство
- Путешествия
- Спорт
- Недвижимость
- Армия
- Графика
- Культурология
- Еда и кулинария
- Лингвистика
- Английский язык
- Астрономия
- Алгебра
- Биология
- География
- Детские презентации
- Информатика
- История
- Литература
- Маркетинг
- Математика
- Медицина
- Менеджмент
- Музыка
- МХК
- Немецкий язык
- ОБЖ
- Обществознание
- Окружающий мир
- Педагогика
- Русский язык
- Технология
- Физика
- Философия
- Химия
- Шаблоны, картинки для презентаций
- Экология
- Экономика
- Юриспруденция
Machine translation презентация
Содержание
- 1. Machine translation
- 2. Machine translation Machine translation, sometimes referred to
- 4. History The idea of machine translation may
- 5. MT on the web started with SYSTRAN
- 6. René Descartes
- 7. Translation process The human translation process may be described
- 9. Approaches Machine translation can use a method
- 10. Approaches Rule-based Transfer-based machine translation Interlingual Dictionary-based Statistical Example-based Hybrid MT Neural MT
- 11. Applications While no system provides the
- 12. With the recent focus on terrorism, the
- 13. Evaluation There are many factors that
- 14. Relying exclusively on unedited machine translation ignores
- 15. Using machine translation as a teaching tool
- 16. Machine translation and signed languages In the
Слайд 1MACHINE TRANSLATION
Almaty KAZAKH-TURKISH humanitarian and technical COLLEGE
3 course
Translating
Kasenova Arailym

Слайд 2Machine translation
Machine translation, sometimes referred to by the abbreviation MT is a sub-field
of computational linguistics that investigates the use of software to translate text or speech from one language to another.
On a basic level, MT performs simple substitution of words in one language for words in another, but that alone usually cannot produce a good translation of a text because recognition of whole phrases and their closest counterparts in the target language is needed. Solving this problem with corpus statistical, and neural techniques is a rapidly growing field that is leading to better translations, handling differences in linguistic typology, translation of idioms, and the isolation of anomalies.
Current machine translation software often allows for customization by domain or profession (such as weather reports), improving output by limiting the scope of allowable substitutions. This technique is particularly effective in domains where formal or formulaic language is used. It follows that machine translation of government and legal documents more readily produces usable output than conversation or less standardised text.
Improved output quality can also be achieved by human intervention: for example, some systems are able to translate more accurately if the user has unambiguously identified which words in the text are proper names. With the assistance of these techniques, MT has proven useful as a tool to assist human translators and, in a very limited number of cases, can even produce output that can be used as is (e.g., weather reports).
The progress and potential of machine translation have been debated much through its history. Since the 1950s, a number of scholars have questioned the possibility of achieving fully automatic machine translation of high quality. Some critics claim that there are in-principle obstacles to automating the translation process.
On a basic level, MT performs simple substitution of words in one language for words in another, but that alone usually cannot produce a good translation of a text because recognition of whole phrases and their closest counterparts in the target language is needed. Solving this problem with corpus statistical, and neural techniques is a rapidly growing field that is leading to better translations, handling differences in linguistic typology, translation of idioms, and the isolation of anomalies.
Current machine translation software often allows for customization by domain or profession (such as weather reports), improving output by limiting the scope of allowable substitutions. This technique is particularly effective in domains where formal or formulaic language is used. It follows that machine translation of government and legal documents more readily produces usable output than conversation or less standardised text.
Improved output quality can also be achieved by human intervention: for example, some systems are able to translate more accurately if the user has unambiguously identified which words in the text are proper names. With the assistance of these techniques, MT has proven useful as a tool to assist human translators and, in a very limited number of cases, can even produce output that can be used as is (e.g., weather reports).
The progress and potential of machine translation have been debated much through its history. Since the 1950s, a number of scholars have questioned the possibility of achieving fully automatic machine translation of high quality. Some critics claim that there are in-principle obstacles to automating the translation process.


Слайд 4History
The idea of machine translation may be traced back to the
17th century. In 1629, René Descartes proposed a universal language, with equivalent ideas in different tongues sharing one symbol. The field of "machine translation" appeared in Warren Weaver's Memorandum on Translation (1949). The first researcher in the field, Yehosha Bar-Hillel, began his research at MIT (1951). A Georgetown University MT research team followed (1951) with a public demonstration of its Georgetown-IBM experiment system in 1954. MT research programs popped up in Japan[and Russia (1955), and the first MT conference was held in London (1956). Researchers continued to join the field as the Association for Machine Translation and Computational Linguistics was formed in the U.S. (1962) and the National Academy of Sciences formed the Automatic Language Processing Advisory Committee (ALPAC) to study MT (1964). Real progress was much slower, however, and after the ALPAC report (1966), which found that the ten-year-long research had failed to fulfill expectations, funding was greatly reduced. According to a 1972 report by the Director of Defense Research and Engineering (DDR&E), the feasibility of large-scale MT was reestablished by the success of the Logos MT system in translating military manuals into Vietnamese during that conflict.
The French Textile Institute also used MT to translate abstracts from and into French, English, German and Spanish (1970); Brigham Young University started a project to translate Mormon texts by automated translation (1971); and Xerox used SYSTRAN to translate technical manuals (1978). Beginning in the late 1980s, as computational power increased and became less expensive, more interest was shown in statistical models for machine translation. Various MT companies were launched, including Trados (1984), which was the first to develop and market translation memory technology (1989). The first commercial MT system for Russian / English / German-Ukrainian was developed at Kharkov State University (1991).
The French Textile Institute also used MT to translate abstracts from and into French, English, German and Spanish (1970); Brigham Young University started a project to translate Mormon texts by automated translation (1971); and Xerox used SYSTRAN to translate technical manuals (1978). Beginning in the late 1980s, as computational power increased and became less expensive, more interest was shown in statistical models for machine translation. Various MT companies were launched, including Trados (1984), which was the first to develop and market translation memory technology (1989). The first commercial MT system for Russian / English / German-Ukrainian was developed at Kharkov State University (1991).

Слайд 5MT on the web started with SYSTRAN Offering free translation of
small texts (1996), followed by AltaVista Babelfish, which racked up 500,000 requests a day (1997). Franz-Josef Och (the future head of Translation Development AT Google) won DARPA's speed MT competition (2003). More innovations during this time included MOSES, the open-source statistical MT engine (2007), a text/SMS translation service for mobiles in Japan (2008), and a mobile phone with built-in speech-to-speech translation functionality for English, Japanese and Chinese (2009). Recently, Google announced that Google Translate translates roughly enough text to fill 1 million books in one day (2012).
The idea of using digital computers for translation of natural languages was proposed as early as 1946 by A. D. Booth and possibly others. Warren Weaver wrote an important memorandum "Translation" in 1949. The Georgetown experiment was by no means the first such application, and a demonstration was made in 1954 on the APEXC machine at Birkbeck College (University of London) of a rudimentary translation of English into French. Several papers on the topic were published at the time, and even articles in popular journals (see for example Wireless World, Sept. 1955, Cleave and Zacharov). A similar application, also pioneered at Birkbeck College at the time, was reading and composing Braille texts by computer.
The idea of using digital computers for translation of natural languages was proposed as early as 1946 by A. D. Booth and possibly others. Warren Weaver wrote an important memorandum "Translation" in 1949. The Georgetown experiment was by no means the first such application, and a demonstration was made in 1954 on the APEXC machine at Birkbeck College (University of London) of a rudimentary translation of English into French. Several papers on the topic were published at the time, and even articles in popular journals (see for example Wireless World, Sept. 1955, Cleave and Zacharov). A similar application, also pioneered at Birkbeck College at the time, was reading and composing Braille texts by computer.
, followed")

Слайд 7Translation process
The human translation process may be described as:
1)Decoding the meaning of the source text; and
2)Re-encoding this meaning in the
target language.
Behind this ostensibly simple procedure lies a complex cognitive operation. To decode the meaning of the source text in its entirety, the translator must interpret and analyse all the features of the text, a process that requires in-depth knowledge of the grammar, semantics, syntax, idioms, etc., of the source language, as well as the culture of its speakers. The translator needs the same in-depth knowledge to re-encode the meaning in the target language.
Therein lies the challenge in machine translation: how to program a computer that will "understand" a text as a person does, and that will "create" a new text in the target language that "sounds" as if it has been written by a person.
In its most general application, this is beyond current technology. Though it works much faster, no automated translation program or procedure, with no human participation, can produce output even close to the quality a human translator can produce. What it can do, however, is provide a general, though imperfect, approximation of the original text, getting the "gist" of it (a process called "gisting"). This is sufficient for many purposes, including making best use of the finite and expensive time of a human translator, reserved for those cases in which total accuracy is indispensable.
This problem may be approached in a number of ways, through the evolution of which accuracy has improved.
Behind this ostensibly simple procedure lies a complex cognitive operation. To decode the meaning of the source text in its entirety, the translator must interpret and analyse all the features of the text, a process that requires in-depth knowledge of the grammar, semantics, syntax, idioms, etc., of the source language, as well as the culture of its speakers. The translator needs the same in-depth knowledge to re-encode the meaning in the target language.
Therein lies the challenge in machine translation: how to program a computer that will "understand" a text as a person does, and that will "create" a new text in the target language that "sounds" as if it has been written by a person.
In its most general application, this is beyond current technology. Though it works much faster, no automated translation program or procedure, with no human participation, can produce output even close to the quality a human translator can produce. What it can do, however, is provide a general, though imperfect, approximation of the original text, getting the "gist" of it (a process called "gisting"). This is sufficient for many purposes, including making best use of the finite and expensive time of a human translator, reserved for those cases in which total accuracy is indispensable.
This problem may be approached in a number of ways, through the evolution of which accuracy has improved.
Decoding the meaning of the source text; and2)Re-encoding this meaning in the target language.Behind this ostensibly")
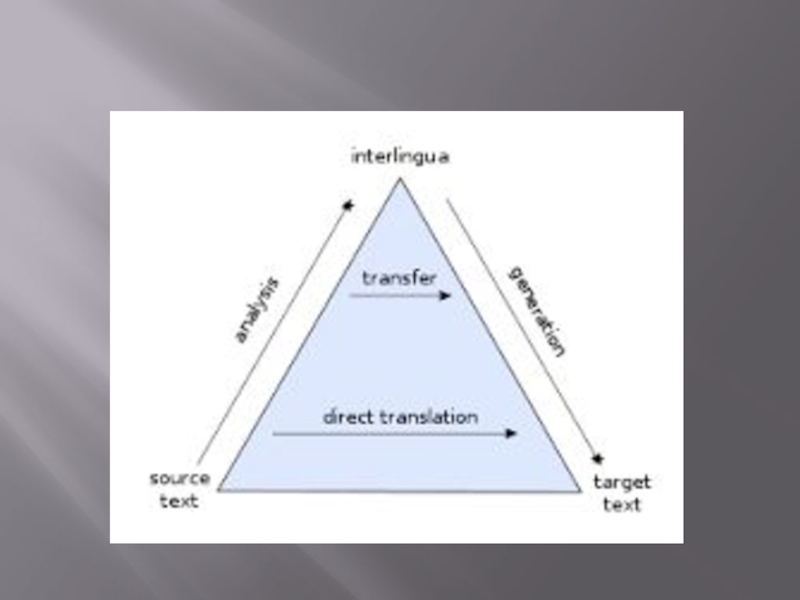
Слайд 9Approaches
Machine translation can use a method based on linguistic rules, which means
that words will be translated in a linguistic way – the most suitable (orally speaking) words of the target language will replace the ones in the source language.
It is often argued that the success of machine translation requires the problem of natural language understanding to be solved first.
Generally, rule-based methods parse a text, usually creating an intermediary, symbolic representation, from which the text in the target language is generated. According to the nature of the intermediary representation, an approach is described as interlingual machine translation or transfer-based machine translation. These methods require extensive lexicons with morphological, syntactic, and semantic information, and large sets of rules.
Given enough data, machine translation programs often work well enough for a native speaker of one language to get the approximate meaning of what is written by the other native speaker. The difficulty is getting enough data of the right kind to support the particular method. For example, the large multilingual corpus of data needed for statistical methods to work is not necessary for the grammar-based methods. But then, the grammar methods need a skilled linguist to carefully design the grammar that they use.
To translate between closely related languages, the technique referred to as rule-based machine translation may be used.
It is often argued that the success of machine translation requires the problem of natural language understanding to be solved first.
Generally, rule-based methods parse a text, usually creating an intermediary, symbolic representation, from which the text in the target language is generated. According to the nature of the intermediary representation, an approach is described as interlingual machine translation or transfer-based machine translation. These methods require extensive lexicons with morphological, syntactic, and semantic information, and large sets of rules.
Given enough data, machine translation programs often work well enough for a native speaker of one language to get the approximate meaning of what is written by the other native speaker. The difficulty is getting enough data of the right kind to support the particular method. For example, the large multilingual corpus of data needed for statistical methods to work is not necessary for the grammar-based methods. But then, the grammar methods need a skilled linguist to carefully design the grammar that they use.
To translate between closely related languages, the technique referred to as rule-based machine translation may be used.

Слайд 10Approaches
Rule-based
Transfer-based machine translation
Interlingual
Dictionary-based
Statistical
Example-based
Hybrid MT
Neural MT

Слайд 11Applications
While no system provides the holy grail of fully automatic high-quality
machine translation of unrestricted text, many fully automated systems produce reasonable output. The quality of machine translation is substantially improved if the domain is restricted and controlled.
Despite their inherent limitations, MT programs are used around the world. Probably the largest institutional user is the European Commission. The MOLTO project, for example, coordinated by the University of Gothenburg, received more than 2.375 million euros project support from the EU to create a reliable translation tool that covers a majority of the EU languages. The further development of MT systems comes at a time when budget cuts in human translation may increase the EU's dependency on reliable MT programs. The European Commission contributed 3.072 million euros (via its ISA programme) for the creation of MT@EC, a statistical machine translation program tailored to the administrative needs of the EU, to replace a previous rule-based machine translation system.
Google has claimed that promising results were obtained using a proprietary statistical machine translation engine. The statistical translation engine used in the Google language tools for Arabic <-> English and Chinese <-> English had an overall score of 0.4281 over the runner-up IBM's BLEU-4 score of 0.3954 (Summer 2006) in tests conducted by the National Institute for Standards and Technology.
Despite their inherent limitations, MT programs are used around the world. Probably the largest institutional user is the European Commission. The MOLTO project, for example, coordinated by the University of Gothenburg, received more than 2.375 million euros project support from the EU to create a reliable translation tool that covers a majority of the EU languages. The further development of MT systems comes at a time when budget cuts in human translation may increase the EU's dependency on reliable MT programs. The European Commission contributed 3.072 million euros (via its ISA programme) for the creation of MT@EC, a statistical machine translation program tailored to the administrative needs of the EU, to replace a previous rule-based machine translation system.
Google has claimed that promising results were obtained using a proprietary statistical machine translation engine. The statistical translation engine used in the Google language tools for Arabic <-> English and Chinese <-> English had an overall score of 0.4281 over the runner-up IBM's BLEU-4 score of 0.3954 (Summer 2006) in tests conducted by the National Institute for Standards and Technology.

Слайд 12With the recent focus on terrorism, the military sources in the
United States have been investing significant amounts of money in natural language engineering. In-Q-Tel (a venture capital fund, largely funded by the US Intelligence Community, to stimulate new technologies through private sector entrepreneurs) brought up companies like Language Weaver. Currently the military community is interested in translation and processing of languages like Arabic, Pashto, and Dari.[citation needed] Within these languages, the focus is on key phrases and quick communication between military members and civilians through the use of mobile phone apps. The Information Processing Technology Office in DARPA hosts programs like TIDES and Babylon translator. US Air Force has awarded a $1 million contract to develop a language translation technology.
The notable rise of social networking on the web in recent years has created yet another niche for the application of machine translation software – in utilities such as Facebook, or instant messaging clients such as Skype, GoogleTalk, MSN Messenger, etc. – allowing users speaking different languages to communicate with each other. Machine translation applications have also been released for most mobile devices, including mobile telephones, pocket PCs, PDAs, etc. Due to their portability, such instruments have come to be designated as mobile translation tools enabling mobile business networking between partners speaking different languages, or facilitating both foreign language learning and unaccompanied traveling to foreign countries without the need of the intermediation of a human translator.
Despite being labelled as an unworthy competitor to human translation in 1966 by the Automated Language Processing Advisory Committee put together by the United States government,the quality of machine translation has now been improved to such levels that its application in online collaboration and in the medical field are being investigated. In the Ishida and Matsubara lab of Kyoto University, methods of improving the accuracy of machine translation as a support tool for inter-cultural collaboration in today's globalized society are being studied.The application of this technology in medical settings where human translators are absent is another topic of research however difficulties arise due to the importance of accurate translations in medical diagnoses.
The notable rise of social networking on the web in recent years has created yet another niche for the application of machine translation software – in utilities such as Facebook, or instant messaging clients such as Skype, GoogleTalk, MSN Messenger, etc. – allowing users speaking different languages to communicate with each other. Machine translation applications have also been released for most mobile devices, including mobile telephones, pocket PCs, PDAs, etc. Due to their portability, such instruments have come to be designated as mobile translation tools enabling mobile business networking between partners speaking different languages, or facilitating both foreign language learning and unaccompanied traveling to foreign countries without the need of the intermediation of a human translator.
Despite being labelled as an unworthy competitor to human translation in 1966 by the Automated Language Processing Advisory Committee put together by the United States government,the quality of machine translation has now been improved to such levels that its application in online collaboration and in the medical field are being investigated. In the Ishida and Matsubara lab of Kyoto University, methods of improving the accuracy of machine translation as a support tool for inter-cultural collaboration in today's globalized society are being studied.The application of this technology in medical settings where human translators are absent is another topic of research however difficulties arise due to the importance of accurate translations in medical diagnoses.

Слайд 13Evaluation
There are many factors that affect how machine translation systems are
evaluated. These factors include the intended use of the translation, the nature of the machine translation software, and the nature of the translation process.
Different programs may work well for different purposes. For example, statistical machine translation (SMT) typically outperforms example-based machine translation (EBMT), but researchers found that when evaluating English to French translation, EBMT performs better.[48] The same concept applies for technical documents, which can be more easily translated by SMT because of their formal language.
In certain applications, however, e.g., product descriptions written in a controlled language, a dictionary-based machine-translation system has produced satisfactory translations that require no human intervention save for quality inspection.[49]
There are various means for evaluating the output quality of machine translation systems. The oldest is the use of human judges[50] to assess a translation's quality. Even though human evaluation is time-consuming, it is still the most reliable method to compare different systems such as rule-based and statistical systems.[51] Automated means of evaluation include BLEU, NIST, METEOR, and LEPOR.[52]
Different programs may work well for different purposes. For example, statistical machine translation (SMT) typically outperforms example-based machine translation (EBMT), but researchers found that when evaluating English to French translation, EBMT performs better.[48] The same concept applies for technical documents, which can be more easily translated by SMT because of their formal language.
In certain applications, however, e.g., product descriptions written in a controlled language, a dictionary-based machine-translation system has produced satisfactory translations that require no human intervention save for quality inspection.[49]
There are various means for evaluating the output quality of machine translation systems. The oldest is the use of human judges[50] to assess a translation's quality. Even though human evaluation is time-consuming, it is still the most reliable method to compare different systems such as rule-based and statistical systems.[51] Automated means of evaluation include BLEU, NIST, METEOR, and LEPOR.[52]

Слайд 14Relying exclusively on unedited machine translation ignores the fact that communication
in human language is context-embedded and that it takes a person to comprehend the context of the original text with a reasonable degree of probability. It is certainly true that even purely human-generated translations are prone to error. Therefore, to ensure that a machine-generated translation will be useful to a human being and that publishable-quality translation is achieved, such translations must be reviewed and edited by a human.[53] The late Claude Piron wrote that machine translation, at its best, automates the easier part of a translator's job; the harder and more time-consuming part usually involves doing extensive research to resolve ambiguities in the source text, which the grammatical and lexical exigencies of the target language require to be resolved. Such research is a necessary prelude to the pre-editing necessary in order to provide input for machine-translation software such that the output will not be meaningless.[54]
In addition to disambiguation problems, decreased accuracy can occur due to varying levels of training data for machine translating programs. Both example-based and statistical machine translation rely on a vast array of real example sentences as a base for translation, and when too many or too few sentences are analyzed accuracy is jeopardized. Researchers found that when a program is trained on 203,529 sentence pairings, accuracy actually decreases.[48] The optimal level of training data seems to be just over 100,000 sentences, possibly because as training data increasing, the number of possible sentences increases, making it harder to find an exact translation match.
Using machine translation as a teaching tool[edit]
In addition to disambiguation problems, decreased accuracy can occur due to varying levels of training data for machine translating programs. Both example-based and statistical machine translation rely on a vast array of real example sentences as a base for translation, and when too many or too few sentences are analyzed accuracy is jeopardized. Researchers found that when a program is trained on 203,529 sentence pairings, accuracy actually decreases.[48] The optimal level of training data seems to be just over 100,000 sentences, possibly because as training data increasing, the number of possible sentences increases, making it harder to find an exact translation match.
Using machine translation as a teaching tool[edit]

Слайд 15Using machine translation as a teaching tool
Although there have been concerns
about machine translation's accuracy, Dr. Ana Nino of the University of Manchester has researched some of the advantages in utilizing machine translation in the classroom. One such pedagogical method is called using "MT as a Bad Model."[55] MT as a Bad Model forces the language learner to identify inconsistencies or incorrect aspects of a translation; in turn, the individual will (hopefully) possess a better grasp of the language. Dr. Nino cites that this teaching tool was implemented in the late 1980s. At the end of various semesters, Dr. Nino was able to obtain survey results from students who had used MT as a Bad Model (as well as other models.) Overwhelmingly, students felt that they had observed improved comprehension, lexical retrieval, and increased confidence in their target language.[55]

Слайд 16Machine translation and signed languages
In the early 2000s, options for machine
translation between spoken and signed languages were severely limited. It was a common belief that deaf individuals could use traditional translators. However, stress, intonation, pitch, and timing are conveyed much differently in spoken languages compared to signed languages. Therefore, a deaf individual may misinterpret or become confused about the meaning of written text that is based on a spoken language.[56]
Researchers Zhao, et al. (2000), developed a prototype called TEAM (translation from English to ASL by machine) that completed English to American Sign Language (ASL) translations. The program would first analyze the syntactic, grammatical, and morphological aspects of the English text. Following this step, the program accessed a sign synthesizer, which acted as a dictionary for ASL. This synthesizer housed the process one must follow to complete ASL signs, as well as the meanings of these signs. Once the entire text is analyzed and the signs necessary to complete the translation are located in the synthesizer, a computer generated human appeared and would use ASL to sign the English text to the user.[56]
Researchers Zhao, et al. (2000), developed a prototype called TEAM (translation from English to ASL by machine) that completed English to American Sign Language (ASL) translations. The program would first analyze the syntactic, grammatical, and morphological aspects of the English text. Following this step, the program accessed a sign synthesizer, which acted as a dictionary for ASL. This synthesizer housed the process one must follow to complete ASL signs, as well as the meanings of these signs. Once the entire text is analyzed and the signs necessary to complete the translation are located in the synthesizer, a computer generated human appeared and would use ASL to sign the English text to the user.[56]






